本文提出了 Loc3R-VLM,这是一个旨在增强 2D 视觉语言模型(VLM)在单目视频输入下进行 3D 空间理解和情境感知能力的框架。通过引入全局布局重建(Global Layout Reconstruction)和显式情境建模(Situation Modeling),该模型在 SQA3D 语言定位任务中大幅刷新 SOTA,并在多项 3D 问答基准测试中超越了现有的视频及 3D 多模态大模型。
TL;DR
Loc3R-VLM 是一项突破性的工作,它证明了即使不给 AI 输入复杂的 3D 点云,仅凭普通的单目视频,只要通过精巧的空间监督(Spatial Supervision),就能让视觉语言模型(VLM)像人类一样建立起场景的“认知地图”。该模型在 SQA3D 语言定位任务中取得了碾压性的优势,位置精度相比前人工作提升了接近 40%。
核心痛点:为什么 VLM 总是“空间感”堪忧?
尽管 GPT-4o 或 Gemini 1.5 Pro 在描述图片内容上已经炉火纯青,但一旦涉及“我在哪”、“某物在我左后方多少米”这种**视角敏感(Viewpoint-aware)**的空间推理,它们就会显得力不从心。
- 缺乏局部到全局的映射:视频模型往往只关注局部帧,难以在脑中拼凑出完整的 3D 场景全貌。
- 度量尺度缺失:2D 像素缺乏深度信息,模型很难感知真实的物理距离(公制单位)。
- 缺乏“自我中心”定位:模型不知道自己处于场景的什么位置,因此无法进行准确的视角转换。
关键直觉:模拟人类的“认知地图”
Loc3R-VLM 的核心 Insight 在于:与其强行喂给模型复杂的 3D 数据,不如教模型如何从 2D 序列中“脑补”出 3D 结构。 作者设计了两个并行任务:
- BEV(Bird’s-Eye-View)布局重建:强制模型将看到的每一个视觉 Patch 映射到二维的鸟瞰地图上。
- 情境建模(Situation Modeling):通过特殊的 Token 预测智能体当前的坐标和旋转角度。
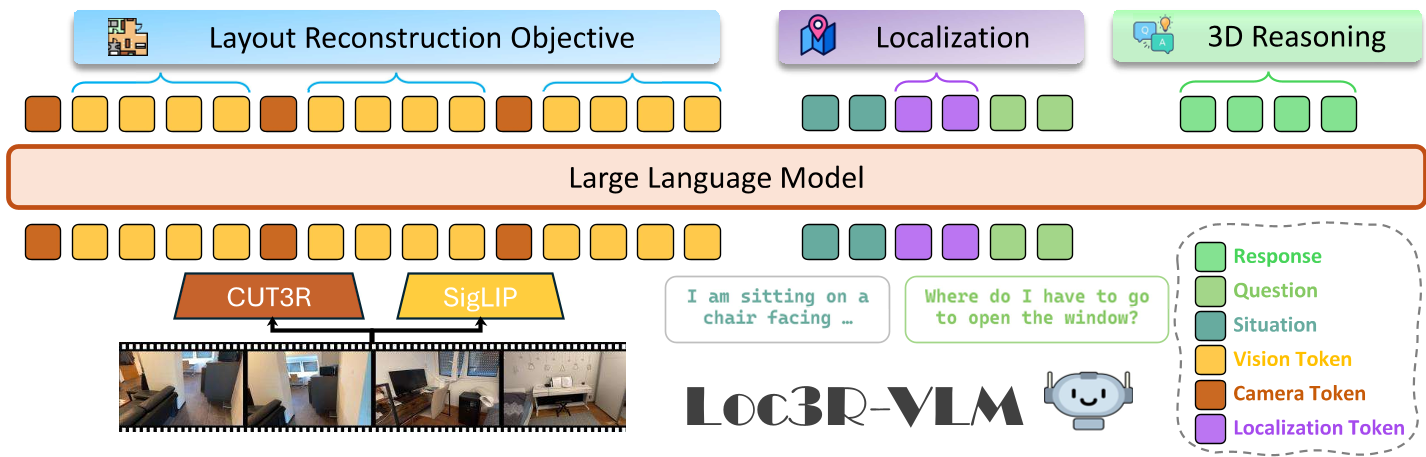 图 1:Loc3R-VLM 架构。通过将相机位姿先验融入视觉序列,并利用专门的 Head 进行 BEV 地图和位姿预测,模型实现了语言与空间的深度对齐。
图 1:Loc3R-VLM 架构。通过将相机位姿先验融入视觉序列,并利用专门的 Head 进行 BEV 地图和位姿预测,模型实现了语言与空间的深度对齐。
方法论:三板斧解决 3D 难题
1. 引入 3D 基础模型先验
模型并不从零学习位姿,而是借鉴了 CUT3R(一种 3D 基础模型)的相机隐含表征。这就像是给 AI 装了一个轻量级的“内置指南针和皮尺”,提供了极其重要的度量尺度线索。
