本文提出了 ReVal,一种面向大语言模型(LLM)的离策略(Off-Policy)价值强化学习框架。该方法通过将 LLM 的 Logits 解释为 Q 值,实现了策略与价值模型的统一,并引入经验回放机制(Replay Buffer),显著提升了数据利用率,在数学推理任务上超越了主流的 GRPO 方法。
TL;DR
南京大学等机构的研究者提出 ReVal,成功打破了 LLM 强化学习中“一次性采样”的魔咒。通过将模型 Logits 映射为 Q 值并引入 经验回放 (Replay Buffer),ReVal 实现了真正的离策略 (Off-policy) 学习。实验显示,它不仅在收敛速度上比 GRPO 快 4 倍以上,更在 AIME 和 GPQA 等硬核推理榜单上取得了显著的 SOTA 提升。
1. 痛点:为什么 LLM 的强化学习这么费钱?
当前的 LLM 后训练(Post-training)大多遵循 On-policy 范式。这意味着:
- 模型每生成一万条回复(Rollout),更新一次参数后,这些数据就“过期”了。
- 在长链推理(CoT)或 Agent 任务中,生成过程极其缓慢且昂贵。
- 采样(Generation)损耗 往往占到总训练成本的 80% 以上。
虽然 Classical RL 中有成熟的离策略方法(如 Q-Learning),但直接迁移到 LLM 面临两大难题:
- 参数化困境:LLM 词表规模巨大,从零开始训练一个独立的 Q 值网络(Value Model)内存开销巨大。
- 初始化不稳:如果 Q 值初始化不好,模型在训练初期会迅速崩坏。
2. 核心直觉:Logits 即价值
ReVal 的核心思想继承自“预训练模型隐含了价值信息”。作者认为,LLM 的 Logits 并不只是概率,它本质上是对未来奖励的预期(Soft Q-values)。
2.1 架构设计
ReVal 抛弃了独立的 Critic 网络,实现了 单一模型架构 (Single-model Architecture)。
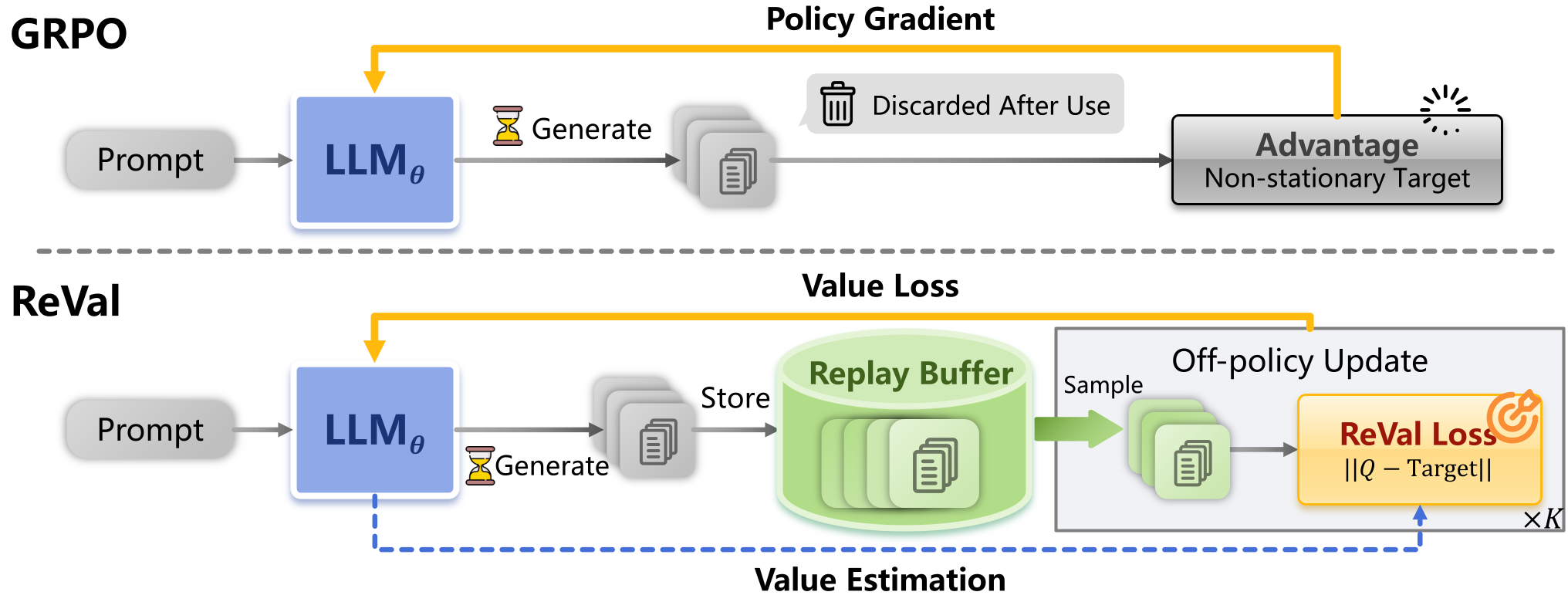 图 1:ReVal 框架图。通过将 Logits 解释为 Q 值,统一了策略与价值函数。
图 1:ReVal 框架图。通过将 Logits 解释为 Q 值,统一了策略与价值函数。
2.2 解决了 TBRM 的“校准”缺陷
前人工作如 TBRM 尝试过类似路径,但 ReVal 指出其存在 Calibration(校准) 问题:当奖励为 0 时,TBRM 无法收敛回参考策略。ReVal 通过引入 奖励重塑 (Reward Shaping) 公式解决了这一点: 这个公式确保了初始状态下的稳定性,是模型能跑通 Off-policy 的关键。
