《深度学习的数学基础》系统性地阐述了深度神经网络(DNN)的理论框架,涵盖了逼近论、优化算法、最优控制及生成模型。该工作通过数学严谨性统一了深度学习的核心组件,建立了从 Universal Approximation Theorem 到现代 Diffusion Models 的理论桥梁。
TL;DR
本文是对深度学习数学机理的深度拆解。它不仅回答了神经网络“为什么能逼近一切”,更将深度学习的训练过程建模为一个最优控制问题。通过将残差网络、扩散模型、强化学习统一在 Hamiltonian 动力学框架下,作者为我们揭示了 AI 模型从海量数据中提取结构的本质物理直觉。
1. 理论起点:为什么网络能逼近一切?
深度学习的第一推动力是 Universal Approximation Theorem。论文不仅复述了网络可以逼近任何连续函数,更给出了一个硬核的定量结论:对于属于 Sobolev 空间的 $k$ 阶光滑函数,使用深层 ReLU 网络达到 $\epsilon$ 误差所需的权重数量级为 $O(\epsilon^{-d/k})$。
核心直觉:深层网络通过对输入的不断分段线性仿射变换,在空间中折叠出极其复杂的曲面。这种“空间折叠”的能力正是深度优于浅层的几何本质。
2. 优化之美:从梯度下降到自适应流
在训练算法部分,作者对 Adam, AdamW 以及最新的 Muon 优化器进行了深入解剖。
(提示:此处需插入文中关于不同优化器路径收敛效果的对比图)
其核心洞察在于:
- 随机性(Stochasticity)的力量:随机梯度下降(SGD)不仅是为了省钱,其引入的噪声使得模型能够逃离局部极小值点。
- 正交化(Muon):最新的 Muon 优化器通过对权重矩阵进行 Newton-Schulz 迭代,保持权重的奇异值为 1,从而在训练极深架构时防止梯度消失或爆炸。
3. 最优控制视角:Neural ODE
论文中最具革命性的观点是将模型前向传播视为一个 Ordinary Differential Equation (ODE)。
$$ \dot{x}(t) = f(t, x(t), u(t)) $$
- 残差网络即欧拉解法:ResNet 的每一层实际上是在对一个连续动力系统进行步长为 1 的离散采样。
- 伴随状态法(Adjoint Method):通过求解伴随方程,我们可以在不存储中间层激活值的情况下计算梯度,这为显存受限的大模型训练提供了数学捷径。
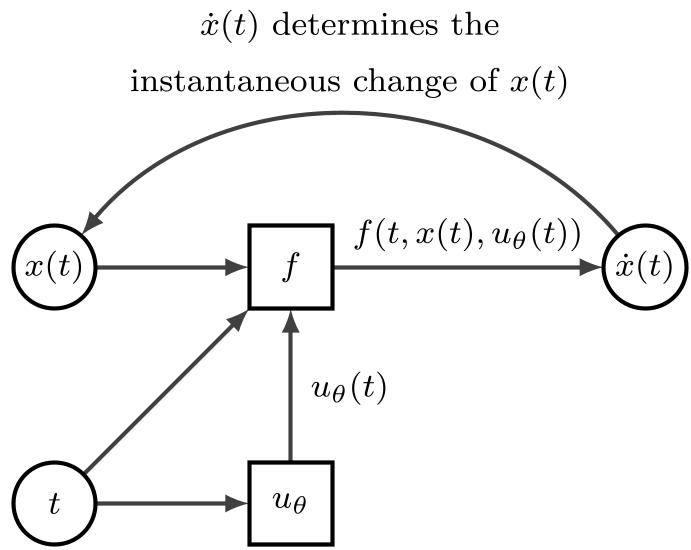 图:Neural ODE 将离散层转化为连续流的过程
图:Neural ODE 将离散层转化为连续流的过程
4. 生成模型新纪元:扩散与流匹配
在生成模型章节,作者详细对比了 VAE, GAN, Diffusion 和 Flow Matching。
- 扩散模型(Diffusion):本质上是学习如何逆转热力学中的熵增过程。通过得分匹配(Score Matching),模型学会了在噪声迷雾中寻找数据的概率梯度。
- 流匹配(Flow Matching):相比于 Diffusion 的随机路径,Flow Matching 寻求的是一条能量消耗最低的直线路径,将标准高斯分布直接推向数据分布,大幅提升了生成效率。
 图:Flow Matching 中各采样点的确定性轨迹
图:Flow Matching 中各采样点的确定性轨迹
5. 深度洞察:迈向物理知觉的 AI
论文最后讨论了 Physics-Informed Neural Networks (PINNs)。作者指出,通过将 PDE 算子(如 Laplacian)直接嵌入损失函数,神经网络可以学习物理定律本身。这预示着未来的生成式 AI 将不仅仅是像素的搬运工,而是懂得波动力学、流体力学的神经网络模拟器。
总结
深度学习不再仅仅是程序员的“点金术”,它正在通过动力系统和泛函分析找回自身的严密性。对于研究者来说,理解 Hamiltonian 动力学和得分函数,将是设计下一代高效架构(如连续 Transformer 或长窗口模型)的破局点。
本文由资深学术主编重构。原论文作者:Xiaojing Ye (2026).