2. 全局布局重建 (Global Layout Reconstruction)
这是一个天才的辅助任务。模型需要预测视觉 Token 在 BEV 平面上的 [x, y] 坐标及其不确定性。这迫使 Transformer 的隐藏层必须编码场景的全局拓扑结构。
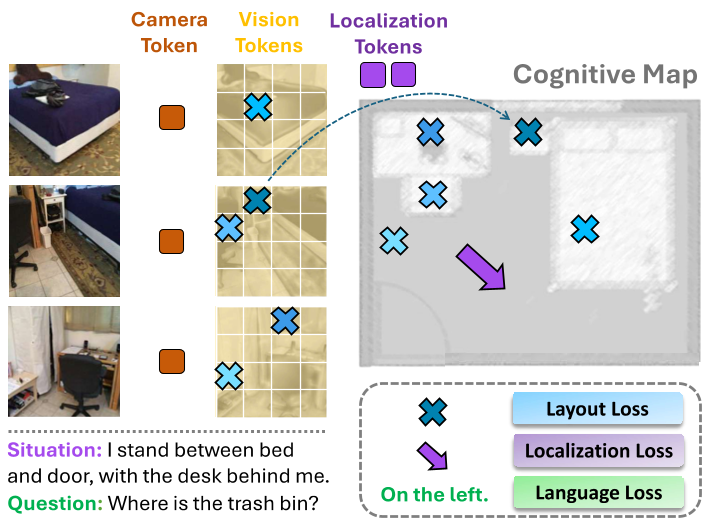 图 2:全局布局重建过程。模型将离散的视频帧特征统一到重心对齐的世界坐标系中,形成类似于人类“认知地图”的表征。
图 2:全局布局重建过程。模型将离散的视频帧特征统一到重心对齐的世界坐标系中,形成类似于人类“认知地图”的表征。
3. 显式情境建模
作者在文本序列中插入了 <Pos> 和 <Ori> Token。在经过大语言模型(LLM)处理后,这两个 Token 的输出向量会被解码为具体的物理坐标和朝向角度。这赋予了模型“我在哪”的直观感觉。
实验战绩:全场最佳 (State-of-the-art)
实验结果证明,Loc3R-VLM 在需要 3D 意识的任务中展现了统治力:
- 语言定位精度:在 SQA3D 任务上,Acc@1.0m 达到了惊人的 75.9%,而之前最强的 3D 原生模型 View2Cap 仅为 36.9%。
- 视角相关问答:在 VSI-Bench 的“相对方向”和“路径规划”任务中,相比 GPT-4o 等超大规模模型,Loc3R-VLM 的领先优势最高达到了 40% 以上。
 表 1:SQA3D 定位性能对比。可以看到,Loc3R-VLM 作为 2D-based 方法,全面超越了所有需要 explicit 3D 点云输入的方法。
表 1:SQA3D 定位性能对比。可以看到,Loc3R-VLM 作为 2D-based 方法,全面超越了所有需要 explicit 3D 点云输入的方法。
深度洞察:为什么 2D 模型能赢过 3D 模型?
这是一个非常值得学术界思考的问题。过去我们认为 3D 理解必须依赖点云。但 Loc3R-VLM 告诉我们:
- 2D 预训练的强大:现有的 2D VLM 已经见证了海量图像,其语义理解能力远超点云模型。
- 监督比输入更重要:正确定义“重建布局”和“自我定位”这类监督信号,比给模型喂原始 3D 数据更能引导其学习到有用的 Inductive Bias。
总结与启示
Loc3R-VLM 的出现预示着一个新趋势:未来具身智能(Embodied AI)可能不再需要笨重且昂贵的 3D 传感器。只要有普通的摄像头,再加上一个具备“空间常识”和“自我意识”的 VLM,机器人就能在复杂的室内环境中自如导航并理解人类的复杂指令。
局限性:目前的 BEV 表征虽然高效,但丢失了高度方向上的细节(如两层别墅的结构)。如何在保持效率的同时引入垂直维度的感知,将是 Loc3R 下一步进化的方向。