本文提出了 MFS,一种针对大语言模型(LLM)推理服务的全阶段多级流调度框架。该框架通过 Disaggregated 架构下的 KV-cache 检索、集合通信和 P2D 传输的协同调度,利用 Defer-and-Promote 机制优化了首字延迟(TTFT),使 TTFT SLO 达标率提升了 1.2-2.4 倍。
TL;DR
在 LLM 服务中,首字延迟(TTFT)是用户体验的核心。然而,现代推理架构(如预填充-解码分离、KV 缓存重用)引入了极其复杂的网络竞争。本文提出的 MFS (Multi-stage Flow Scheduling) 突破了传统“阶段无关”调度的局限,通过**反向多级队列(RMLQ)和延迟晋升(Defer-and-Promote)**机制,实现了网络带宽的极致精确分配,将 TTFT 的 SLO 达标率提升了最高 2.4 倍。
1. 痛点:被忽视的网络内战
在分布式 LLM 推理中,生成第一个 token 需要经历三个关键通信阶段:
- KV-cache 检索:从远程节点抓取可复用的上下文。
- 集合通信 (Collective):模型并行(如 All-to-All)时的中间激活值同步。
- P2D 传输:将预填充结果发送给解码节点。
核心矛盾在于:这些流在物理链路上是重叠且竞争的。
- 请求内竞争 (Intra-request):本层的集合通信(阻塞计算)被下一层的 KV 预取阻塞。
- 请求间竞争 (Inter-request):不同请求的流在交换机处“打架”。
现有的调度器(如 SJF 或 EDF)往往只看单个流的大小或截止日期,缺乏全局视角。正如论文所指出的,这种“阶段盲目性”是导致 40% 服务超时的罪魁祸首。
2. 核心直觉:从“暗盒”到“透视”
作者提出了一个深刻的洞见:LLM 预填充的执行过程,实际上是请求截止日期逐层“具象化”的过程。
- 早期阶段(Stage 1&2):截止日期是隐式的,因为后续还有很多层要跑。
- 最终阶段(Stage 3):截止日期是显式的,直接对应 TTFT 目标。
基于此,MFS 确立了 Defer-and-Promote(延迟与晋升) 原则:
- 先延迟:初始时将所有流放在低优先级。
- 后晋升:随着“松弛时间”(Laxity)减少,或者计算迫切需要该数据时,才向上晋升优先级。
3. 架构解析:反向多级队列 (RMLQ)
传统的多级反馈队列(MLFQ)随时间推移降低优先级,而 MFS 的 RMLQ 恰恰相反。
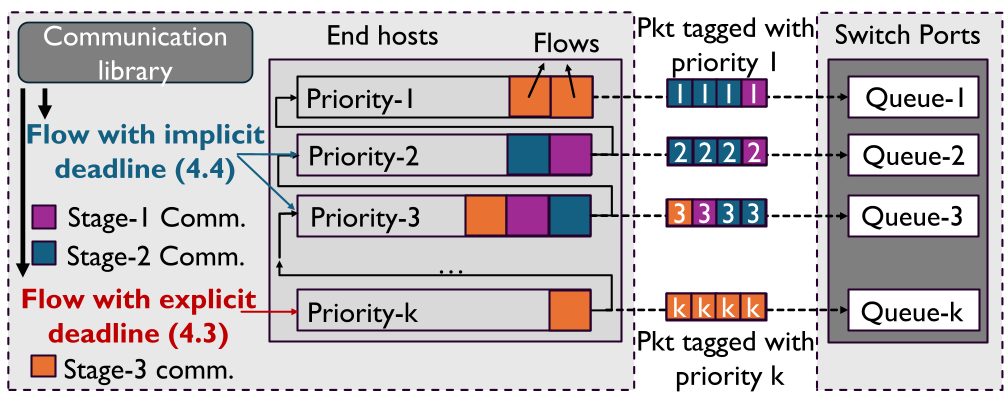
3.1 显式截止日期调度 (Stage 3)
利用 最小链路利用率 (MLU) 作为指标: $$MLU(t) = \frac{Size_{rem}(t)}{Time_{rem}(t) \cdot B \cdot (1-\rho)}$$ 当 $MLU$ 接近 1 时,意味着必须全速传输才能赶上截止日期,此时强制晋升。
3.2 隐式截止日期调度 (Stage 1&2)
引入 相对层索引 (RLI):$RLI = L_{target} - L_{curr}$。
- $RLI = 0$:表示该通信直接阻塞当前计算,优先级最高。
- $RLI > 0$:表示是“前瞻性”传输,可以适度延迟。
为了应对不确定性,MFS 还加入了鲁棒有效截止日期 (RED) 机制,防止个别极短截止日期的请求“绑架”整个 Batch 的优先级(Piggyback Effect)。
4. 实验战绩
作者在 32 个 GPU 的真实测试床上进行了验证,并使用了 Qwen 生产环境的真实 Trace。
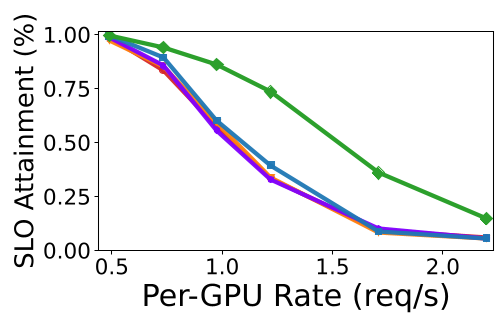
4.1 性能飞跃
在 DBRX 和 Mixtral 等主流 MoE 模型上,MFS 在中高负载下的 TTFT SLO 达标率显著超过了 Karuna 和 EDF 等基准。
4.2 为什么有效?
通过微观分析(Micro-benchmarks),MFS 成功将集合通信的非重叠时间缩短了 50% 以上。它通过精准的“延迟”非紧急流,为关键路径上的集合通信腾出了宝贵的带宽“红利”。
5. 资深主编点评
MFS 的价值在于它不是一个纯粹的算法改进,而是对 AI 任务语义与底层网络协议的一次深度解耦与重构。
- 工业界启示:在构建大规模算力集群时,单纯堆砌带宽(Scale-up)边际效应在递减。MFS 证明了通过软件层面的“阶段感知”调度,可以在现有硬件上挖掘出巨大的 SLO 潜能。
- 局限性:该方法高度依赖于对计算时间的准确评估。虽然论文中提到 20% 的误差可控,但在极其动态的 Agent 场景下,这种预测挑战依然巨大。
总结: MFS 是 LLM 推理走向毫秒级响应、强实时保障的重要基石,为未来超大规模分布式推理系统的网络协同提供了清晰的蓝图。