本文提出了 MSFT (Multi-task SFT),这是一种用于多任务监督微调(SFT)的迭代式过拟合感知搜索算法。该方法通过动态识别并剔除过拟合较快的子数据集,在 10 个标准基准测试和 6 个基础模型上一致性地超越了 SOTA 基线,并显著提升了模型的泛化能力。
TL;DR
在多任务监督微调(SFT)中,让所有任务“陪跑”同样的 Epoch 是一种巨大的浪费。微软与 KAIST 的研究人员提出 MSFT (Multi-task SFT),通过“Roll-out 搜索 + Roll-back 回滚”的组合拳,动态剔除过拟合任务。它不仅在 10 个 Benchmark 上全面超越 SFT 基础线,还能在某些场景下实现“性能提升、算力减少”的双赢。
背景定位:SFT 中的“不公平”代价
目前大语言模型(LLM)的微调几乎都遵循一个范式:把代码、数学、通识等数据混在一起,跑 2 到 3 个 Epoch。
但这种**同质化(Homogeneous)**的计算分配忽略了一个核心直觉:任务的学习速度是不对称的。正如论文图 2 所示,有些简单任务(如 SciQ)在 1 个 Epoch 就达到了巅峰,随后开始过拟合;而复杂任务(如数学推理 AQUA-RAT)可能需要 3 个 Epoch 才能收敛。强行统一进度,会导致模型在某些领域“由于过度学习而变笨”,在另一些领域“因为学习不足而乏力”。
痛点深挖:为什么简单的“早停”行不通?
你可能会想:既然知道了每个任务的最优时间点,直接在那一刻把数据扔掉不就行了?
作者通过实验否定了这种**单次搜索(SRO SFT)**的有效性。其核心症结在于 梯度漂移(Gradient Drift):
