本文提出了 Matryoshka Gaussian Splatting (MGS),一种针对 3D Gaussian Splatting (3DGS) 的连续细节层级 (Continuous LoD) 训练框架。通过学习一组有序的、嵌套的 Gaussian 原始体,MGS 实现了仅需截取模型前 k 个 Splats 即可在单个模型上获得从低功耗到高保真的平滑渲染切换。
TL;DR
传统的 3D Gaussian Splatting (3DGS) 往往面临“鱼和熊掌不可兼得”的困境:要么追求极致性能但缺乏多设备适配能力,要么引入细节层级 (LoD) 但牺牲了全容量下的渲染精度。Matryoshka Gaussian Splatting (MGS) 借鉴了“俄罗斯套娃”的嵌套思想,通过一种极简的随机预算训练方案,使单个 3DGS 模型在任意截断长度下都能输出高质量画面,首次实现了无损的连续 LoD 控制。
背景定位:渲染预算的“动态性”挑战
在实际部署中,3D 渲染环境极其复杂:
- 硬件异构性:从高性能 A100 服务器到低功耗 XR 头显。
- 运行时波动:视角变化或场景复杂度波动会导致渲染帧率不稳定。
传统的 3DGS 模型没有内置的原始体优先级,随机删除一部分 Splats 会导致画面立即“崩塌”。现有的 LoD 方案(如 H3DGS 或 Octree-GS)通常涉及复杂的树状结构或固定的多档位切换,不仅增加了显存负担,还容易产生视觉上的“弹出 (Pop-in)”伪影。
核心洞察:为什么要像“套娃”一样设计?
作者发现,如果能给 Gaussian 原始体建立一个有序序列,让前 $k$ 个原始体构成的“前缀”始终能代表场景的最重要结构,那么 LoD 问题就转化为了简单的数组截断问题。
1. 重要性打分 (Importance Scoring)
MGS 并不通过复杂的网络去预测权重,而是基于物理直觉:不透明度 (Opacity)。不透明度越高的 Gaussian,对最终像素颜色的贡献通常越大。
- 策略:按 Opacity 降序排列。
- 效果:前 5% 的 Gaussian 就能勾勒出场景的粗略轮廓,随数量增加,细节逐渐填充。
2. 随机预算训练 (Stochastic Budget Training)
这是本文最精妙的设计。在训练的每一个 Iteration:
- 生成一个随机比例 $r$(例如 $r=0.3$)。
- 计算对应的截断点 $k = \lceil rN \rceil$。
- 同时进行两次 Forward Pass:一次渲染前 $k$ 个,一次渲染全部 $N$ 个。
- 联合最小化损失函数:$\mathcal{L}{MGS} = \mathcal{L}{prefix} + \gamma \mathcal{L}_{full}$。
这种训练方式迫使模型在任何“前缀长度”下都要尽力还原真实场景。
 图 1:MGS 通过单一有序集合,实现了从 1% 到 100% 预算的平滑质量过渡
图 1:MGS 通过单一有序集合,实现了从 1% 到 100% 预算的平滑质量过渡
实验战绩:无损的高性能
MGS 在多个公开数据集上进行了严苛测试,结果令人印象深刻:
- 全量保真度:在 MipNeRF 360 数据集上,MGS 的 PSNR 达到了 28.20 dB,几乎追平了没有任何 LoD 约束的 3DGS-MCMC 基准。这意味着 LoD 能力现在是“免费”获得的。
- 极低预算表现:在仅使用 5%-10% 的 Splats 时,对比方法(如 CLoD-3DGS)的画质会跌至 11 dB(基本不可看),而 MGS 依然稳在 22 dB 以上,保持了场景的拓扑一致性。
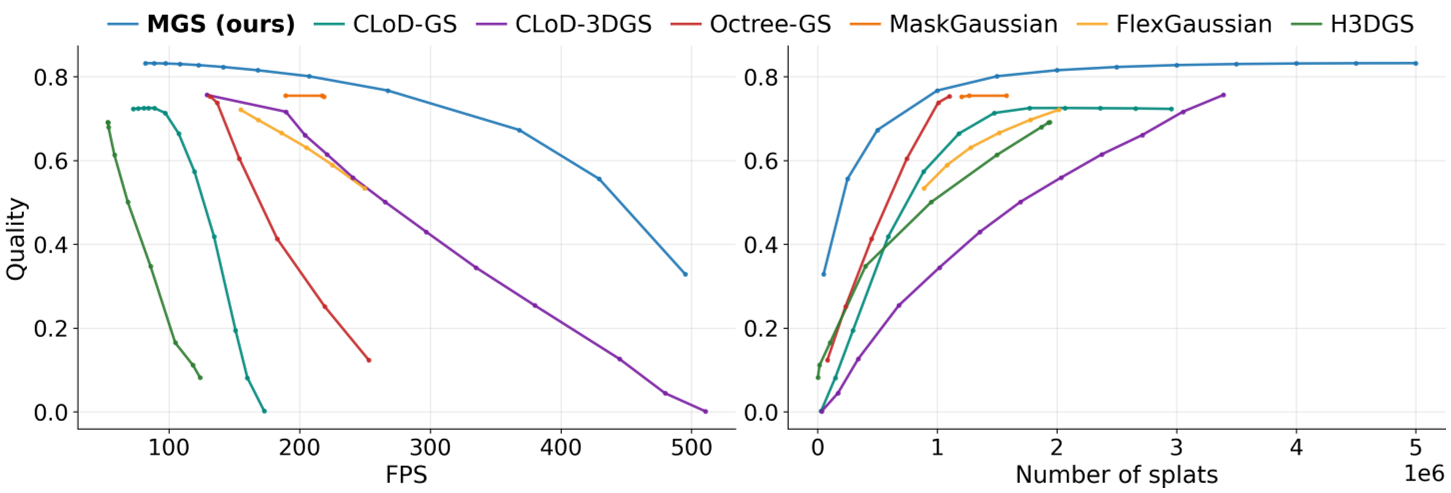 图 2:质量与 FPS/Splats 数量的权衡曲线(Pareto Frontier)。可见 MGS(红色实线)在所有预算区间内均处于最上方。
图 2:质量与 FPS/Splats 数量的权衡曲线(Pareto Frontier)。可见 MGS(红色实线)在所有预算区间内均处于最上方。
深度探讨:为什么它比前人更强?
- 无需辅助结构:相比 Octree-GS 等方法,MGS 不需要维护复杂的树结构,渲染器只需要改变循环的终止索引。
- 训练正则化效应:有趣的是,在某些数据集(如 Deep Blending)上,MGS 的表现甚至优于原版模型。这说明“随机预算”这种类似 Dropout 的训练方式,有效防止了模型过度拟合某些冗余的 Gaussian 原始体。
总结与启示
MGS 的成功标志着 3D 渲染正从“静态表示”向“弹性表示”演进。它通过将不透明度排序与随机训练结合,解决了一个长期困扰 3DGS 的工业化部署难题。
局限性:目前的排序主要基于不透明度,虽然简单有效,但在处理高度透明的特殊材质(如玻璃、薄雾)时可能不是最优的。未来的研究可能会引入视距相关的动态优先级。
关键词:#3DGS #LoD #MatryoshkaLearning #实时渲染 #CVPR2026