本文提出了 MPCwDWM,一种针对 Offline RL 的推理时自适应(Inference-time Adaptation)框架。该方法通过构建可微扩散世界模型(Differentiable World Model),在推理阶段利用模型预测控制(MPC)的思想,基于当前状态对策略参数进行在线梯度优化,在 D4RL 任务中显著超越了 ReBRAC 等强基线。
TL;DR
在 Offline RL 领域,我们习惯于“离线训练,在线部署”的模式,但这种静态策略往往难以应对复杂的分布偏移。本文提出的 MPCwDWM 打破了这一常规,它引入了一个可微扩散世界模型 (Differentiable World Model)。在推理的每一秒,模型都在通过“想象”未来的轨迹并计算梯度,从而实时微调自己的策略参数。这种推理时自适应 (Inference-time Adaptation) 让它在 D4RL 标准测试中刷新了多项纪录。
背景定位
离线强化学习的核心难点在于 Distribution Shift:模型在没见过的数据上容易产生错误的 Q 值估计。传统方法如 CQL、IQL 或 ReBRAC 主要在损失函数上做文章。而 MPCwDWM 另辞辟径,它认为:既然世界模型(动态 $P$ 和奖励 $r$)是局部对象且相对独立于策略,那么在推理时利用这些局部知识进行短程搜索和策略微调,比单纯依赖一个死板的预训练模型要靠谱得多。
核心直觉:为何需要“可微”世界模型?
很多基于世界模型的方法(如 Diffuser 或 Trajectory Transformer)在推理时通过采样 (Sampling) 来找好梯子,但这更像是一种“搜索”,而不是“学习”。
