本文提出了 MinerU-Diffusion,一个将文档 OCR 重新建模为“逆渲染(Inverse Rendering)”过程的扩散模型框架。该框架利用基于块(Block-wise)的扩散解码取代了传统的自回归流水线,在保持与 SOTA 相当的识别精度的同时,实现了高达 3.2 倍的推理加速。
TL;DR
传统的 OCR 就像在蒙着眼睛写字——根据前一个字猜下一个字(自回归解码),这不仅慢,还容易想当然(语义幻觉)。MinerU-Diffusion 彻底颠覆了这一逻辑,它将 OCR 视为一种基于视觉反馈的逆渲染过程,利用**扩散模型(Diffusion Models)**实现了文本块的并行生成。结果:精度不减,速度暴增 3.2 倍,且对乱序文档的适应性远超传统 Transformer 模型。
1. 痛点深挖:自回归解码的“语义依赖”陷阱
目前的视觉语言模型(VLM)在处理文档 OCR 时,通常遵循“图像编码器 + 自回归解码器”的架构。然而,作者指出这种范式存在两个本质缺陷:
- 顺序延迟(Sequential Latency):逐个 Token 生成的特性使得长文档处理速度极慢,且无法利用 GPU 的并行计算优势。
- 语义幻觉与累积误差:自回归模型本质上是在预测“概率最高”的序列。当遇到表格、公式等结构复杂区域时,模型往往会过度依赖语言模型内部的知识,而非忠实于图片,从而产生看似合理实则错误的识别结果。
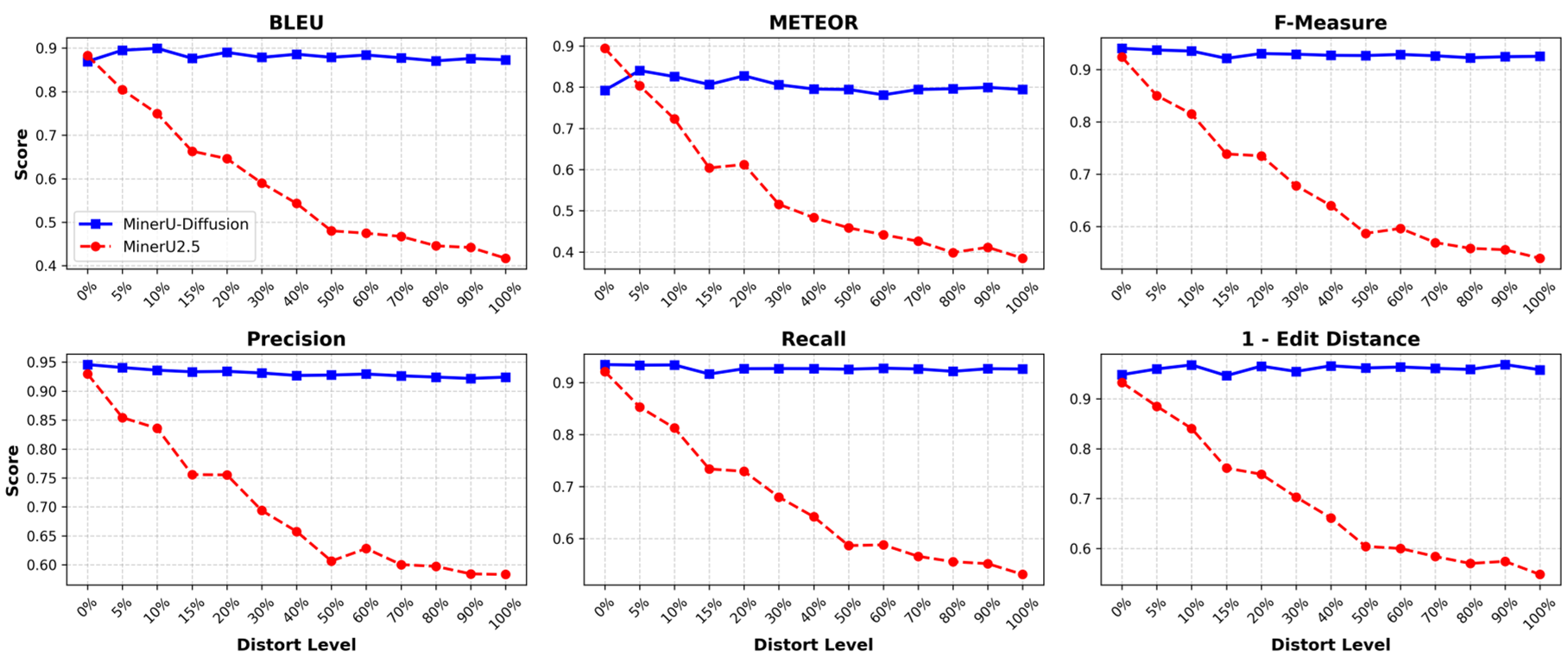
作者通过 Semantic Shuffle 实验(如图 7)证明:当文档词汇顺序被随机打乱、语义丧失时,自回归模型的表现呈断崖式下跌,而扩散模型表现极其稳健。这说明传统 OCR 系统其实在“连蒙带猜”,而扩散模型是在“真正读图”。
