本文推出了 MEDOPENCLAW,一个专为大模型设计的可审计医疗影像交互运行时,以及首个全研究级(Full-study)基准测试 MEDFLOW-BENCH。该系统允许 VLM 智能体直接调用 3D Slicer 等专业软件,在未标注的 3D 原始影像中进行自主导航、证据搜集和临床诊断。
TL;DR
长期以来,医疗 AI 的评估一直被“投喂式”的 2D 切片所误导。由于缺乏直接操作医疗软件的能力,模型无法展现真实的临床推理过程。MEDOPENCLAW 改变了这一现状,它提供了一个可审计的运行时环境,让 VLM 能够像人类放射科医生一样,在 3D 空间中滚动切片、对比序列。然而,研究发现了一个有趣的**“工具使用悖论”**:给模型更好的手术刀,它反而可能把手术做砸。
痛点深挖:被“喂饭”的 AI 不是好医生
在真实的临床中,放射科医生面对的是包含几百张切片的 CT 或 MRI 原始数据(Full-study),他们需要:
- 自主导航:在成百上千的切片中定位病灶。
- 多序列对比:结合 T1, T2, FLAIR 等不同模态验证猜想。
- 工具测量:手动勾画或测量病灶大小。
而现有的 Benchmark(如图 1 左侧)大多是“给一张图,问一个问题”。这种设定抹杀了临床诊断中最难的一环——证据搜集。更糟糕的是,黑盒模型的回答不可追溯,医生不敢信,监管不通过。
方法论:构建可审计的医疗运行时
MEDOPENCLAW 并不是一个模型,而是一个 Runtime (运行时)。它在模型和专业的 3D Slicer 软件之间搭了一座桥。