- 相互依赖性:任务 A 的最优时间点是在包含任务 B 的梯度场中测得的。
- 轨迹分歧:一旦你剔除了任务 B,整体梯度的合成方向就变了,导致原本测量的任务 A 的最优时间点失效。
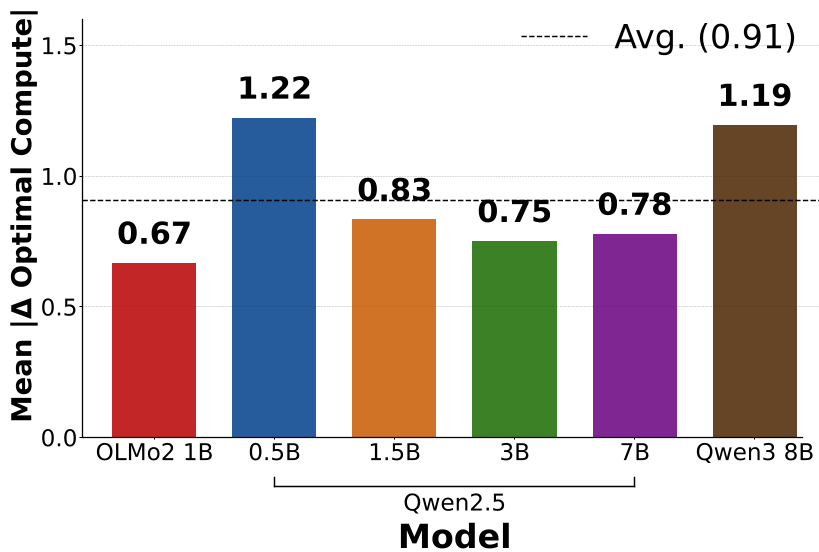 图 3:当剔除 1/10 的数据后,剩余任务的最优停止点发生了显著偏移(Δc)。*
图 3:当剔除 1/10 的数据后,剩余任务的最优停止点发生了显著偏移(Δc)。*
核心机制:MSFT 的“迭代回滚”策略
为了解决上述轨迹不一致问题,MSFT 抛弃了预预测,选择了动态迭代。
算法流程 (Algorithm 1)
- Initialization: 从基础模型开始。
- Roll-out (探路):在当前的活跃数据集混合体上训练一小段距离(计算预算 )。
- Identify: 监控验证集,找到这期间内最早达到性能顶峰的任务 。
- Roll-back (回滚):将模型状态回滚到那个任务性能最好的时刻。
- Exclude: 把这个任务踢出训练集,然后在回滚后的状态基础上,开始下一轮 Roll-out。
这种“边走边撤销”的逻辑,确保了模型每一步的训练路径和搜索路径是完全重合的。
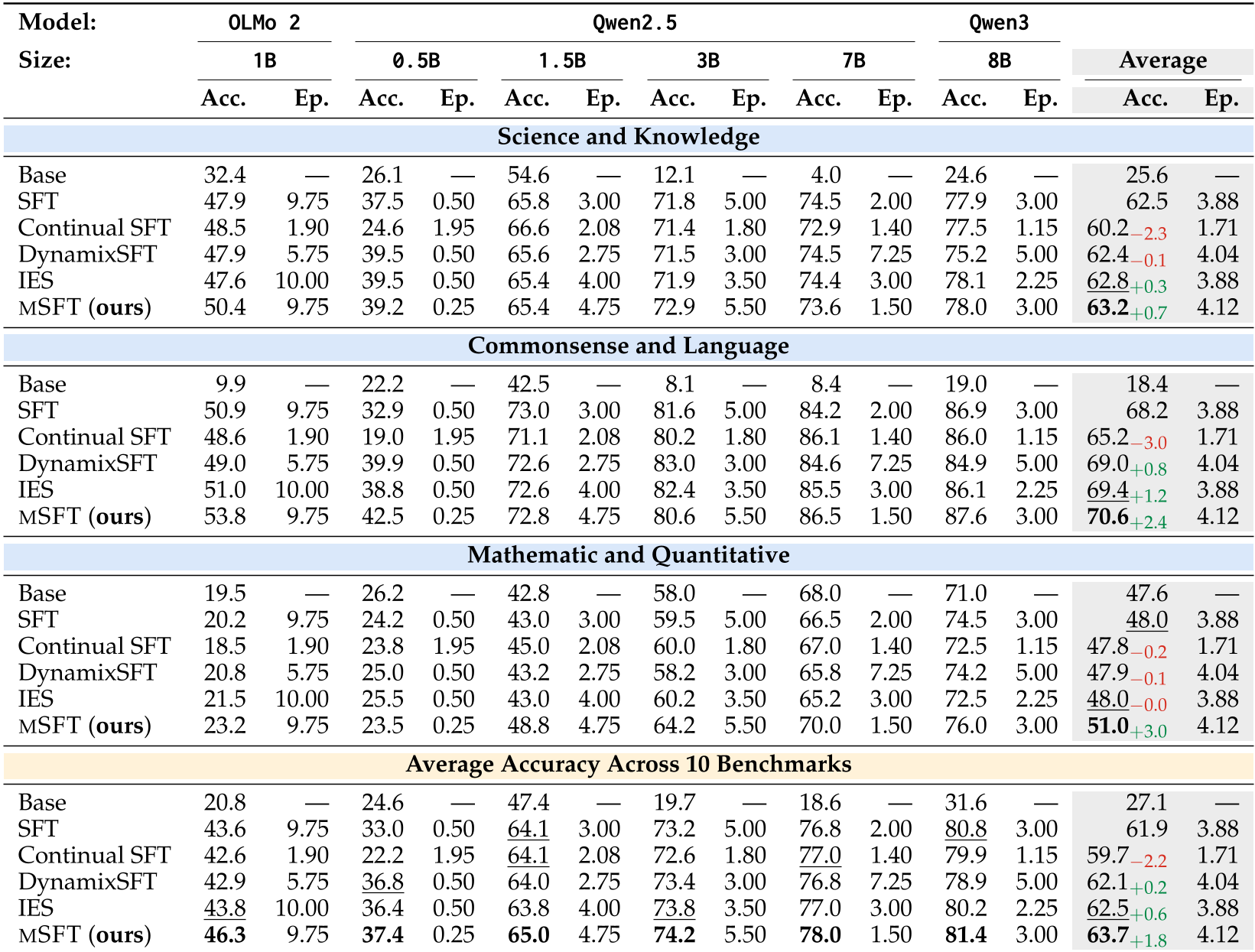
实验战绩:全线飘红
MSFT 在 6 个主流模型(包括 Qwen 2.5 和 OLMo 2)上进行了广泛验证。
- 泛化性:在数学、科学、常识三大领域均有提升。数学任务(Mathematics & Quantitative)的提升尤为显著,平均达到了 3.0%。
