本文推出了 LVOmniBench,这是首个专门针对全模态大语言模型(OmniLLMs)长时音频-视频跨模态理解能力的深度评测基准。该基准包含 275 个长视频(10-90 分钟)和 1,014 个经过专家严格标注的 QA 对,目前最强的 Gemini 3 Pro 仅达到 65.8% 的准确率,而开源模型普遍低于 35%。
TL;DR
随着 GPT-4o 和 Gemini 系列的发布,全模态大模型(OmniLLMs)展现了惊人的视听能力。然而,LVOmniBench 的出现给这个领域浇了一盆冷水。该基准聚焦于 10-90 分钟 的超长音视频理解,实验显示即便最先进的模型在面对复杂的长跨模态推理时依然举步维艰。开源模型在长时任务下几乎处于“半盲半聋”状态,表现仅略高于随机。
1. 痛点:短平快的评测已到上限
目前的音视频 benchmark(如 AVQA, Music-AVQA)大多处理的是 10 秒到 1 分钟的极短片段。在实际应用场景(如电影分析、长教程学习)中,视频往往长达数十分钟。
- 信息稀疏性:在 1 小时的视频里寻找 5 秒钟的关键音频极其困难。
- 模态错位:很多现有 benchmark 存在“文本快捷方式”,即便不看视频只读题目也能猜对。
- 长时记忆挑战:模型能否在处理了 2000 个视觉 Token 后,依然记得 10 分钟前的一段背景音乐?
2. LVOmniBench:真正“长”且“难”的考卷
LVOmniBench 的核心竞争力在于其严格的人工筛选与多维度评判标准:
- 规模:275 个视频,总计 140 小时,平均长度比之前基准高出 6 倍以上。
- 任务分级:从基础的计数、属性感知,到高阶的逻辑演化推理。
- 强制跨模态:所有题目设计都遵循一个原则——只看视频或只听音频必然无法答对。
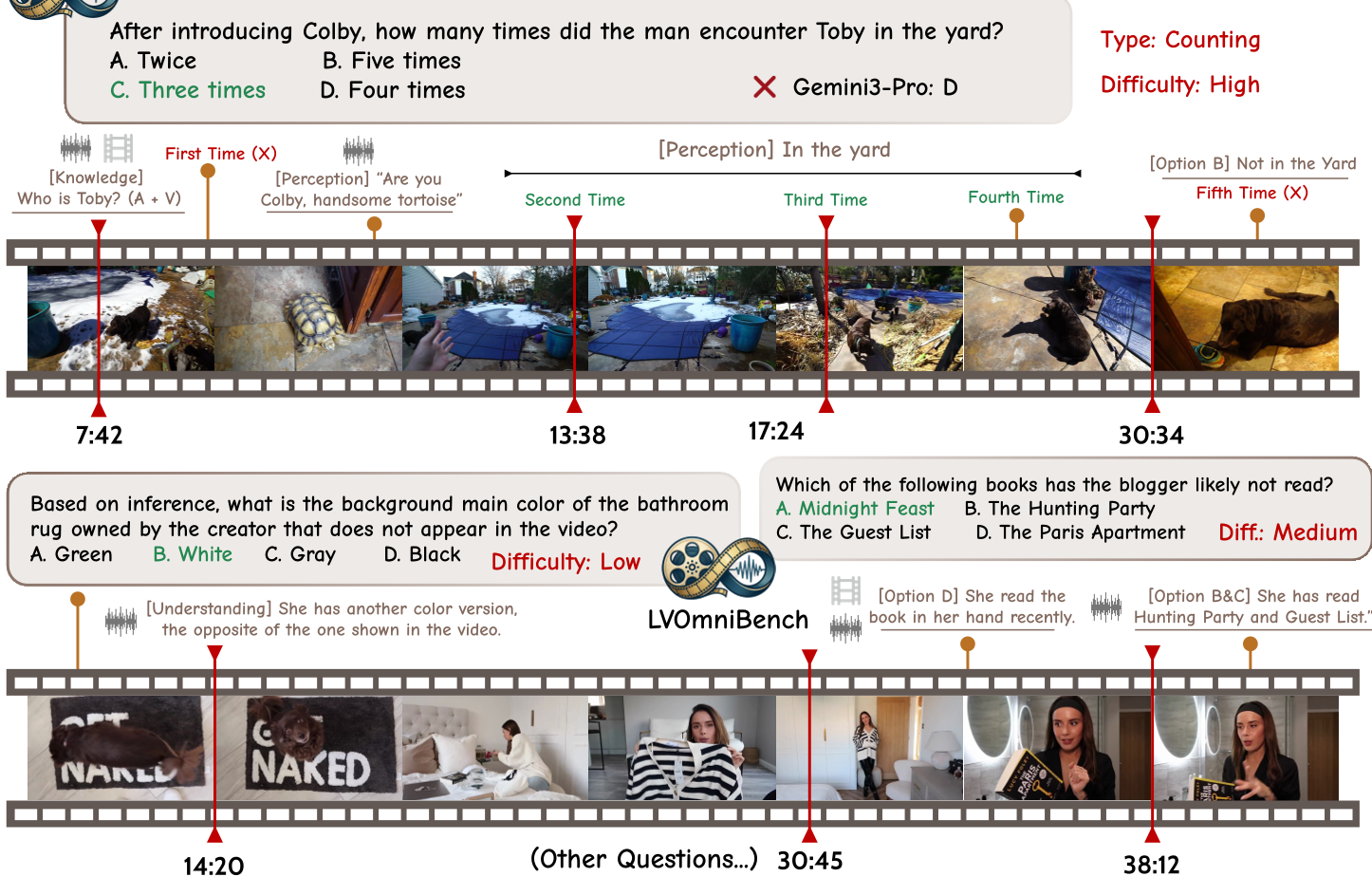 图1:LVOmniBench 根据难度划分的三个任务范式,展示了模型在处理长时音视频时的巨大挑战。
图1:LVOmniBench 根据难度划分的三个任务范式,展示了模型在处理长时音视频时的巨大挑战。
3. 核心发现:开源与闭源的鸿沟
研究团队对一众主流模型进行了严苛的“压力测试”,结果令人深思:
| 模型分类 | 代表模型 | LVOmniBench 平均准确率 | | :--- | :--- | :--- | | 闭源最强 | Gemini 3 Pro | 65.8% | | 闭源次强 | Gemini 3 Flash | 59.0% | | 开源领先 | Qwen3-Omni-30B | 35.8% | | 开源底座 | VideoLLaMA2-7B | 27.2% |