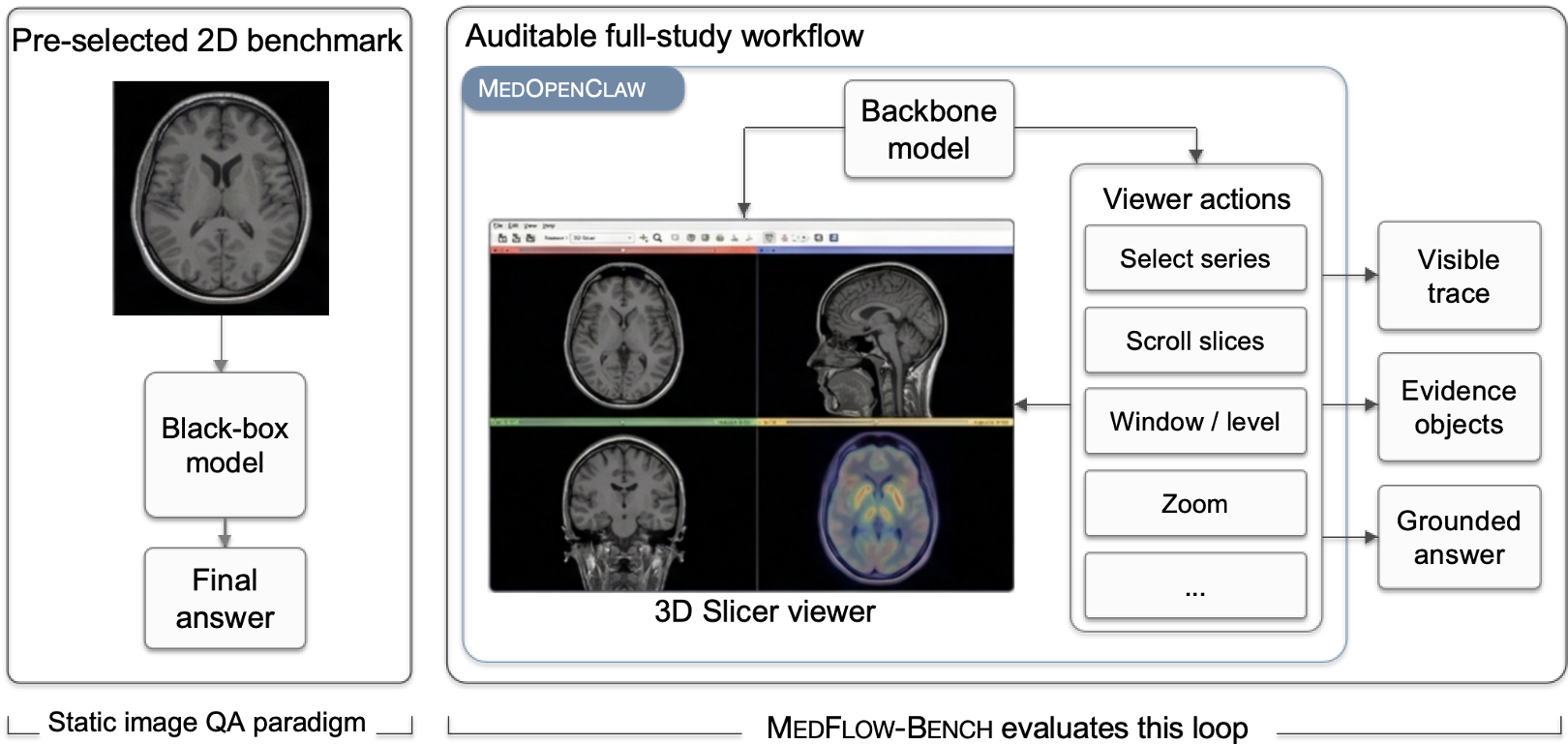
核心设计原则:
- Bounded Action Space (受限动作空间):模型不能乱写 Python 脚本(安全风险),只能通过受限的 REST API 调用定义好的功能(如“跳转到第 50 层”、“调整窗宽窗位”)。
- Auditability (可审计性):系统会自动记录每一次 Tool Call、每一张截图和每一个参数。这意味着诊断过程可以被 100% 重放,满足医疗合规性。
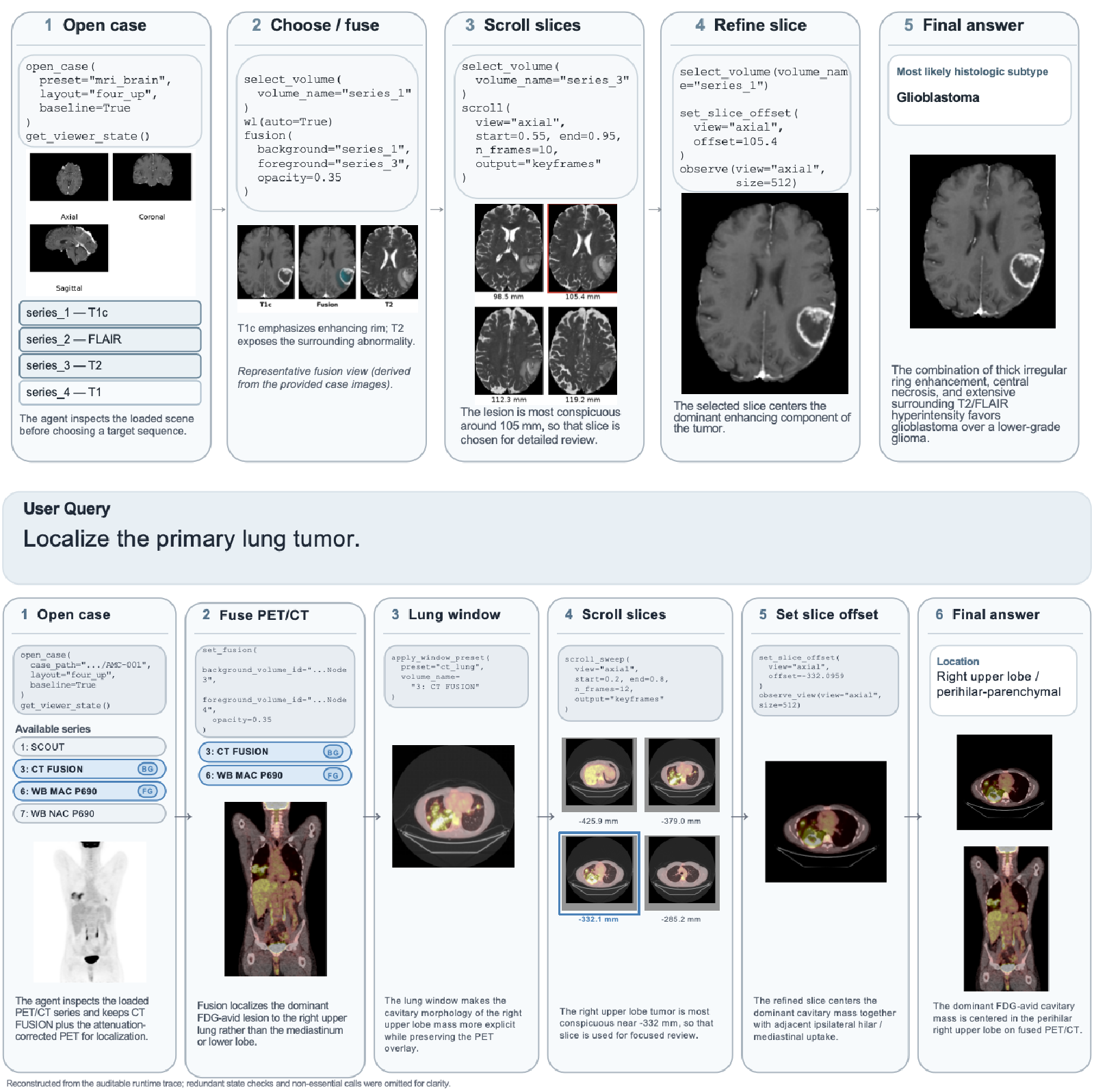
MEDFLOW-BENCH:全研究级挑战
基于该运行时,作者推出了 MEDFLOW-BENCH。它涵盖了脑部 MRI 和肺部 CT/PET 数据。不同于以往,模型现在必须自主在 3D 空间进行检索。
它设立了三条赛道:
- Track A (Viewer-Only):纯视觉感知,只准看和翻页。
- Track B (Tool-Use):可以使用高级工具(如 MONAI 分割包)。
- Track C (Open-Method):不限手段,测试原生 3D 模型的潜力。
实验结果:揭示“工具使用悖论”
实验结果给当前火热的 Agent 社区浇了一盆冷水。
- 大模型会看病了吗? 在脑部 MRI 模块中,Gemini 3.1 Pro 达到了 0.63 的准确率。这证明前沿 VLM 已经具备了基本的 3D 导航感知能力。
