本文提出了针对旅行商问题 (TSP) 的离线决策 Transformer 框架,通过引入 Pointer Network 处理可变动作空间,并利用期望分位数回归 (Expectile Regression) 进行乐观的待获得回报 (Return-to-Go, RTG) 预测。该方法仅通过学习现有的启发式算法数据集,即可在推理时生成超越原始启发式算法的高质量解。
TL;DR
旅行商问题 (TSP) 是工业界的常客,但其 NP-hard 的本质一直让研究者在“效率”与“精度”间权衡。本文另辟蹊径,不再追求复杂的在线强化学习,而是通过 Offline RL (离线强化学习) 框架——Decision Transformer (DT),直接从现有的启发式算法(如 Nearest Neighbor)中“学习并进化”。实验证明,该模型不仅能学会这些算法,更能通过期望分位数回归实现“青出于蓝而胜于蓝”。
背景定位:从模仿到超越
传统的神经组合优化 (NCO) 通常被视为一个搜索问题,依赖 Actor-Critic 等在线 RL 算法。然而,在线学习需要昂贵的交互成本。本文的切入点非常精妙:既然人类已经研究了几十年的启发式算法(Heuristics),为什么不直接把这些算法生成的大量解作为“离线数据”,让模型在这些数据中寻找更优的路径模式?
这不仅仅是 Behavior Cloning (行为克隆)。行为克隆只能学会平均水平,而本文的目标是通过 DT 的序列建模能力,拼接出比任何单一启发式算法都更短的巡回路径。
核心痛点:为什么传统的 DT 不能直接用?
- 动作语义缺失:在游戏中,“向上走”是有确定含义的。但在 TSP 中,节点 5 和节点 10 的索引是随机的,缺乏跨实例的语义一致性。
- 回报分布波动大:不同 TSP 实例的最优路径长度完全不同,设置一个统一的 RTG (Return-to-Go) 目标会导致模型外推失败。
方法论详解:DT 的 TSP 改造工程
1. Pointer Network 的集成
