本文揭示了大语言模型(LLM)生成“口头置信度”(Verbal Confidence)的底层机制,提出并证实了“缓存检索”(Cached Retrieval)假说。研究表明,Gemma 3 和 Qwen 2.5 等模型在生成答案时会自动计算并缓存置信度信号,随后在提示词要求输出分数时进行检索。
TL;DR
当你问大模型“你有多大把握”时,它并不是临时抱佛脚去翻书,而是在刚才给出答案的那一刻,心里就已经“存”好了分数。本文通过对 Gemma 3 和 Qwen 2.5 的深度“解剖”,证实了 LLM 存在一种**缓存检索(Cached Retrieval)**机制:模型在生成答案结束时的换行符处就已经自动计算并存储了置信度,而最后的数值输出只是对该缓存的读取。
背景定位:这是可解释性领域中关于模型“元认知”能力的里程碑工作。它证明了模型具备一种**二阶(Second-order)**评估能力,其置信度信号远比简单的 Token 概率要复杂。
痛点深挖:模型是在演戏还是真的知道?
目前获取模型置信度主要有两种方式:一是提取 Token 的 Log-probabilities(白盒),二是直接让模型说出百分比(口头置信度)。然而,黑盒模型往往只提供后者。
学界一直存在争议:模型说出的“我有 90% 把握”是为了迎合 Prompt 进行的事后编造(Post-hoc Reconstruction),还是基于内部状态的真实反映?如果是前者,口头置信度将毫无参考价值;如果是后者,我们就能通过干预模型内部状态来彻底解决“一本正经胡说八道”的问题。
核心方法论:寻找置信度的“物流链路”
作者提出了两个竞争假说:
- 即时计算 (JIT):模型读到“Confidence:”这个 Token 时,才重新回顾问题和答案,计算得分。
- 缓存检索 (Cached):模型生成答案时就顺便算好了,存在某个中间位置,等用到时再取。
为了验证,作者锁定了两个关键位置:
- PANL (Post-Answer-Newline):答案刚结束后的那个换行符。
- CC (Confidence-Colon):评分输出前的那个冒号。
1. 激活引导 (Activation Steering)
作者提取了“高置信度”和“低置信度”的向量方向,并将其注入模型。实验发现:
- 在 PANL 位置注入向量,能在极早的层级(21-25层)就显著改变模型最后报出的分数。
