本文提出了 MagicSeg,一种基于扩散模型自动生成数据集的开放世界语义分割预训练方法。该方法通过 LLM 生成复杂文本驱动图像生成,并引入反事实样本与分类随机采样策略,在 PASCAL VOC、COCO 等数据集上取得了 SOTA 性能。
TL;DR
传统的开放世界语义分割(Open-World Segmentation)一直受困于“有图无标”的窘境。MagicSeg 另辟蹊径,构建了一个全自动化数据工厂:用 ChatGPT 写剧本,用 Stable Diffusion 画图,再用专家模型自动打标签。它最高明的一点是引入了反事实(Counterfactual)样本——即生成一张“除了没有目标物体,其他细节完全一样”的背景图,通过对比学习让模型在没有完美标签的情况下也能精准定位目标。
核心速览
- 定位:这篇论文是合成数据驱动视觉感知的代表作,旨在解决大规模、细粒度像素级标注缺失的问题。
- 战绩:在不依赖手动标注的前提下,PASCAL VOC 达到 62.9% mIoU,并在 COCO 上显著超越同期的 Open-Vocabulary 方法。
痛点深挖:为什么 Open-World Segmentation 这么难?
目前的 Vision-Language Models (如 CLIP) 虽然有极强的零样本识别能力,但由于缺乏像素级(Pixel-level)的对齐,在处理“哪里是什么”时显得力不从心。
- 标注昂贵:手动标注数千个类别的掩码几乎是不可能的任务。
- 合成噪声:以前的方法靠 Diffusion 模型的 Cross-Attention 图来反推掩码,但这种掩码边界极其模糊且噪声大。
- 类别失衡:当词汇表扩展到上千类时,一张图里只有 1-2 类,训练时的正负样本梯度会极度失衡。
Methodology:MagicSeg 的炼金术
1. 文本驱动的多样化生成
作者不单纯使用“一张猫的照片”这种简单的 Prompt,而是利用 ChatGPT 生成具有丰富背景和动作描述的短文。这保证了生成的图像具有复杂的 Inductive Bias,对下游分割任务至关重要。
2. 反事实图像对 (Counterfactual Pairs)
