Omni-WorldBench is a novel, interaction-centric evaluation benchmark for 4D video-based world models, comprising the hierarchical prompt suite Omni-WorldSuite and the agent-based evaluation framework Omni-Metrics. It establishes a comprehensive standard by evaluating 18 representative models across three interaction levels, focusing on causal consistency and interactive response rather than just visual fidelity.
TL;DR
Omni-WorldBench is the first comprehensive benchmark designed to evaluate interactive response in 4D world models. Moving beyond mere visual fidelity, it introduces a three-level interaction hierarchy and an agent-based evaluation protocol (Omni-Metrics) to quantify how faithfully a model simulates environment state transitions under specific actions. The study reveals that even SOTA models struggle with the transition from "generating pretty videos" to "simulating consistent physical reality."
Background: The Interaction Gap
We are witnessing a paradigm shift where video generation models (like OpenAI's Sora or Kuaishou's Wan) are being rebranded as "World Models." However, a true world model isn't just a movie generator; it is a simulator of dynamics. Most existing benchmarks like VBench focus on what a video looks like (FID, FVD), but ignore how the environment responds to an agent's intervention.
Omni-WorldBench fills this void by defining the "Interactive Response" as the core capability of a world model, pinpointing the current research's blind spot: the causal impact of actions on 4D (spatial + temporal) evolution.
Methodology: Hierarchy and Agentic Evaluation
1. Omni-WorldSuite: The Hierarchical Taxonomy
The researchers constructed a suite of 1,068 prompts categorized by the Scope of Interaction:
- Level 1 (Acting Object): Effects are confined to the primary object (e.g., a hand moving).
- Level 2 (Local Environment): One object affects another (e.g., a ball hitting a pin).
- Level 3 (Global Environment): Actions induce broad, multi-object changes (e.g., tidying a chaotic room).
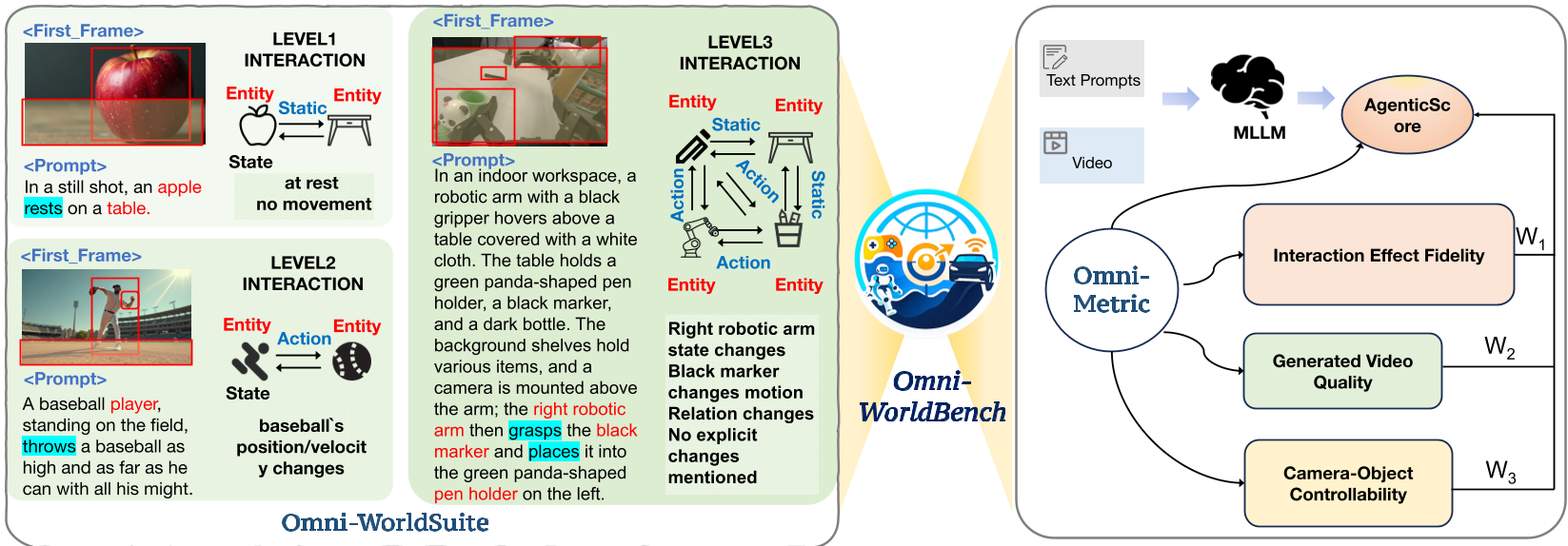
2. Omni-Metrics: Beyond Pixel Comparison
To judge these models, the authors moved away from simple frame-diffing. They introduced Interaction Effect Fidelity, which includes:
- InterOrder: Uses a Vision-Language Model (VLM) to verify if events happen in the correct causal chronological order.
- InterStab-N: Measures if "unaffected" regions stay stable (preventing hallucinated movements in the background).
- AgenticScore: Instead of a flat average, an MLLM analyzes the prompt to decide if camera control is more important than physical consistency for that specific scenario, weighting the final score adaptively.
Experimental Insights: SOTA is Not Enough
The team benchmarked 18 models (T2V, IT2V, and Camera-Conditioned).
