本文提出了 MoRI 框架,旨在解决大语言模型(LLM)在科学创意生成(Scientific Ideation)中缺乏深度和逻辑严密性的问题。通过引入基于动机的推理(Motivation-grounded Reasoning)并结合强化学习(RL),MoRI 实现了从研究动机到具体方法论的显式推理,并在 ICLR 论文数据集上显著超越了 GPT-4o 及复杂智能体基线。
TL;DR
在科学发现的征途中,提出一个“好点子”往往比验证它更难。目前的 AI 实验室虽然能产出无数创意,但大多是“旧瓶装新酒”的随机组合。本文介绍的 MoRI (Motivation-grounded Reasoning) 框架,通过强化学习让 DeepSeek-R1 等模型内化了从“研究动机”到“技术实现”的深度推理路径,产生的创意在严谨性和可行性上首次全面压制了顶级商业模型和复杂的智能体系统。
痛点深挖:为什么 AI 创意总是“看起来很美”?
当前的 LLM 生成科学点子(Scientific Ideation)主要面临两大困境:
- 浅层重组:模型倾向于将几个热门关键词(如 Diffusion, Transformer, Contrastive Learning)强行拼凑,缺乏物理或逻辑上的必然性。
- 缺乏严谨性:由外部 Python 脚本或 Agent 驱动的迭代虽然能增加字数,但模型内部并没有真正理解“为什么要这么做”。
作者指出,一个高质量的科学创意必须是:Context (背景) -> Motivation (动机) -> Reasoning (推理) -> Methodology (方法论) 的连贯映射。而现有的工作往往跳过了中间的推理环节,直接从背景跳到结论。
核心动机与方法论 (Methodology)
MoRI 的核心思想是将科学发现过程内化(Internalize)。它不依赖外部的反复搜索,而是通过一套精密的奖励机制,训练模型如何“思考”。
1. 架构解析:两阶段推理
MoRI 将任务分解为两个策略:
- 动机提案策略 ($\pi_\phi$):从海量背景中分析痛点,确定“我要解决什么问题”。
- 推理驱动策略 ($\pi_ heta$):在给定动机下,生成一段逻辑极其致密的思维轨迹(Reasoning Trajectory),最终推导回具体的方法论。
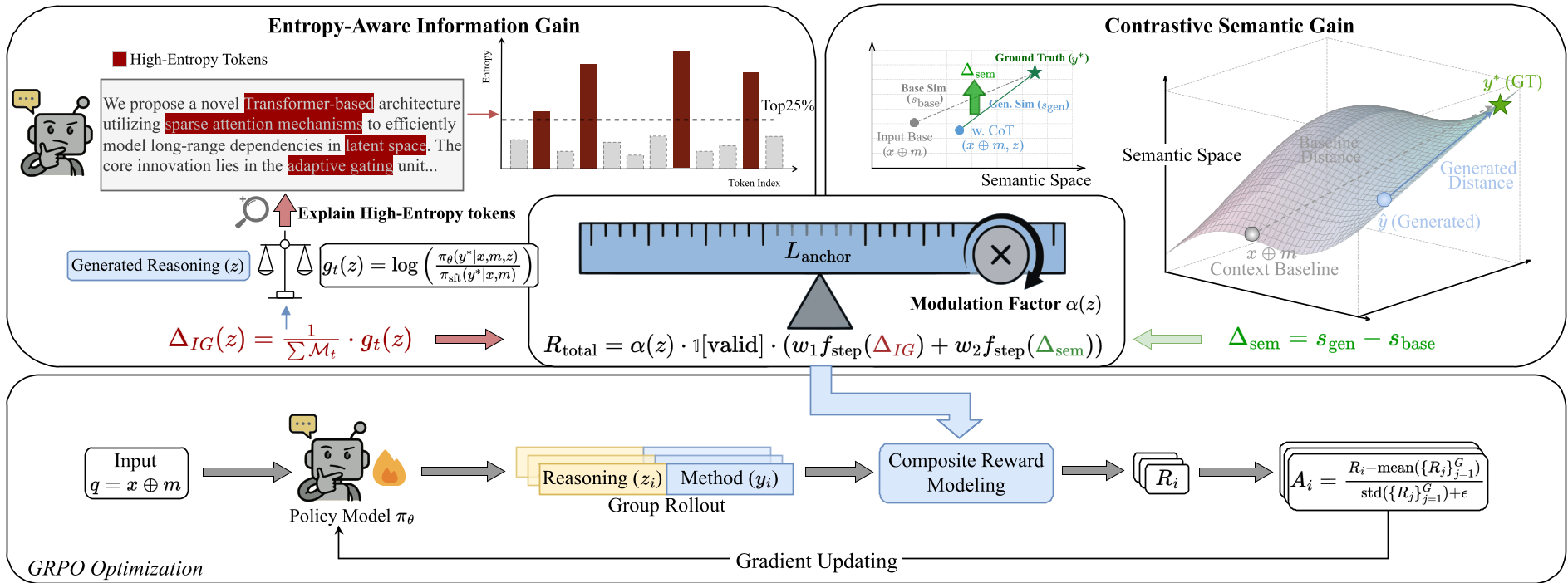
2. 双粒度奖励函数:拒绝奖励作弊 (Reward Hacking)
这是 MoRI 最硬核的贡献。在没有确定性评分标准(如数学题答案)的情况下,如何给一个创意打分?
- EAIG (熵感知信息增益):通过计算 Token 的信息熵,自动过滤掉“we propose to”等废话,强迫模型将推理权重放在那些高复杂度的技术词汇上。
- CSG (对比语义增益):利用 Embedding 计算生成内容相对于初始背景的语义增量,防止模型只是复述背景知识。
- 长度锚定 (Length Anchoring):专门对付 RL 中常见的“思维塌缩”现象,迫使模型维持足够长的推理链条。
实验战绩:全方位压制商业模型
实验采用了 ICLR 2024-2025 的论文作为基准。MoRI 在 14B 参数规模下,表现惊人:
- 技术严谨性 (Technical Rigor):得分 3.16,超过了 Claude-3.5-Sonnet (3.07) 和 GPT-4o (2.78)。
- 可行性 (Feasibility):相比 Claude 提升了 10% 以上,解决了 AI 创意“落地难”的顽疾。

在消融实验中,作者揭示了一个有趣的现象:如果没有 EAIG 奖励,模型的推理会由于追求语义相似度而变得平庸;如果没有 CSG 奖励,模型则会陷入自言自语的“胡言乱语”中。 两者的结合才构成了科学研究的“微观严谨”与“宏观导向”。
深度洞察:科学思维的“内化”胜过“繁琐外挂”
MoRI 的成功再次验证了“苦涩的教训”(The Bitter Lesson):通用的、基于学习的方法,在长期来看总是胜过基于人工启发式的系统。
目前许多团队在做 AI Scientist 时,倾向于设计极其复杂的 Agent 流程(搜索、写代码、审稿、修改)。而 MoRI 告诉我们,如果能通过 RL 让模型内化这种科学直觉,那么一个简洁的推理模型就能产生比复杂工作流更高质量的洞见。
总结与局限
Takeaway:MoRI 证明了动机驱动的 RL 学习是提升 LLM 创意质量的关键。 局限性:目前实验主要集中在 CS (计算机科学) 领域。对于需要物理化学实验反馈的领域,如何构建有效的“代理奖励”依然是未来值得探索的方向。
本文由资深学术技术主编重构。原文:MoRI: Learning Motivation-Grounded Reasoning for Scientific Ideation in LLMs.