MPCwDWM 的核心 Insight 是:将扩散模型的去噪过程封装成一个确定的、可微的计算图。这意味着,当我们进行 $H$ 步的“脑内模拟 (Imagined Rollout)”时,不仅能看到结果,还能计算出“为了获得更高奖励,我的策略网络参数 $\psi$ 应该如何微调”的精确梯度。
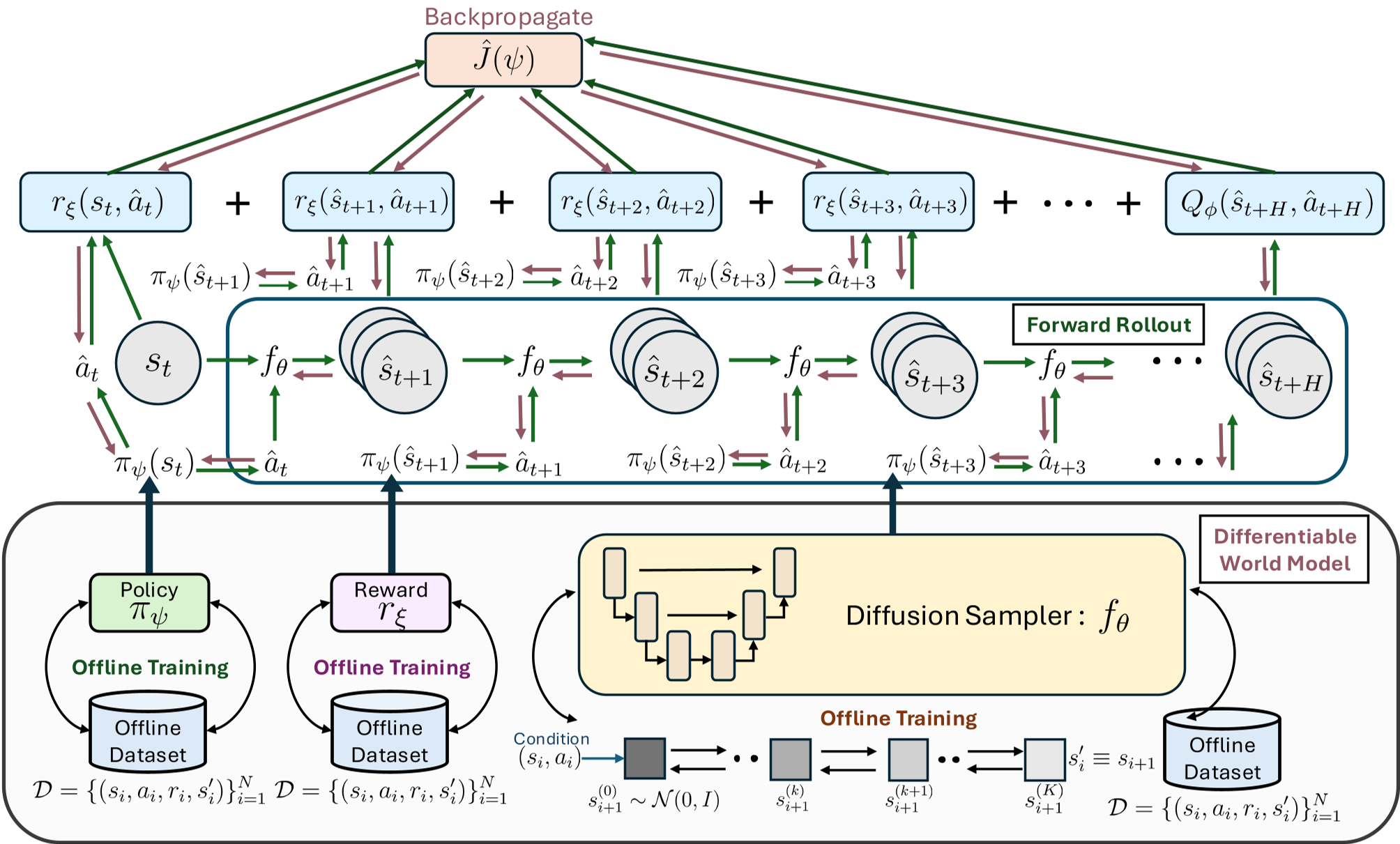 图 1: 推理时 MPC 与扩散世界模型的结合。绿色箭头代表前向模拟,红色虚线代表梯度流。
图 1: 推理时 MPC 与扩散世界模型的结合。绿色箭头代表前向模拟,红色虚线代表梯度流。
方法论:雅可比矩阵的递归链条
MPCwDWM 的执行流程如下:
- 离线阶段:训练策略 $\pi_\psi$、扩散动力学模型 $f_ heta$、奖励模型 $r_\xi$ 和终端价值函数 $Q_\phi$。
- 推理阶段:
- 观测当前状态 $s_t$。
- Inner Loop:在“脑内”进行 $M$ 组多步想象。利用递归链式法则,通过动力学模型和奖励函数的 Jacobians 计算 $ abla_\psi J$。
- 更新参数:利用梯度上升微调策略参数 $\psi$。
- 执行:用更新后的策略执行动作。
论文在定理 4.1 中给出了优雅的数学证明,展示了如何将扩散模型的去噪步骤与策略梯度结合。这避免了传统强化学习中高方差的评分函数估计,直接利用了环境模型的确定性梯度。
实验结果:全方位的性能飞跃
实验结果证明,这种“推理时补课”的方法非常有效。