关键洞察:
- 闭源模型的统治地位:Gemini 系列在长时上下文处理和音视频对齐上的积累使其处于“独走”状态,尤其是 Gemini 3 Pro 在高难度任务下依然能保持 45% 的精度。
- 音频是开源模型的阿喀琉斯之踵:研究发现,开源模型很难直接从长音频流中提取有效特征。
- 实验证据:当把音频转录成 ASR 文本(Subtitle)喂给模型后,Qwen3-Omni 的表现提升了 7.7%。这说明开源模型目前的原始音频处理能力还不如它们的文本处理能力。
- 非言语信息丢失:所有模型在处理“音乐感知”和“抽象声响”时均表现极差,这说明目前的感知编码器(Perceptual Encoder)在非语言维度的语义提取上存在严重短板。
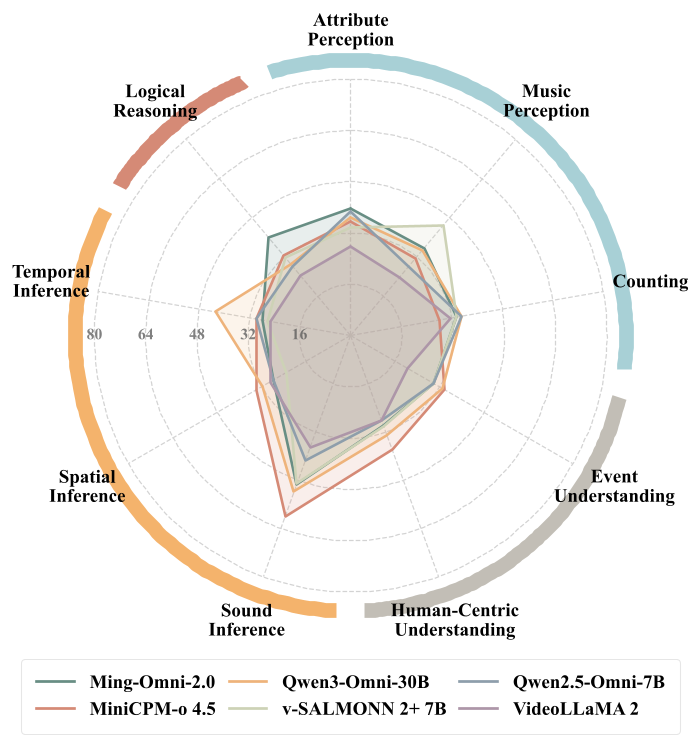 图2:闭源模型与开源模型在各维度的性能对比。蓝色代表感知,红色代表逻辑,可见开源模型在计数和音乐感知等亚任务上几乎溃败。
图2:闭源模型与开源模型在各维度的性能对比。蓝色代表感知,红色代表逻辑,可见开源模型在计数和音乐感知等亚任务上几乎溃败。
4. 深度诊断:为什么会出错?
通过对 Gemini 3 Flash 的 153 个错误样本进行人工分析,作者总结了四类主要失败模式:
- 感知错误 (34%):无法区分精细的声学属性(如声调高低、物体具体数量)。
- 推理错误 (23.5%):感知到了信号,但无法理解因果链条。
- 时序定位错误 (19.6%):在长达 40 分钟的视频中找错位置。
- 跨模态语义鸿沟 (19%):音视频信号在模型内部处于“独居”状态,无法有效融合。
5. 资深主编点评
LVOmniBench 的发布标志着 OmniLLMs 评测从“实验室场景”迈向“真实生产场景”。它不仅仅是一个数据集,更是一份针对当前多模态架构的体检报告。
其未来启示在于:
- 音频不仅仅是转写:依赖 ASR 会丢失情感、旋律和背景环境音,未来的感知层需要更强的
Raw Audio表征能力。 - Token 压缩是刚需:处理 90 分钟视频产生的 KV Cache 是天文数字。
- 时序定位是核心:具备“边看边定位”能力的交互式架构(如 Agentic Video Understanding)或许是通向长视频理解的唯一路径。
这款 Benchmark 将促使研究界停止单纯在短片段上卷精度,转向对超长序列模态对齐的本质思考。