2. 核心方法论:逆渲染与块扩散架构
2.1 逆渲染视角 (Inverse Rendering)
作者认为,OCR 输出虽然序列化为一维,但其背后的统计依赖源于二维的布局和排版,而非因果逻辑。因此,采用类似图像生成的逆渲染思路更为自然:将初始的 Mask 序列,在视觉特征的引导下,逐步去噪还原为清晰的结构化文本。
2.2 核心架构:MinerU-Diffusion
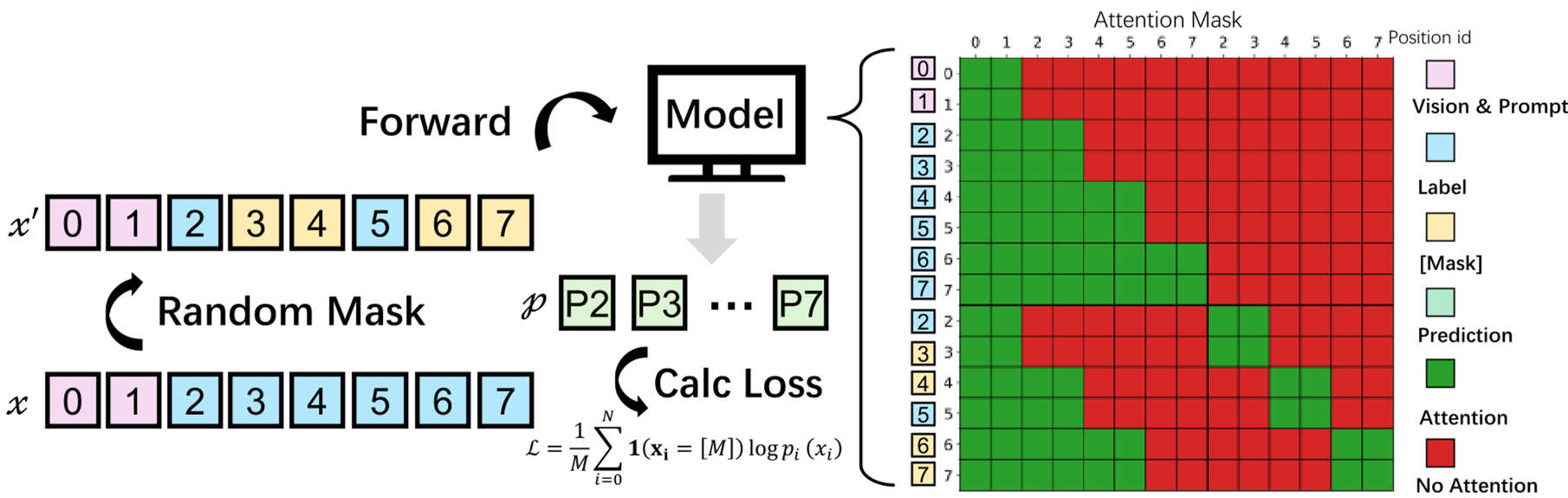
为了解决全局注意力扩散在长序列下的效率和稳定性问题,MinerU-Diffusion 引入了 Block-wise Attention 机制:
- 架构设计:将序列划分为 B 个连续块,块内采用全双向注意力的扩散解码,块间保持自回归序列依赖。
- 优势:这种“跨块自回归、块内扩散”的混合模式既保留了块内并行生成的高效率,又通过块边界作为锚点,防止了超长序列下的位置特征漂移。
2.3 两阶段课程学习策略
针对扩散模型训练难、标签噪声敏感的问题,团队设计了精妙的训练路径:
- 阶段 I (多元基础学习):在大规模多样化数据集 Dbase 上建立稳健的视觉-语义对齐,磨炼基础解析力。
- 阶段 II (不确定性驱动精修):利用模型在推理时的不确定性分数(如一致性指标 CDM/TEDS)挖掘“难例”。对这些难例进行人工/AI 高精度标注后再进行精修,极大提升了模型在复杂表格和边缘案例上的表现。
3. 实验验证:SOTA 性能与极致能效比
3.1 速度与精度的平衡屏障
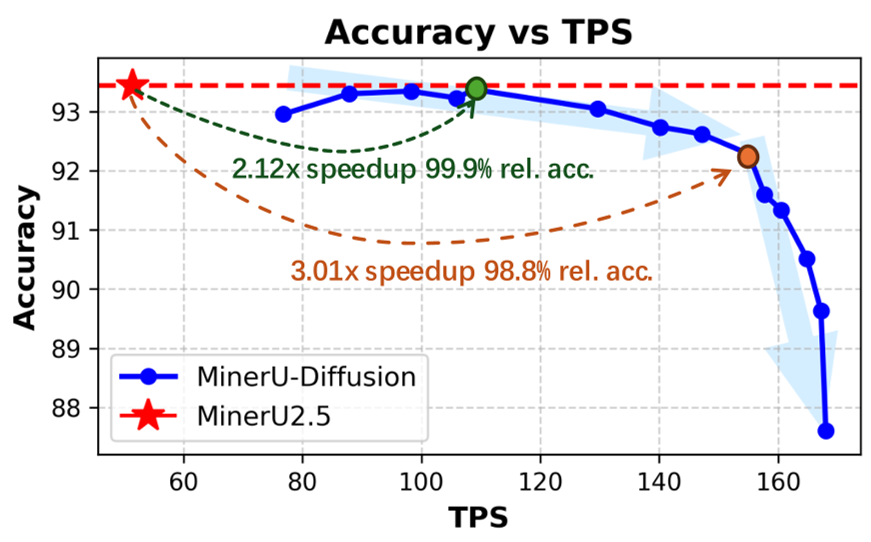
