本文提出了 LoST,一种针对 3D 形状的语义级层级化分词(Tokenization)方法。该方法通过 Relational Inter-Distance Alignment (RIDA) 损失函数,将 3D 形状的潜在空间与 DINO 语义特征空间对齐,实现了仅需 128 个 Token 即可达成 SOTA 级别的 3D 重建与自回归生成。
TL;DR
在 3D 生成领域,自回归(AR)模型正在挑战扩散模型的主导地位,但 3D 数据的分词(Tokenization)一直是痛点。传统的几何层级方法(如 OctGPT)在 Token 较少时只能生成“骨架”。本文提出的 LoST (Level of Semantics Tokenization) 彻底颠覆了这一逻辑:它让 3D 编码按语义重要性排序。这意味着,哪怕只给模型 1 个 Token,它也能“脑补”出一个完整且符合语义的 3D 形状,而后续 Token 只是负责把形状修饰得更具体。
痛点深挖:为什么 3D 几何层级(LoD)不适合 AI 生成?
长期以来,3D 领域依赖几何 LoD(如八叉树 Octree 或渐进式网格 Progressive Meshes)来处理多尺度数据。这些方法的设计初衷是渲染与压缩:先给个粗糙的低模,再慢慢加面。
然而,对于大语言模型(LLM)风格的自回归生成来说,这种方式存在两个致命伤:
- Token 膨胀:为了描述基本的几何轮廓,早期层级往往就需要成千上万个 Token,导致算力浪费。
- 早期解码不可用:如果你在序列还没生成完时强制解码,几何 LoD 往往只能吐出一堆无意义的点云或方块,完全看不出是什么。
 图 1:LoST 与空间层级基线的对比。LoST 在极少 Token 下即可生成完整语义形状。
图 1:LoST 与空间层级基线的对比。LoST 在极少 Token 下即可生成完整语义形状。
方法论详解:从几何导向转向语义导向
1. 核心架构:Register Tokens 与嵌套丢弃
LoST 并没有直接对三平面(Triplane)特征进行简单打碎,而是引入了一组可学习的 Register Tokens。
- 原理:通过 ViT 编码器,让这些寄存器 Token 去“观察”整个 3D 三平面,并使用 Causal Masking(因果掩码) 和 Nested Dropout(嵌套丢弃) 强制模型执行:第一号 Token 必须承载最核心的类别信息,最后一号 Token 承载细节。
2. RIDA:解决 3D 语义对齐的“杀手锏”
如何在训练中告诉模型“什么是重要的语义”?在 2D 图像中我们可以通过 DINO 特征对齐(REPA),但在 3D 中直接渲染并对齐 2D DINO 功能的计算开销巨大。
