本文提出了 MPDiT,一种应用于 Flow Matching 和扩散模型的新型分层 Transformer 架构。通过引入“由全局到局部”的多尺度 Patch 处理机制、FNO 时间嵌入和多 Token 分类嵌入,MPDiT 在保持 SOTA 生成质量的同时,将计算量(GFLOPs)最高降低了 50%,并在 ImageNet 上实现了显著的训练加速。
TL;DR
传统的扩散 Transformer (DiT) 架构在所有网络层中都均匀地分配计算量,这在处理高分辨率潜空间时显得极度低效。Rutgers 大学的研究团队提出了 MPDiT (Multi-Patch Diffusion Transformer)。它的核心秘密在于:前期 Block 处理少而大的 Patch 来“看轮廓”,后期 Block 处理多而小的 Patch 来“抠细节”。这种直觉上的分工让 MPDiT 在 ImageNet 上的训练速度提升了 11 倍,而采样速度则翻了一番。
背景定位
自从 DiT 证明了 Transformer 在扩散模型中的可扩展性(Scalability)后,人们一直在寻找既能保留这种能力,又能降低其二次方复杂度(Quadratic Complexity)的方法。相比于通过稀疏注意力或线性注意力牺牲模型性能,MPDiT 选择从架构拓扑结构入手,是继 UViT 后又一重要的扩散模型 Backbone 设计优化。
核心痛点与直觉
现有的 DiT 架构是“等张”的(Isotropic),这意味着无论模型是在对齐全局构图还是在修饰发丝细节,它消耗的 Token 数量和计算能耗是完全一样的。
作者的 Insight 在于:
- 全局信息不需要高频采样:在大尺度 Patch 上进行自注意力计算足以捕获图像的整体结构。