在 OmniDocBench v1.5 等核心榜单上,MinerU-Diffusion 仅用 2.5B 参数就达到了与甚至超过 72B 参数大模型(如 Qwen2.5-VL-72B)相近的水平。更令人振奋的是其推理效率:
- 2.12x 加速:在保持 99.9% 相对准确度时实现的性能提升。
- 3.26x 加速:通过调节置信度阈值(Confidence Threshold),在牺牲极小精度的情况下实现的峰值加速。
3.2 深度消融:扩散并不慢
实验数据展示了动态阈值(Dynamic Scheduling)策略如何平衡效率与稳定性(如图 4)。当阈值设定为 0.95 时,MinerU-Diffusion 能够在减少错误累积的同时,依然通过并行性获得远超自回归系统的吞吐量。
4. 深度洞察与展望
4.1 为什么扩散模型在 OCR 领域奏效?
OCR 的本质是高度确定性的映射(即图片里有什么就识别什么),这与开放式对话(Next Token Prediction 的高度不确定性)有本质区别。扩散模型的条件独立假设在 OCR 这种近乎“确定性转换”的任务场景下显得极其合理,同时也避开了 LLM 的语义偏置问题。
4.2 局限性与未来
尽管 MinerU-Diffusion 表现优异,但在全自动页面解析中,布局分析(Layout Analysis) 依然是整体流程的瓶颈(见 w/o GT Layout 结果)。未来的研究方向或将集中在如何将布局检测也更深度地融入扩散流程中。
总而言之,MinerU-Diffusion 为 OCR 设计提供了一条全新的、非因果的进化路线。随着长文档处理需求的爆发,这种高并行、低幻觉的架构无疑将成为工业界关注的重点。
关键词:#OCR #DiffusionModel #MinerU #VLM #ParallelDecoding