- 在 CC 位置注入,效果则出现在较晚的层级(30-35层)。 这说明置信度信号是先在 PANL 生成,后传递到 CC 的。
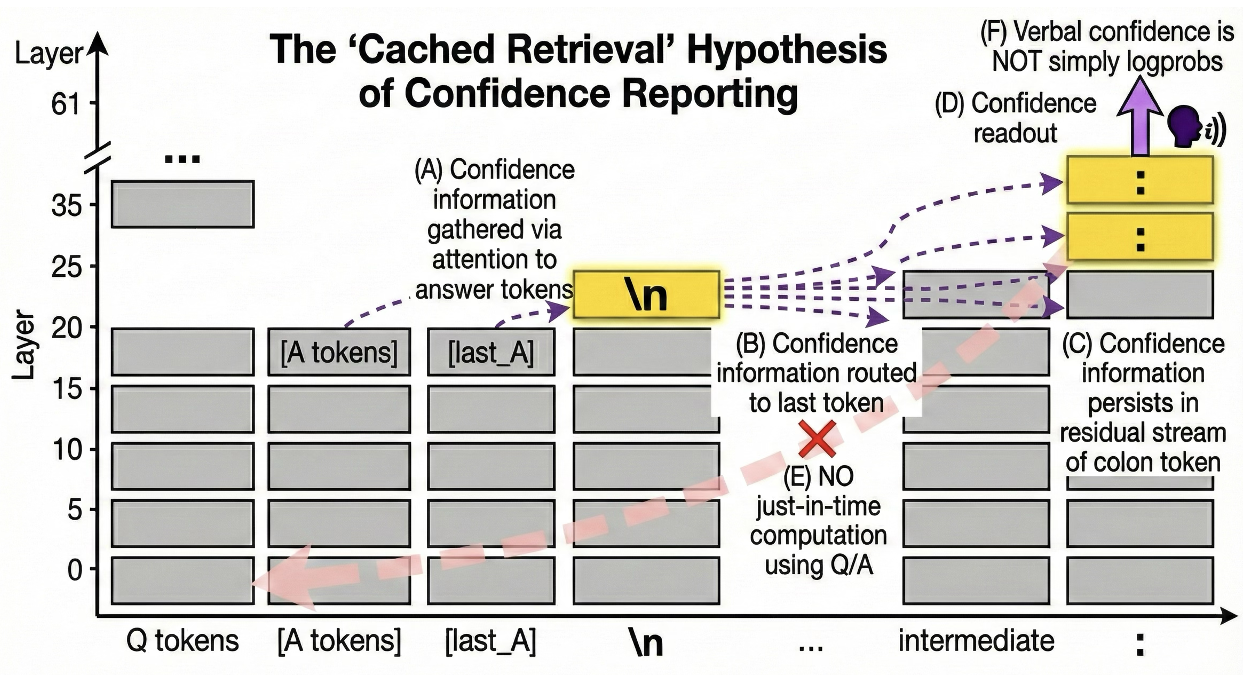 图 1:置信度信息流示意图。信息从答案 Token 汇聚到 PANL,再传递至 CC 进行口头化。
图 1:置信度信息流示意图。信息从答案 Token 汇聚到 PANL,再传递至 CC 进行口头化。
2. 注意力阻断 (Attention Blocking)
这是最硬核的证据。作者强行封锁了 CC 位置对“问题(Q)”和“答案(A)”的注意力:
- 如果模型是 JIT 计算,拿不到 Q 和 A 的信息,它肯定会乱猜。
- 结果:即使 CC 看不到问答内容,只要它能看到 PANL,它报出的分数依然准确无误! 这就彻底排除了即时计算的可能性。
实验与结果:超越概率的“深思熟虑”
研究最令人兴奋的发现是:这种内部缓存的置信度信号并不是 Token 概率(Logprobs)的复写。
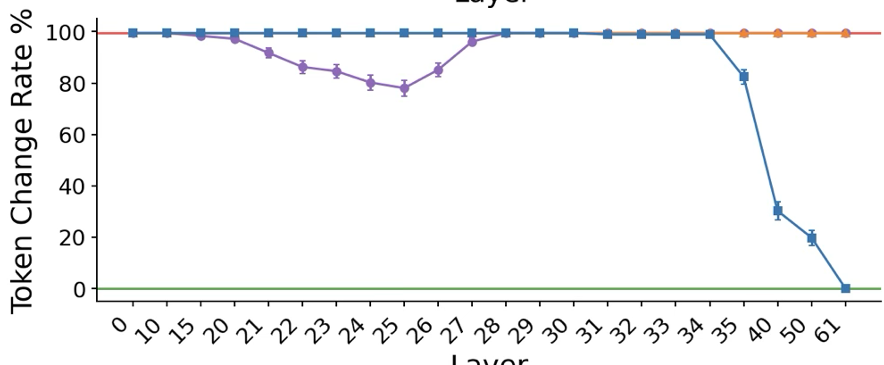 图 2:激活修补实验显示,修复 PANL 位置的表征能显著恢复被破坏的置信度输出。
图 2:激活修补实验显示,修复 PANL 位置的表征能显著恢复被破坏的置信度输出。
- 方差分解:线性探针(Linear Probe)分析显示,PANL 的激活能解释大量 Logprobs 无法涵盖的方差。
- 二阶模型:这符合神经科学中的“二阶置信度模型”——模型具备一套独立的监控电路,即使它输出了某个 Token,它内部可能已经意识到这个 Token 可能是错的(Error Detection)。
深度洞察:这对 AI 安全意味着什么?
Takeaway: 本文证明了 LLM 的“诚实”是有物理基础的。模型内部其实知道自己在写什么,也知道自己懂不懂。
- 局限性:虽然作者证明了信号的存在,但这种“缓存”是如何在训练中自发形成的(尤其是没有进行专门的 RLHF 标定前)仍是一个谜。
- 未来启示:既然我们知道了置信度存在于特定的“换行符”Token 中,未来的推理框架可以直接在这些位置插入监测模块。一旦监测到缓存的置信度低于阈值,直接触发模型重写或联网搜索,而不需要等待模型把整句话说完。
这种从“黑盒猜想”走向“白盒干预”的研究,正是通往可靠 AI 的必经之路。