- 局部精修只需少数层:实验发现,仅需最后 4-6 个 Block 处理高密度 Token 即可保证生成质量。
方法论详解:MPDiT 的三个大招
1. Global-to-Local 多尺度架构
MPDiT 将 Transformer 链路分为两部分。首先,利用 $p=4$ 的层级处理 64 个 Token(仅为标准 $p=2$ 的 25% 算力),捕捉全局上下文。然后通过一个关键的 Upsample Block 指数级扩展 Token 数量,并辅以 Skip Connection 引入原始潜空间的细粒度特征。
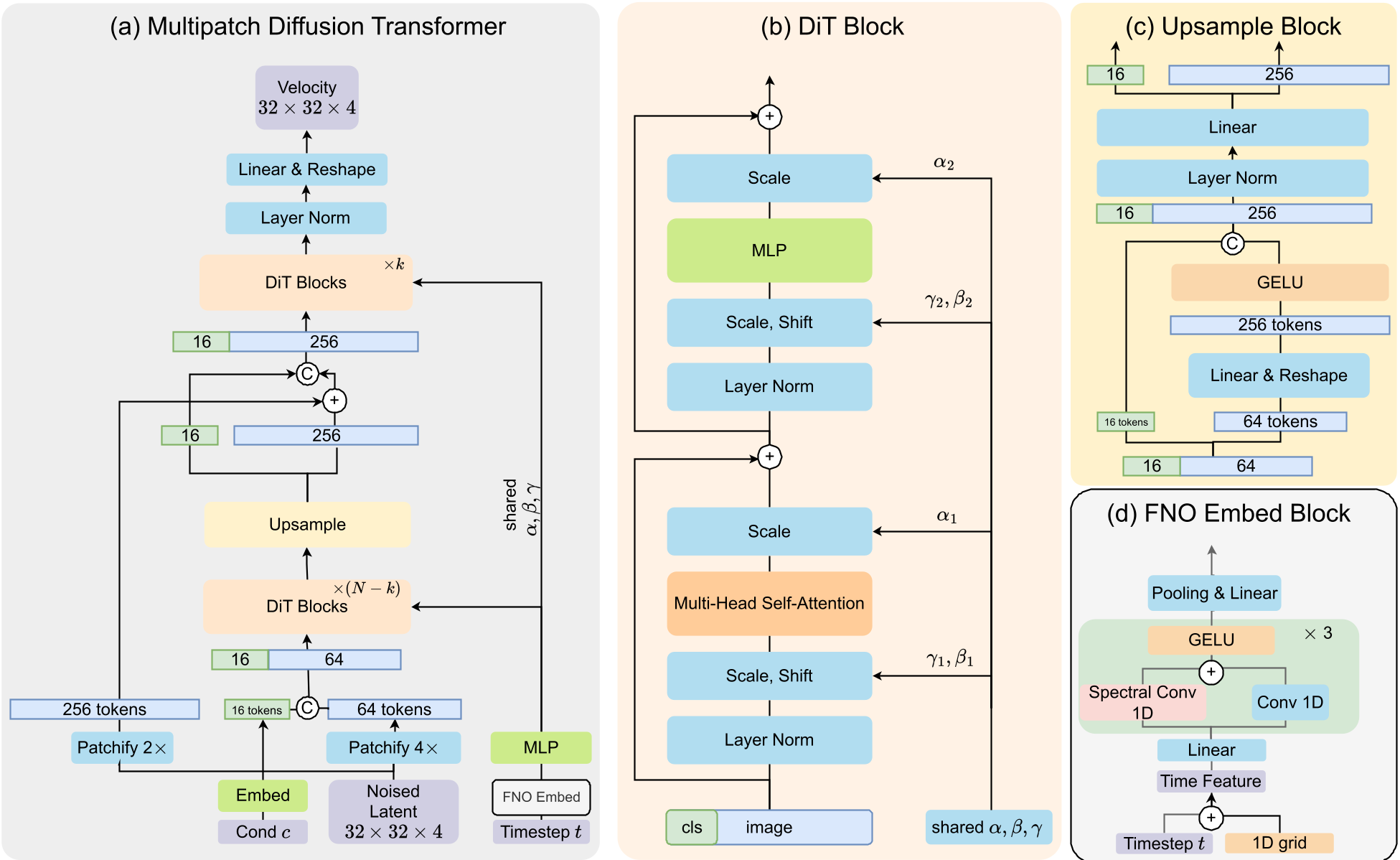 图 1:MPDiT 整体架构。注意到中间的上采样模块是连接全局与局部的核心桥梁。
图 1:MPDiT 整体架构。注意到中间的上采样模块是连接全局与局部的核心桥梁。
2. FNO 时间嵌入 (FNO Time Embedding)
不同于传统的正余弦位置编码后接简单的 MLP,MPDiT 引入了傅里叶神经算子(FNO)。这种设计通过 Spectral 卷积学习连续的时间动力学。对于流匹配(Flow Matching)这种依赖 ODE/SDE 轨迹的任务,FNO 能捕捉到更平滑的时间步转换,直接带来 4 个点左右的 FID 提升。
3. 多 Token 分类嵌入 (Multi-token Class Embedding)
为了避免类别信息被压缩得太死,MPDiT 使用 $m=16$ 个学习到的 Token 来代表类别,并将其作为前缀(Prefix)拼接在图像 Token 序列中。这为模型提供了更丰富的语义引导,显著加快了非平衡分布下的收敛速度。
实验与结果对比