这是 MagicSeg 的灵魂所在。对于每一个生成的样本,作者都会生成一个对照组:
- 正样本:
In a park, a playful dog is chasing a ball. - 反事实样本:
In a park, a playful nothing is chasing a ball.
通过这组配对,模型可以进行自监督学习——通过对比两张图特征的差异,模型能够自主学习到“狗”所在的局部空间,而无需完全依赖可能存在误差的自动掩码。
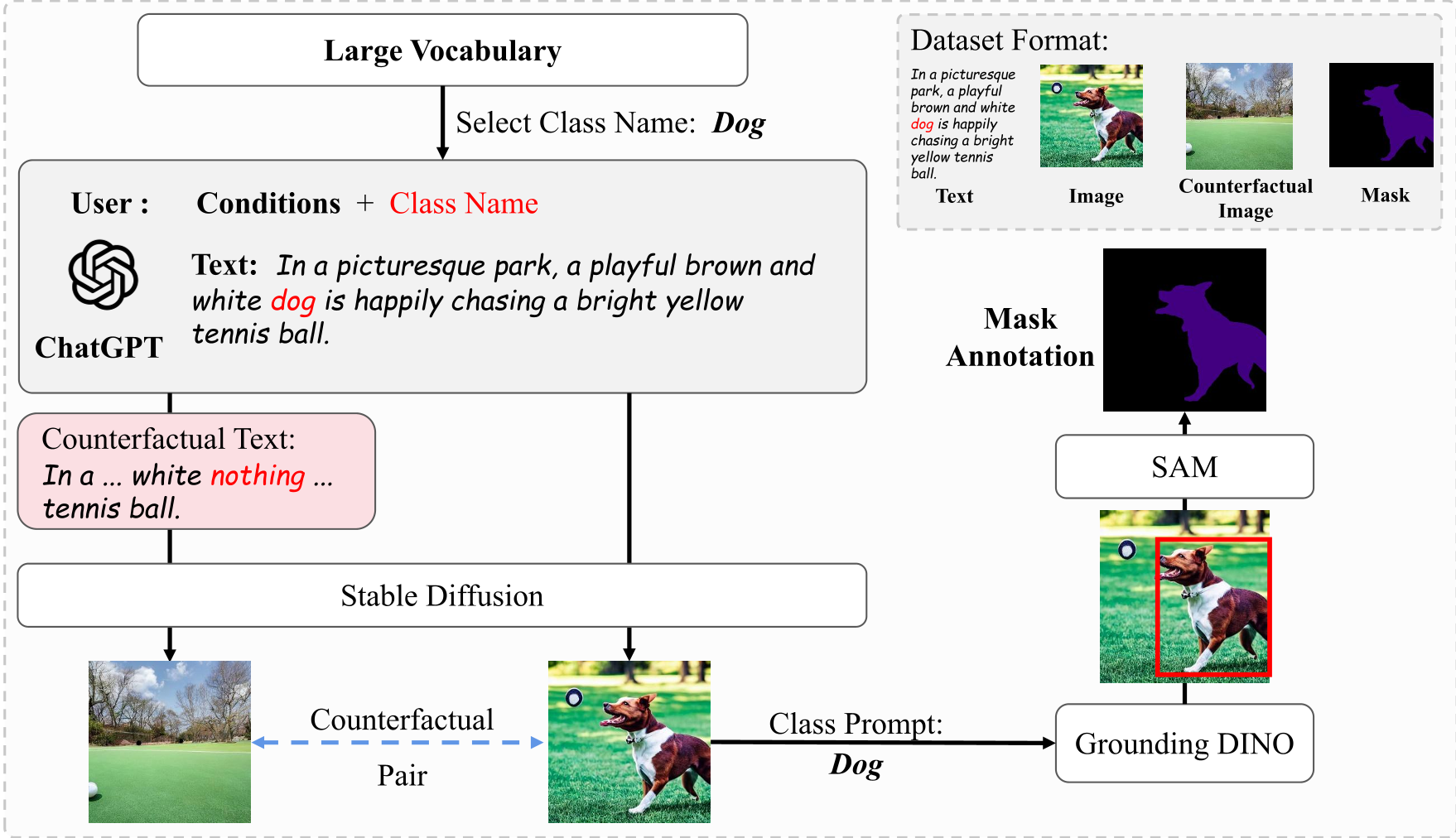
3. 分类随机采样策略 (Category Random Sampling)
面对 1205 个类别的大词汇表,如果每张图都预测全量类别,计算量爆炸且难以收敛。MagicSeg 在训练时,对于每张图,除了包含图像中存在的真实类别 C,还会随机挖掘一部分不存在的类别。这种 Dropout 式的采样不仅缓解了计算负担,还防止了模型对特定词汇表的过拟合。
实验与结果:合成数据真的能打吗?
MagicSeg 使用了 38 万对合成数据进行预训练。实验结果显示,即使在面对全新的 LVIS 开发集(包含 1200+ 类别)时,其表现也优于直接使用 Grounded SAM 的零样本基线。

- 可视化进步:相比于之前的冠军模型 GroupViT,MagicSeg 生成的掩码边缘更加平滑,尤其是对小物体和多物体共存的场景处理得更为细腻。

深度洞察与总结
Takeaway: MagicSeg 成功的关键在于它没有“迷信”生成模型的 Cross-Attention 来做分割,而是把 Diffusion 模型仅仅当作高质量图片的廉价来源,转而利用成熟的检测器(Grounding DINO)和分割器(SAM)来提取标签。同时,它引入的反事实学习极其精彩,通过生成侧的控制解决了判别侧的偏置问题。
局限性: 尽管目前表现优异,但其性能上限仍受限于 Stable Diffusion 生成图片的质量(如手部畸形、遮挡逻辑等)。未来如果能结合更强的生成底座(如 Sora 或 SD3),该 Pipeline 的潜力将不可限量。