本文推出了 Mamba-3,一种旨在提升大语言模型推理效率与表达能力的改进型状态空间模型(SSM)。通过引入指数梯形离散化、复数值状态更新以及多输入多输出(MIMO)架构,Mamba-3 在 1.5B 规模下比前代及同类模型平均准确率提升 1.8%,并显著增强了状态追踪能力。
TL;DR
在大型语言模型效率竞赛中,Mamba 系列代表的状态空间模型(SSM)一直是 Transformer 的强力竞争者。然而,Mamba-2 为了训练效率牺牲了部分表达力,且在处理特定逻辑任务(如状态追踪)时力不从心。Mamba-3 正是为了校准这一偏差而生:它通过二阶指数梯形离散化、复数值状态更新(映射为数据依赖的 RoPE)以及MIMO 机制,在 1.5B 尺度上刷新了亚二次方模型的 SOTA 纪录,同时解决了推理时的硬件闲置问题。
1. 动机:当线性模型遇到“能力墙”与“硬件墙”
尽管 Mamba 系列在长文本处理效率上表现卓越,但资深 AI 研究者们发现,这类模型在处理一些看似简单的逻辑任务(如 Parity 奇偶校验、复杂状态追踪)时,表现竟然不如一层简单的 LSTM。
究其根源,现有的线性递归模型(Linear RNN/SSM)大多将状态转移矩阵 $A$ 限制在非负实数范围内。这在数学上意味着系统只能“衰减”而不能“旋转”,导致其无法表征周期性或交换性的逻辑结构。此外,在 H100 等计算卡上进行生成时,传统的单输入单输出(SISO)递归极其依赖内存带宽(Memory-bound),导致算力被大量浪费。
2. 核心技术详解
2.1 指数梯形离散化 (Exponential-Trapezoidal Discretization)
传统的 Mamba-1/2 使用的是类似“向前欧拉”或启发式的离散化方法,其误差项为 $O(\Delta_t^2)$。Mamba-3 推导出了指数梯形法,将精度提升至二阶 $O(\Delta_t^3)$。
更有趣的物理直觉是,这种新离散化在形式上等价于在 SSM 内部引入了一个长度为 2 的隐式卷积。这种设计让模型即便去掉外部显式的卷积层,依然能保持极佳的性能。
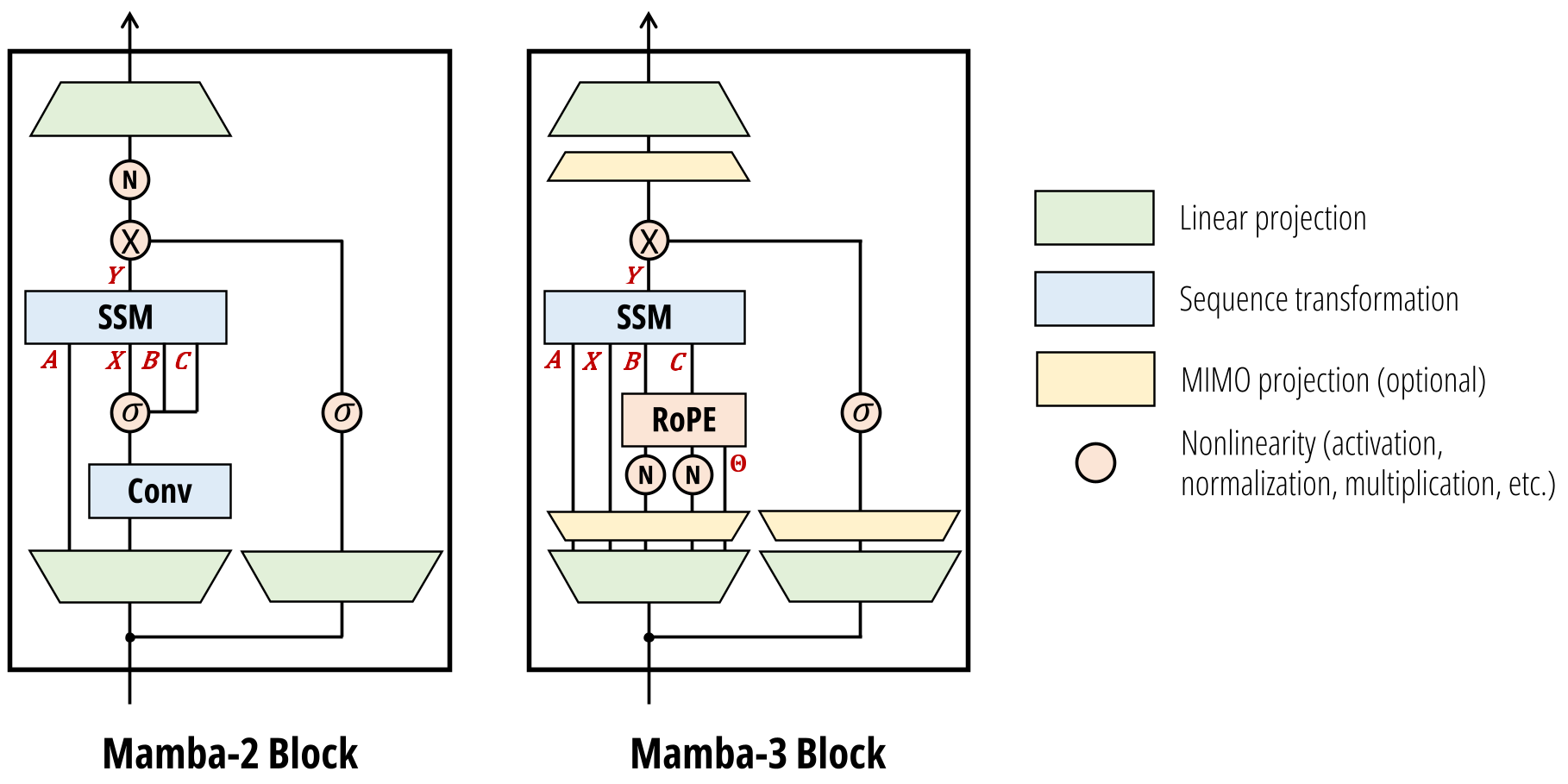 图 1: Mamba-2 与 Mamba-3 的架构对比。注意 Mamba-3 引入了 BC Bias 和数据依赖的 RoPE。
图 1: Mamba-2 与 Mamba-3 的架构对比。注意 Mamba-3 引入了 BC Bias 和数据依赖的 RoPE。