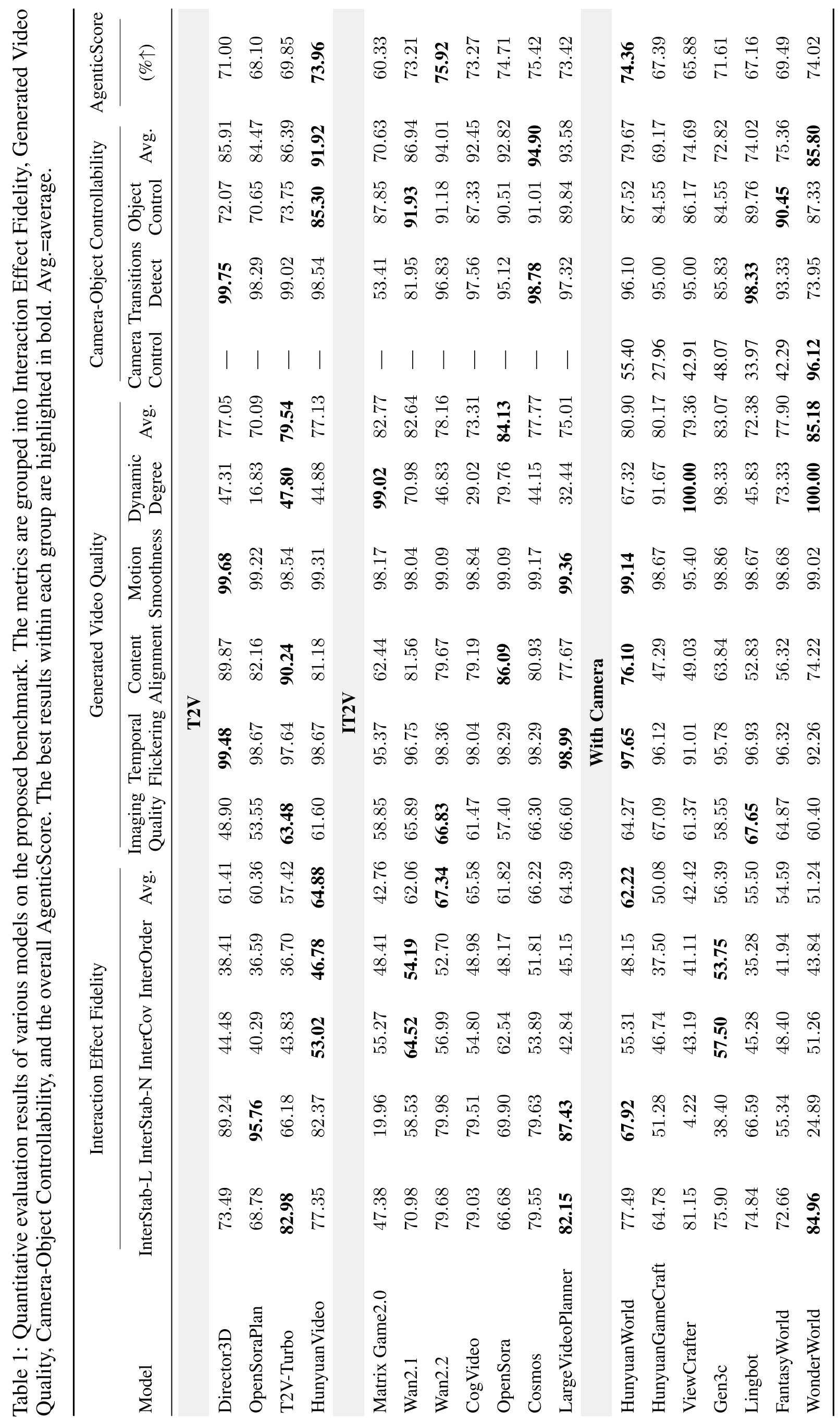
Key Findings:
- The IT2V Advantage: Image-to-Video models (like Wan2.2 and Cosmos) significantly outperform Text-to-Video models because the initial frame provides a "spatial anchor" that helps maintain physical consistency.
- The "Visual Mirage": Many models score >95% on temporal smoothness but fail miserably on InterOrder and InterCov. They can generate smooth motion, but that motion is often "detached" from the causal logic of the prompt.
- Catastrophic Collapses: In high-dynamic tasks like throwing a baseball, models like Matrix-Game2.0 showed "catastrophic collapse," where human figures dissolved into artifacts because the model couldn't reconcile the complex 4D interaction.

Critical Analysis & Conclusion
Omni-WorldBench exposes a harsh reality: we are still far from a "World Simulator." Current models are excellent interpolators of visual pixels but poor reasoners of physical causality.
Takeaways for Researchers:
- Prioritize Causality: Future architectures must integrate better structural priors to handle the "agent-to-object" causal chain.
- Evaluation Reform: Stop relying on FVD/FID. High visual fidelity often masks a complete lack of world understanding.
- Stability is Key: Maintaining non-target region stability (InterStab-N) is a major hurdle for camera-conditioned models that often "hallucinate" new geometry during movement.
Omni-WorldBench sets a rigorous new floor for what constitutes a "World Model," ensuring that the next generation of AI is judged not just on its artistic flair, but on its ability to faithfully simulate our reality.