- 稳定性:图 4 显示,MSFT 的任务间标准差最低。这意味着它的提升不是靠牺牲某一个任务换来的,而是整体水位的一致抬升。
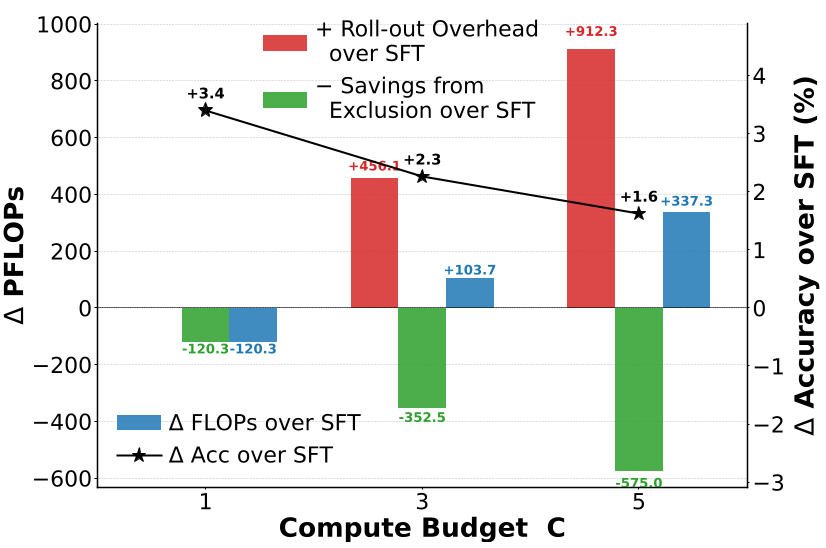
令人惊喜的“副作用”:节省算力
通常,复杂的搜索算法会增加计算开销。但 MSFT 却展现了极高的能效比:
- 当设定较小的计算预算 时,MSFT 的总 FLOPs 竟然比标准 SFT 还要低。
- 这是因为 MSFT 尽早地停止了对已收敛任务的训练,减少了无效计算。
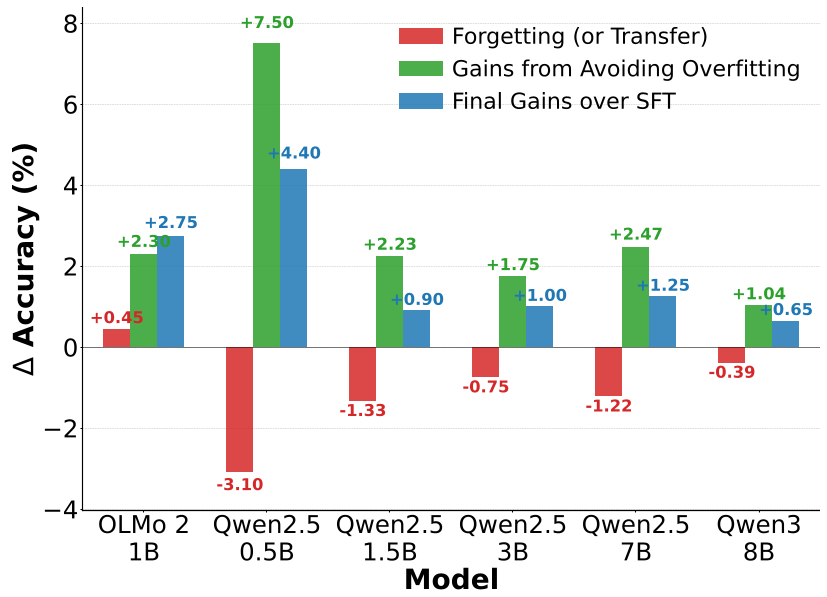
深度洞察:为什么 MSFT 有效?
除了防止过拟合,论文还揭示了一个有趣的物理现象:缓解梯度冲突。
从图 9 的训练损失曲线可以看到,在排除掉过拟合子集(垂直虚线)后,剩余任务的训练 Loss 往往会出现一个阶梯式下降。
Insight: 过拟合的任务会产生“嘈杂且过度特化”的梯度。剔除它们就像是去掉了系统中的噪音,让优化器能够集中精力处理那些还没学透的困难任务。
总结与启示
MSFT 为多任务 SFT 提供了一个极其务实的视角:承认不同数据的不均衡,并用参数回滚来应对这种不均衡。
局限性:虽然 MSFT 节省了计算 FLOPs,但它需要频繁保存 intermediate checkpoints 以备回滚,这意味着存储成本会上升(实测约为 SFT 的 4.4 倍)。但正如作者所说,在现代大模型训练中,比起珍贵的 GPU 算力,磁盘空间通常是最廉价的资源。
对于未来的模型微调,MSFT 的成功在暗示:数据调度逻辑的精细化,其回报可能远超模型结构的微调。