为了解决节点选择的灵活性问题,作者将 Pointer Network 整合进 DT。不再是预测固定的分类概率,而是根据当前解码器的隐藏状态与 Encoder 输出的节点嵌入进行 Attention 计算,从而“指向”下一个候选节点。
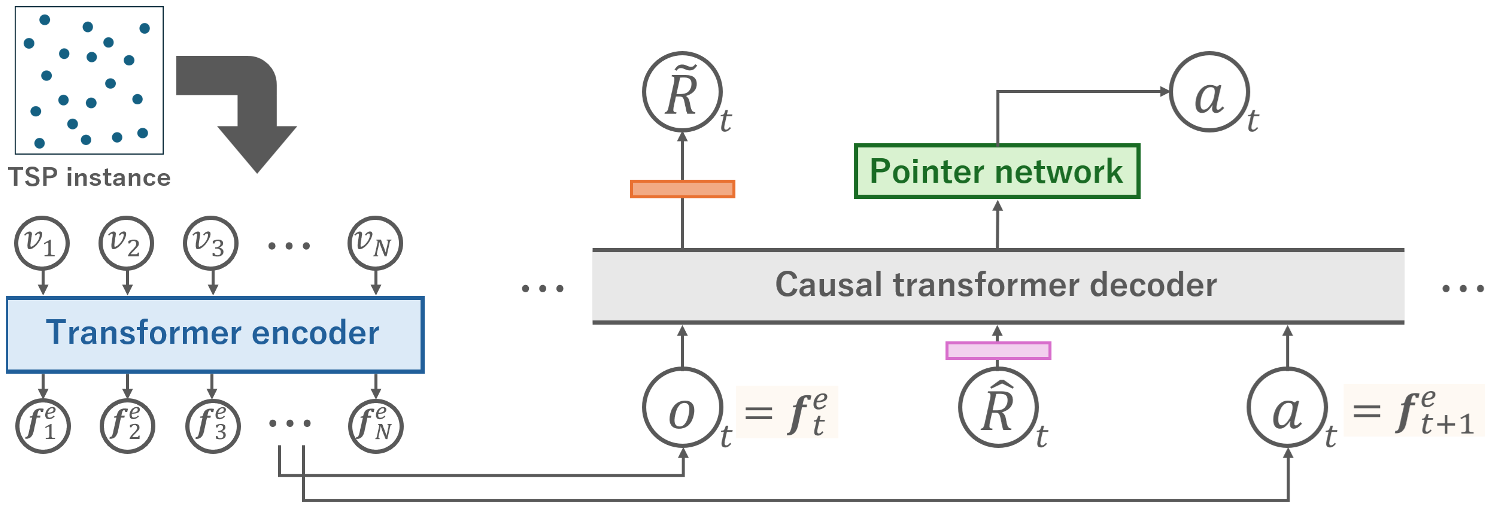
2. 乐观的 RTG 预测机制
这是本文能在性能上“青出于蓝”的关键。作者引入了 Expectile Regression (期望分位数回归)。
- 物理直觉:通过设置较高的分位数系数 $\alpha=0.99$,强制模型在训练时预测“可能达到的最大收益”。
- 推理策略:在推理阶段,模型先预测一个乐观的 RTG 值(即极短的路径长度),并以此为“死命令”条件化后续的动作选择。这使得模型在决策时会倾向于选择那些导向卓越解的动作轨迹。
实验结果:全方位的降维打击
作者在 N=20, 50, 100 三种规模的 2D 欧几里得 TSP 上进行了验证。
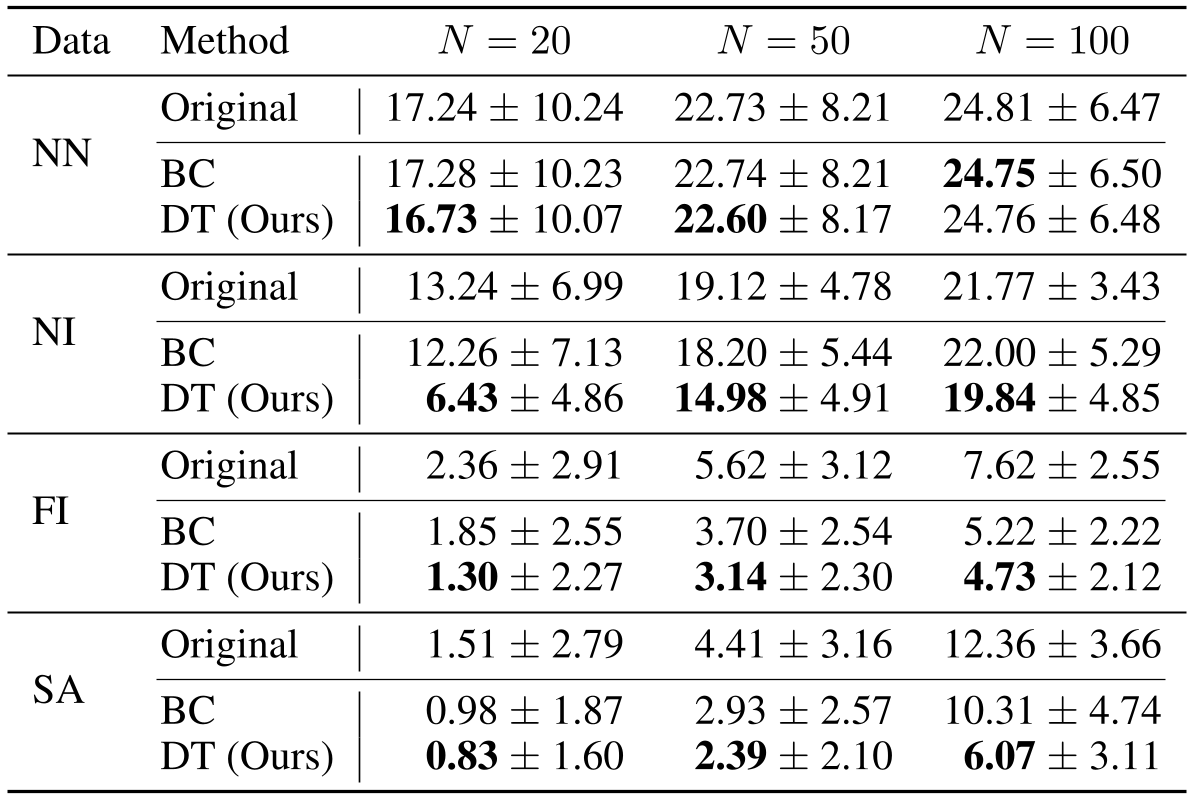
关键洞察:
- 超越 Baseline:模型生成的解一致优于它所学习的四种启发式算法。特别是在 SA(模拟退火)数据集上,由于 SA 解的多样性更高,DT 展现了极强的“精华提取”能力,显著降低了 Optimality Gap。
- 对抗 BC:行为克隆 (BC) 的表现仅能勉强持平或略微改进原始算法,而带预测 RTG 的 DT 则展现了跨越式的性能提升。
深度洞察与总结
本文最令人兴奋的结论在于:离线强化学习可以作为一种强大的算法合成器。
局限性
- 多样性依赖:如果训练数据过于刻板(如简单的 NN 算法),模型的提升空间会受到限制。
- 外推瓶颈:实验显示,手动给 RTG 增加一个 Offset 有时还能提升性能,说明模型预测的“乐观目标”可能还不够大胆。
未来展望
这项技术对物流调度、芯片布线等领域具有直接的工程意义。未来可以将多种启发式算法的解混合训练,甚至加入人类专家的手动修正方案,利用 Transformer 强大的序列建模能力合成一套前所未有的“超级启发式策略”。
Takeaway: 别再只盯着在线 RL 的收敛曲线了,离线数据里藏着通往 SOTA 的捷径。