本文提出了 Object Pose Transformer (OPT-Pose),这是一个统一的单次前向推理框架,旨在解决未知实例(Unseen Objects)的物体姿态估计。该方法通过一个多任务 Transformer 模型,同时支持类别级绝对姿态(SA(3))和跨视图相对姿态(SE(3))的估计,在不需要 CAD 模型或特定类别标签的情况下,在 NOCS、HouseCat6D 等多个主流 Benchmark 上刷新了 SOTA 记录。
TL;DR
长期以来,物体姿态估计领域被分裂为两个孤岛:类别级绝对姿态估计(虽然能定绝对位置,但需要知道物体是什么类别)和两视图相对姿态估计(虽然通用,但定不了绝对坐标)。本文提出的 OPT-Pose 首次通过一个多任务 Transformer 模型打破了这一隔阂。它不需要 CAD 模型,不需要推理时的类别标签,就能同时完成 SA(3) 绝对姿态和 SE(3) 相对姿态预测,且支持 RGB/RGB-D 灵活切换。
1. 行业痛点:分类体系的“牢笼”与几何信息的“缺失”
在自动驾驶或机器人抓取(Robotic Manipulation)中,我们经常遇到从未见过的物体。
- 类别级方法(Category-level):如 GCE-Pose,它们虽然能预测 NOCS 坐标,但极度依赖推理时的已知类别优先级(Prior)。如果遇到一个分类体系之外的物体,模型往往会失效。
- 相对姿态方法(Relative Pose):如 OnePose++,能够通过匹配两个视角图像来算相对变换,但如果你只给它一张图,它无法告诉你这个物体相对于相机的绝对距离和朝向。
OPT-Pose 的核心 Insight 是: 任务分解(Task Factorization)。通过同时预测深度(Depth)、规范坐标(NOCS)和点图(Point Map),可以利用几何冗余消除歧义。
2. 核心架构:多头几何预测与潜键点融合
OPT-Pose 的模型结构是一个典型的 Encoder-Decoder-Heads 架构:
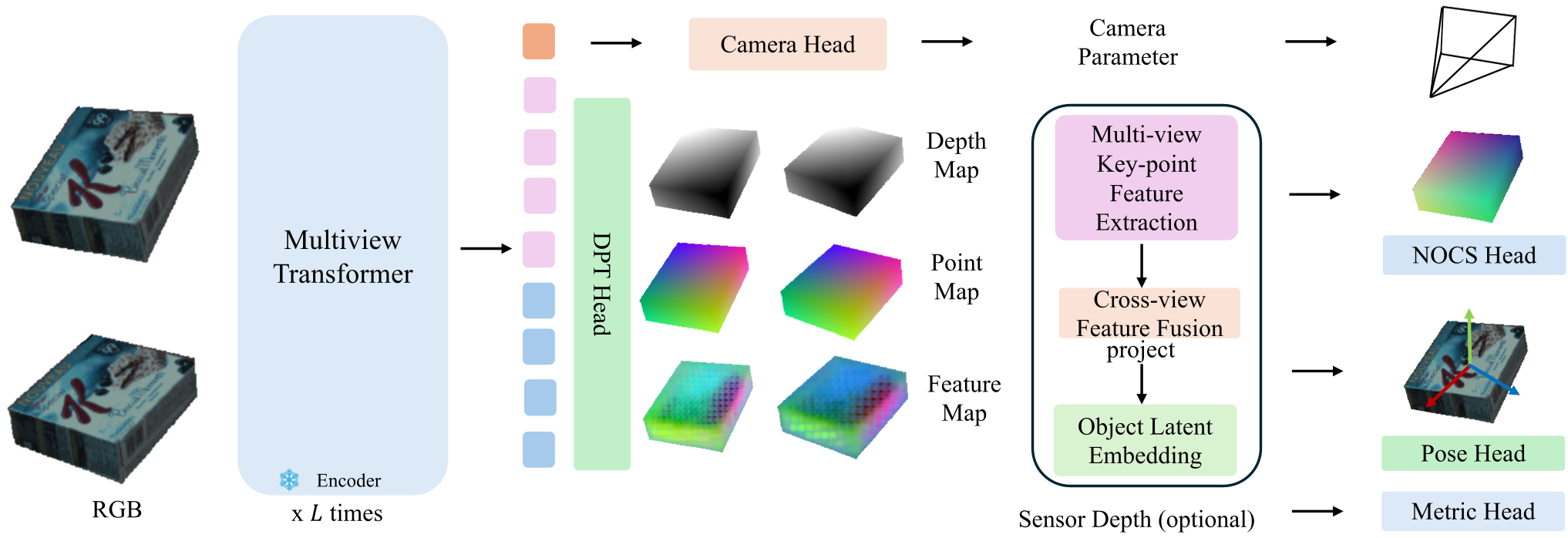
2.1 任务分解支路
- 支路 A (Depth + NOCS):将实例对齐到共享的规范空间(Canonical Space),从而找回绝对姿态。
- 支路 B (Depth + Point Map):在相机空间(Camera Space)中表示物体,支持跨帧的几何约束推理。