作者提出了 RIDA (Relational Inter-Distance Alignment) 损失函数。其核心直觉是:不追求特征数值的绝对相等,而追求空间关系的拓扑一致。
- 逻辑:如果在 DINO 空间里,“折叠椅”和“办公椅”距离很近,那么在 LoST 的 3D 潜在空间里,它们的特征距离也必须很近。通过 RIDA,LoST 成功将 2D 视觉基础模型的语义常识“蒸馏”到了 3D 空间。
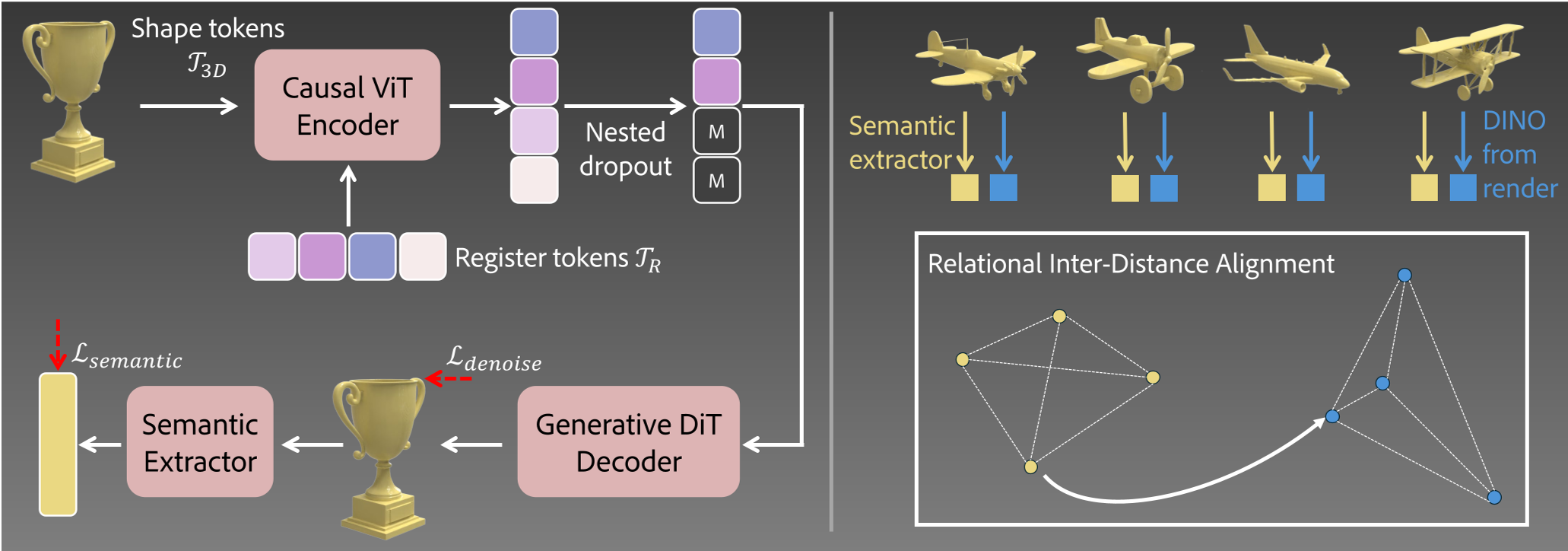 图 2:LoST 总体流程,右侧为关键的 RIDA 语义提取器预训练流程。
图 2:LoST 总体流程,右侧为关键的 RIDA 语义提取器预训练流程。
实验与结果:百倍效率,SOTA 性能
1. Token 效率对比
LoST 展示了惊人的压缩比。在 3D 重建中,它只需使用 16-64 个 Token,就在 CD(倒角距离) 和 FID(生成质量) 上击败了手动设计几万甚至几十万 Token 的 OctGPT。
2. 自回归生成的质量
在自回归模型(LoST-GPT)的实验中,即使面对复杂的物体,LoST 仅用 128 个 Token 就刷新了 SOTA。这意味着它的推理速度比以往的方法快了几个数量级,且能够实现“早停自回归”——如果前 16 个 Token 已经生成了理想的形状,生成过程可以提前结束。
 表 1:LoST 在不同 Token 长度下的表现,显著优于 OctGPT 和 VertexRegen。
表 1:LoST 在不同 Token 长度下的表现,显著优于 OctGPT 和 VertexRegen。
深度洞察:为什么这很重要?
LoST 的成功证明了:生成模型的 Token 序列不需要遵循物理空间或几何拓扑,而是应该遵循人类常识中的语义拓扑。
这一进步为 3D 领域的“大模型化”扫清了障碍:
- 下游任务潜力:由于 Token 具有语义含义,LoST 的特征可以直接用于 3D 形状检索(如查找所有“鱼形”潜水艇),且效果优于原始三平面特征。
- 任意长度解码:这让 3D 生成具备了真正的层级可控性,用户可以先看语义粗胚,再决定是否继续消耗算力生成精细模型。
局限性与展望
尽管 LoST 表现优异,但它目前依赖于三平面(Triplane)这种隐式表示,能否将其扩展到 3D 高斯泼溅(Gaussian Splatting)等显式表示仍需探索。此外,极低 Token 模式下的拓扑一致性(如保证桌子一定是四条腿)仍有提升空间。
总结 (Takeaway):LoST 重新定义了 3D 物体的“语言”。在这种新语言下,每一个 Token 都充满了信息,让 3D 创作变得像写文章一样高效且优雅。