- MuJoCo Locomotion:在 18 个数据集中的 12 个上达到了新的 SOTA,平均 normalized score 从 ReBRAC 的 81.5 提升到了 85.3。
- AntMaze:在最难的 Large Maze 任务中,MPCwDWM 的表现尤为卓越。这反映出当任务涉及长程规划且 offline 数据稀疏时,依靠世界模型进行推理自适应具有极高的价值。
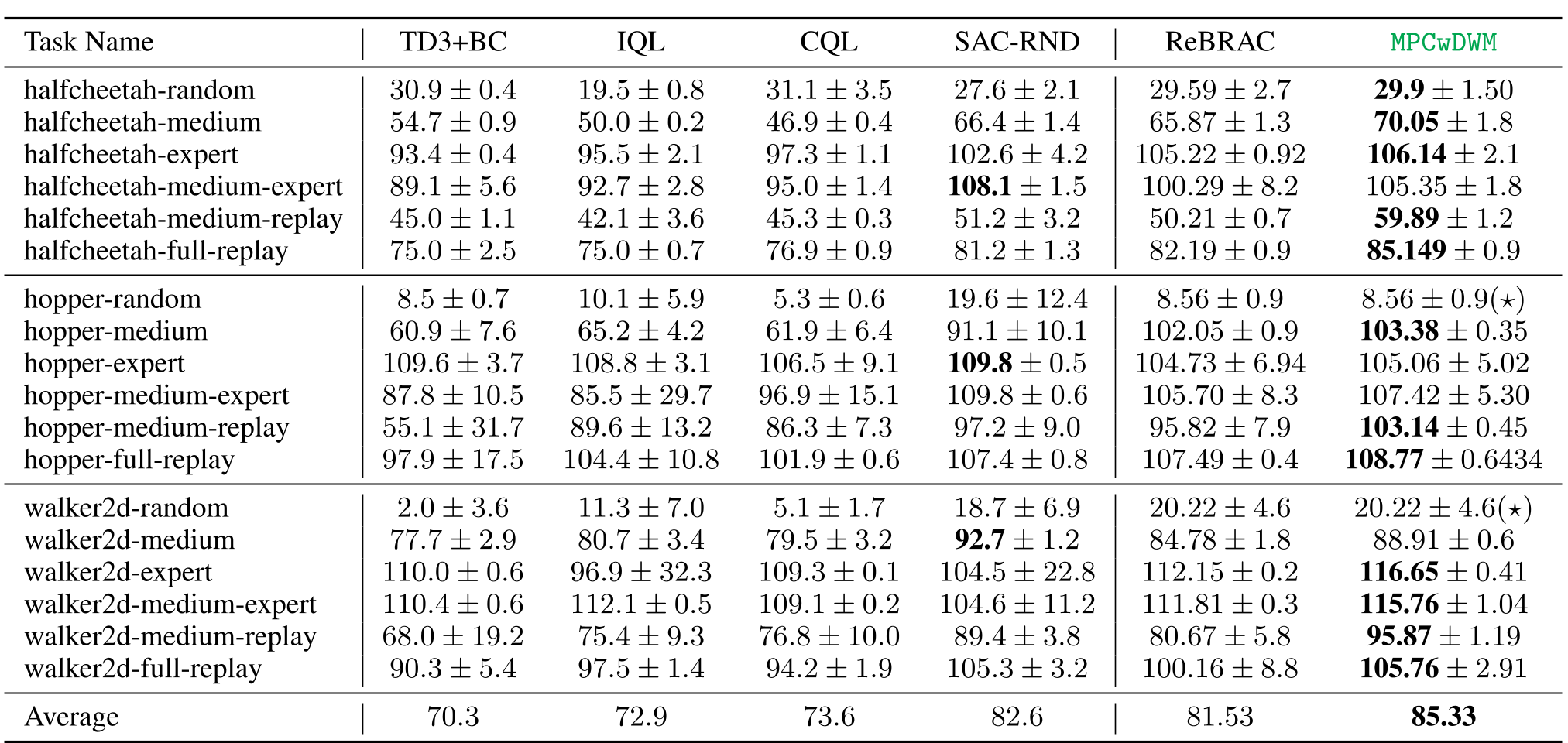 表 1: 在 D4RL 任务上的对比。MPCwDWM 在多个子项中显著领先。
表 1: 在 D4RL 任务上的对比。MPCwDWM 在多个子项中显著领先。
深度洞察与总结
为什么它有效?
- 局部信息的准确性:世界模型学习的是一阶段的 $s o s'$,这比学习全局 $Q$ 值要简单且准确得多。
- Inference-time Compute:类似于 LLM 领域近期热门的搜索增强,该方法证明了算力在推理阶段的投入产出比极高。
局限性与展望
- 计算开销:扩散模型本身的去噪就很慢,再加上反向传播梯度,推理延迟是一个不可忽视的问题。作者也提到,未来可以考虑多步生成模型或 Flow Matching 来提速。
- 模型的鲁棒性:如果世界模型由于数据稀疏学偏了,推理时的梯度优化反而可能导致策略走向极端(Exploiting model errors)。
总的来说,MPCwDWM 为 Offline RL 提供了一个极具启发性的方向:不要试图在离线阶段解决所有问题,留一部分计算和智慧给推理时刻。