2.2 类别无关的规范化(Category-Agnostic Canonicalization)
为了摆脱对类别标签的依赖,作者引入了对比学习(Contrastive Learning)。通过 InfoNCE Loss,模型学习将同一物体的不同视角表征拉近,不同物体的表征推远。这种潜空间嵌入(Object Latent Embedding)作为 FiLM 层的输入来调节 NOCS 头部,使得模型在没有类别名称的情况下也能自主学习“物体的标准朝向”。
3. 实验结果:统治级的性能提升
在 REAL275、HouseCat6D、Omni6DPose 等多个数据集上,OPT-Pose 展现了极强的通用性。
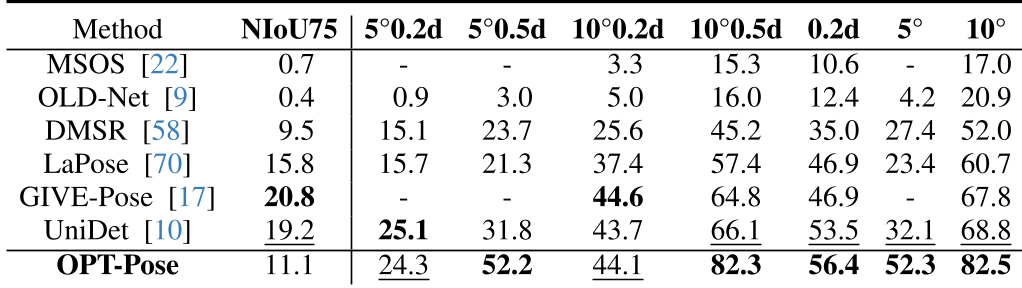
- 性能跨越:在 REAL275 数据集中,OPT-Pose 在 10°0.5d 的综合指标下达到了 82.3%,而此前的 SOTA 方法 UniDet 仅为 66.1%。
- 多视图红利:研究发现,随着输入视图 S 的增加(从 1 增加到 4),绝对姿态的估计精度持续上升。这说明模型成功利用了跨视图的几何一致性来修正单图预测中的噪声。
4. 深度洞察:为什么它有效?
OPT-Pose 成功的本质在于它处理了尺度歧义性(Scale Ambiguity)。
- 在 RGB 模式下,模型通过一个轻量级的 log-scale 预测头配合全局视觉特征来预测尺度。
- 在 RGB-D 模式下,模型可以实时利用传感器深度提取度量尺寸(Metric Scale)。 这种对不同输入模态的解耦设计,使得 OPT-Pose 成为了目前业界最灵活的姿态估计框架之一。
5. 总结与展望
Takeaway: OPT-Pose 不仅仅是一个更高精度的刷榜模型,它更重要的是提出了一个统一的几何路径感知识别框架。
局限性:尽管表现卓越,OPT-Pose 目前仍依赖于物体中心的裁剪图(Object-centric crops),且在剧烈光照变化下性能会有所下降。未来的研究方向可能包括大规模数据的预训练(Scaling Law 在姿态领域的应用)以及如何将该框架直接集成到端到端的机器人操作链中。
学术地位:该论文在 2026 年的姿态估计领域具有里程碑意义,通过任务分解完美融合了此前长达数年的两条并行技术路线。