- 悖论出现:当下表 3 显示出一种诡异的趋势,当给 GPT-5.4 增加“高级分割工具包”时,其表现反而下降了。

原因分析:这就是所谓的 Spatial Grounding(空间对准)失效。模型虽然知道“要在肿瘤位置进行分割”,但由于无法给出毫米级精确的坐标参数,导致分出的掩码全是错的。AI 被自己生成的“伪证据”误导,最终做出了错误的诊断。
深度洞察与总结
MEDOPENCLAW 的出现标志着医疗 AI 从“选择题”时代进入了“诊断题”时代。
- Takeaway 1:感知不代表控制。目前大模型能“看懂”病灶,但由于缺乏对物理空间坐标的精确操控力,它们在调用专业医疗工具时显得笨拙。
- Takeaway 2:可审计性是刚需。MEDOPENCLAW 记录的动作轨迹(Trace)不仅是为了测试,更是为了未来构建 MedCopilot(医疗协作者),让医生在核实 AI 诊断时有据可查。
未来展望: 未来的突破口可能不在于模型参数的堆砌,而在于如何实现 Fine-grained Spatial Control。只有当 AI 能像外科医生手术刀一样精准地定位 3D 空间坐标时,真正的医疗自动驾驶才会到来。
本文基于论文《MEDOPENCLAW: Auditable Medical Imaging Agents Reasoning over Uncurated Full Studies》深度解读。