3. 经验回放:数据复用的威力
ReVal 引入了 FIFO 经验池。在每一轮迭代中:
- 收集少量新样本存入 Buffer。
- 从 Buffer 中随机抽取旧样本进行 多次更新 (K updates)。
实验证明,这种对“死数据”的深度压榨,让模型在看到相同数量的样本时,进步幅度远超 GRPO。
4. 实验结果:速度与精度的双重飞跃
4.1 收敛加速
在单样本任务中,ReVal 到达相同性能阈值的速度比 GRPO 快 3.6x 到 5.2x。这直接意味着在相同算力下,我们可以训练更强的模型。
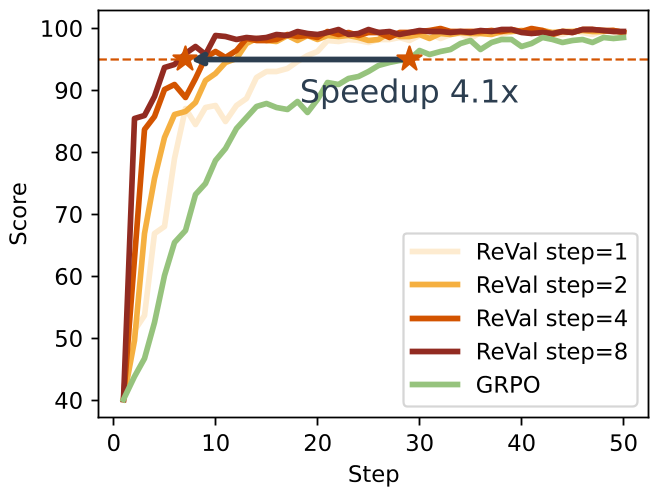 图 2:不同难度任务下,ReVal (多步更新) 与 GRPO 的收敛速度对比。
图 2:不同难度任务下,ReVal (多步更新) 与 GRPO 的收敛速度对比。
4.2 综合战绩
在 DeepSeek-R1-Distill-1.5B 上的表现尤其惊艳。即使在极端的 Limited Rollouts (N=1) 设定下,ReVal 的优势依然稳固,证明了其在资源受限场景下的巨大价值。
| 模型 | AIME24 | GPQA (OOD) | 平均提升 | | :--- | :---: | :---: | :---: | | GRPO 基线 | 29.4 | 28.8 | - | | ReVal (本文) | 32.1 | 33.3 | +2.2 |
5. 深度洞察:关键超参数
- 的魔力: 控制了奖励的强度与 KL 约束。作者发现,对于推理路径更长的模型(如 R1-Distill),需要更小的 (如 0.002)来维持稳定。
- 负向样本的利用:ReVal 证明了使用 归一化优势 (Normalized Advantage) 作为奖励信号,比简单的 0/1 奖励更能帮助模型规避错误。
6. 总结与局限
ReVal 为 LLM 的强化学习指明了一个新方向:不要只盯着 Policy Gradient,价值基 Off-policy 方法在样本效率上有着天然的代差优势。
局限性:尽管加速明显,但目前 ReVal 使用的是简单的 FIFO Buffer。如果引入 优先经验回放 (Prioritized Experience Replay),即让模型多学习那些“犯错”或“高价值”的旧样本,性能上限可能还会被进一步推高。
Takeaway: 离策略训练不再是分布式 RL 的专属,它是解决长序列推理采样开销的必经之路。