2.2 复数域与“RoPE Trick”的理论回归
为了让模型具备旋转动态,Mamba-3 将状态空间扩展到了复数域。作者在数学上证明了一个优美的结论:离散化的复数 SSM 等价于对 B/C(即 Linear Attention 中的 Key/Query)应用数据依赖的旋转位置编码(RoPE)。
这意味着,我们不需要直接在复数域进行繁重的计算,通过“RoPE Trick”,Mamba-3 就能获得解决状态追踪任务所需的数学属性,几乎没有推理开销。
2.3 MIMO:让计算不再等待内存
为了解决硬件利用率低的问题,Mamba-3 从单输入单输出(SISO)走向了多输入多输出(MIMO)。
- 原理:将传统的向量-$A$ 标量更新,改造成基于矩阵乘法的状态更新。
- 直觉:在解码时,读取隐藏状态 $h$ 的内存开销巨大,MIMO 通过在单词读取周期内塞入更多秩(Rank $R$)的操作,增加了计算强度。结果就是,你在同样的生成时间内,得到了一个 FLOPs 更高、表征能力更强的模型。
3. 实验战绩与 SOTA 对比
在 100B FineWeb-Edu 数据集的预训练测评中,Mamba-3 展现了统治级的帕累托前沿。
- 性能跨越:1.5B 规模下,Mamba-3 SISO 变体已经超过了最新的 Gated DeltaNet (GDN)。而开启 MIMO 模式后,其平均准确率高达 57.6%,远超同规模 Transformer(55.4%)。
- 奇偶校验任务:原本在实数 SSM 下无法解决的 Parity 任务,在 Mamba-3 面前达到了 100% 的准确率。
 表 1: 在各尺度下游任务上的量化对比。Mamba-3 在所有指标上均优于前代。
表 1: 在各尺度下游任务上的量化对比。Mamba-3 在所有指标上均优于前代。
4. 局限性与深度洞察
尽管 Mamba-3 在短文和下游任务上表现强劲,但在纯粹的检索任务(如大规模 Needle-in-a-Haystack)中,受限于固定大小的状态瓶颈,仍然无法直接与无限 KV-Cache 的 Transformer 媲美。作者建议通过混合架构(Hybrid)——即穿插少量 Attention 层——来彻底解决这一问题。
5. 总结
Mamba-3 给我们的启示是:不要仅仅为了高效而简化数学模型。通过回归控制理论的深水区,利用高阶离散化和复数动力学,我们可以在不牺牲效率的前提下,找回被简化的“表达能力”。对于未来的端侧 AI 和实时智能体而言,Mamba-3 这种推理优先、硬件友好的设计路径极具参考价值。