在 ImageNet-256 和 512 上的实验证明了该设计的优越性:
| 模型 | Epochs | GFLOPs | FID (cfg 1.4) | | :--- | :--- | :--- | :--- | | SiT-XL/2 | 1400 | 118.6 | 2.15 | | MPDiT-XL (Ours) | 240 | 59.3 | 2.05 |
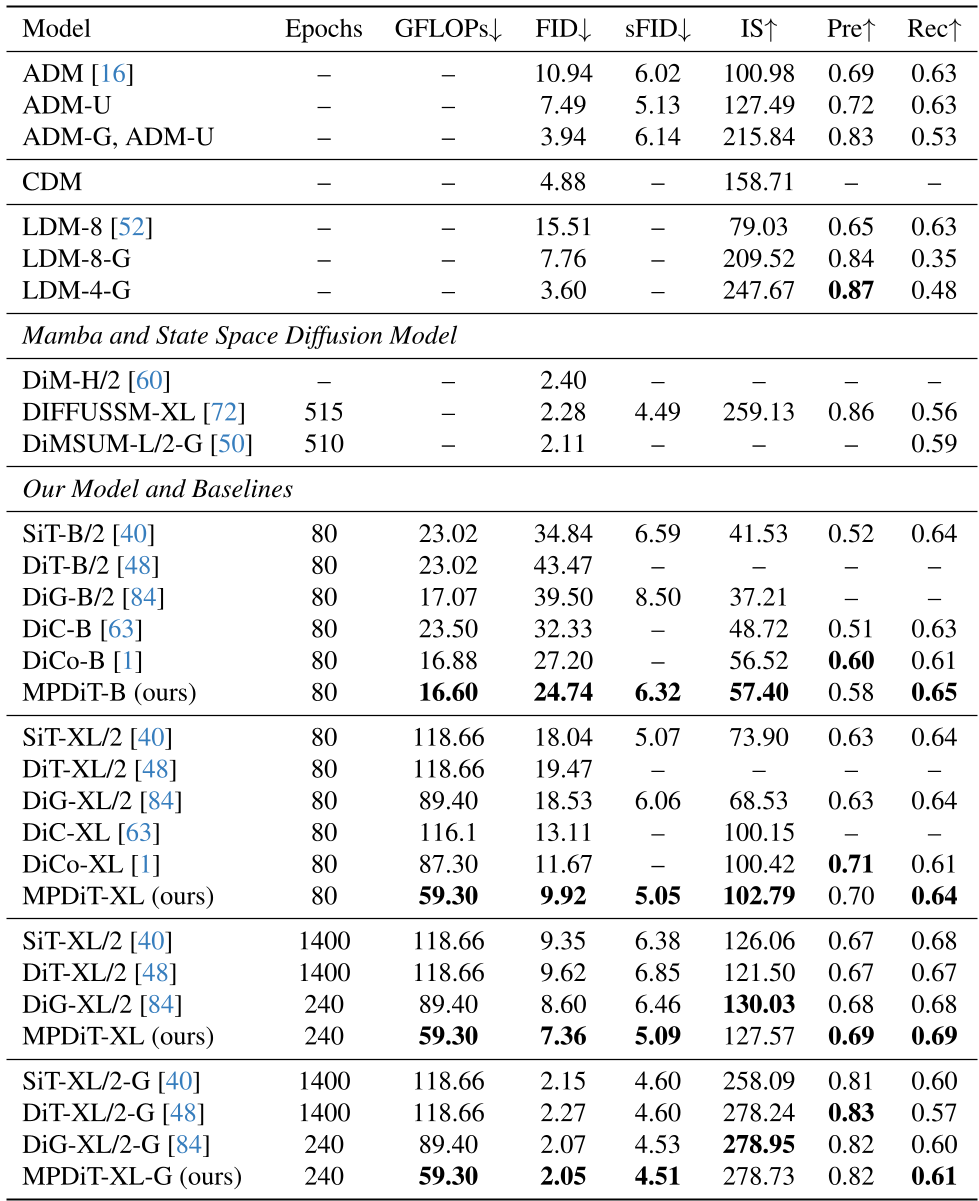 表 1:关键性能对比。在算力减半的情况下,MPDiT 仅用不到 1/5 的训练时间就超越了经典 SOTA。
表 1:关键性能对比。在算力减半的情况下,MPDiT 仅用不到 1/5 的训练时间就超越了经典 SOTA。
此外,消融实验展示了各个模块的具体贡献:
- Shared AdaIN:减少 30% 参数量。
- Multitoken Class:FID 提升约 7 点。
- FNO Embedding:FID 提升约 4 点。
深度洞察与总结
MPDiT 的成功证明了扩散模型的算力分配存在巨大的优化空间。它并没有采用复杂的数学变换来近似 Attention,而是回归到视觉处理的基本常识:粗到细(Coarse-to-Fine)。
局限性预测: 虽然该模型在 ImageNet 类条件生成上表现完美,但在处理超长文本(如 FLUX 这种 T5-XXL 驱动的模型)时,类别 Token 的策略能否平滑迁移为复杂的交叉注意力(Cross-Attention)还有待验证。
未来启示: 对于算力受限的团队,MPDiT 提供了一套“平民版”SOTA 方案——通过在低分辨率 Token 空间进行深度推理,仅在输出端进行少量高分辨率精修,这可能是视频生成模型迈向实时化的关键补丁。