本文提出了 MoRight,一个统一的视频生成框架,通过双流(Dual-stream)架构实现了相机视角与物体运动的解耦控制。该方法在 Wan2.1 基础上,不仅能精确遵循用户定义的轨迹,还能通过因果运动建模(Motion Causality)自动推理动作引发的物理后果。
TL;DR
生成可控视频不仅要让物体“动起来”,还要动得“对”。NVIDIA 团队提出的 MoRight 突破了传统视频生成模型对相机与物体运动的模糊处理,通过双流架构实现视角解耦,并引入运动因果建模。用户只需在首帧画出简单的线条,模型就能预测出复杂的物理反馈(如:拨动琴弦,琴弦振动),目前已在多项 SOTA 任务中取得领先。
1. 痛点:为什么当前的视频生成“不听话”?
在现有的 Trajectory-based 方法(如 DragAnything, WanMove)中,我们常遇到两个令人头疼的问题:
- 视角与位移的纠缠:如果你想让相机绕着跑车转,同时让跑车向前开,在像素平面上这两者的轨迹是杂乱交织的。模型很难在没有显式几何信息的情况下处理这种复合运动。
- 物理逻辑缺失:大多数模型只是简单的“像素搬运工”。当你拖动一只手去撞击球,模型可能只会平移球的像素,而不会表现出球受力后的滚动、反弹或碰撞。
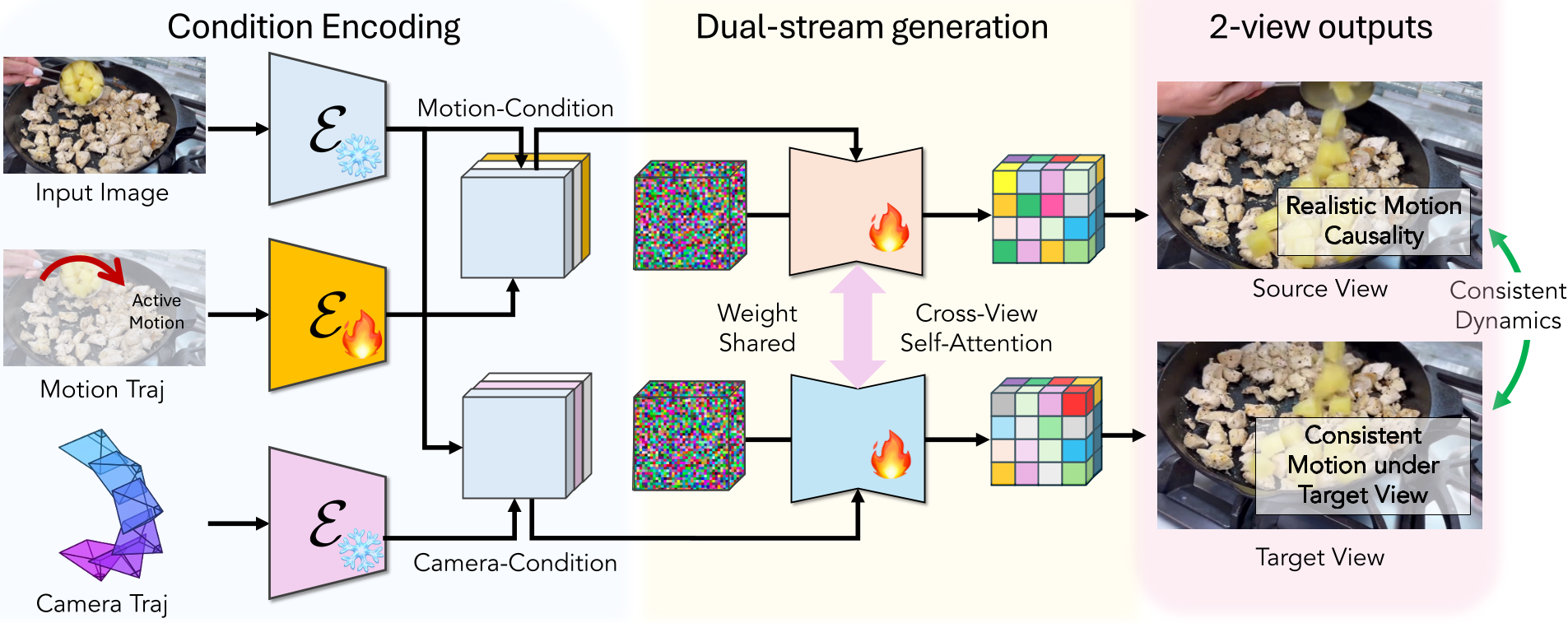
2. 核心机制:双流架构与运动迁移
MoRight 的核心直觉是:物体运动在“规范视角”(静态相机)下是最纯粹的。
2.1 规范空间锚点 (Canonical Anchor)
模型采用双流设计:
- 规范流 (Canonical Stream):负责在固定的静态视角下生成物体的纯动态。
- 目标流 (Target Stream):负责根据用户指定的相机参数(旋转、缩放)生成最终视频。
这两个流共享 DiT 权重,通过 时间跨视图注意力 (Temporal Cross-view Attention) 进行交互。规范流就像一个“虚拟锚点”,它先锚定物理运动,再通过注意力机制将这些运动特征“投影”到变化的目标流视角中。
3. 进化:从运动学到位移因果 (Motion Causality)
MoRight 不满足于简单的轨迹跟随,它引入了 Active(主动) 与 Passive(被动) 运动的分解。
- 主动运动:用户的操作(如手拉开抽屉)。
- 被动运动:操作引发的后果(如抽屉里的物品随之震动)。
在训练阶段,模型通过 Motion Dropout 策略,随机丢弃主动或被动的轨迹输入,强制模型根据残余信息补全整个物理过程。
前向与逆向推理
这赋予了 MoRight 两种神奇的能力:
- 前向推理 (Forward):画出手部的推力轨迹,模型自动补全杯子被打碎的过程。
- 逆向推理 (Inverse):画出球滚动的轨迹,模型自动生成“谁在踢这个球”。

4. 实验战绩:全方位的压制
在 DynPose-100K 这种相机运动剧烈的场景下,MoRight 依然保持了极高的运动准确度。在专门测试物理常识的 WISA 基准上,其 PC 评分显著超过了之前的强力基准 ATI 和 WanMove。
| Method | Dataset | PSNR ↑ | EPE (Motion) ↓ | Physical Scores ↑ | | :--- | :--- | :--- | :--- | :--- | | WanMove | Cooking | 16.42 | 5.47 | 0.84 | | MoRight (Ours) | Cooking | 16.44 | 4.27 | 0.88 |

5. 深度洞察与总结
MoRight 的成功标志着视频合成正在从“视觉仿真”向“物理仿真”进化。它不需要昂贵的 3D 软件渲染或复杂的物理引擎接入,而是通过精妙的数据增强(如生成成对的动/静相机视频)和架构设计,让模型潜移默化地学到了世界的运作规律。
局限性:尽管表现优异,但在处理极端快速或复杂的相机运动(如第一人称跑酷视角)时,解耦依然存在失效风险。此外,偶发性的幻觉(多出一只手)仍是扩散模型的通病。
对于未来的具身智能系统,MoRight 提供了一个极其高效的“想象力模块”,帮助 AI 预测其行为在物理世界中可能产生的后果。