本文推出了 Omni-WorldBench,这是首个专门针对视频世界模型(World Models)交互响应能力设计的综合性评估基准。该基准包含层次化的提示词套件 Omni-WorldSuite 和基于智能体(Agent-based)的评估框架 Omni-Metrics,填补了现有指标在 4D 空间演化和因果一致性评价上的空白。
TL;DR
在视频生成领域,我们不仅需要视觉上的“精美”,更需要物理上的“逻辑”。阿里巴巴大地图(AMAP)团队联合中科院、北航等机构提出了 Omni-WorldBench,这是第一个拒绝“花架子”、硬核测试世界模型交互响应能力的基准测试。它通过 1,068 个精心设计的 Prompt 和一套基于 Agent 的自动化评分系统,戳破了当前 SOTA 模型在因果推理和物理模拟上的“幻觉”。
痛点深挖:视频生成不等于“模拟世界”
当前的视频生成模型(如 Sora 等)虽然能产出极具视觉冲击力的影像,但在学术界看来,它们距离真正的“世界模型”还有代差。
- 维度缺失:现有的 VBench 等偏向视觉质量,而 WorldScore 偏向相机的 3D 几何一致性。
- 因果断裂:当给出一个“打碎杯子”的指令时,模型往往能画出破碎的瞬间,却难以维持碎片在空间中的逻辑延续性,或是无法处理交互动作导致的局部环境连锁反应。
- 难以量化:如何科学地衡量一个模型是否“听懂”了复杂的物理交互指令?这是一个长期存在的学术空白。
核心架构:Omni-WorldSuite 与三级交互
作者认为,交互的深度决定了世界模型的上限。为此,他们将交互分为三个层级:
- Level 1 (Acting Object):动作仅涉及主体。例如:人在草地上走动。
- Level 2 (Object-to-Object):物体影响另一个物体。例如:球棒击中棒球。
- Level 3 (Global/Environment):复杂的因果链,改变整个场景。例如:整理杂乱的房间。
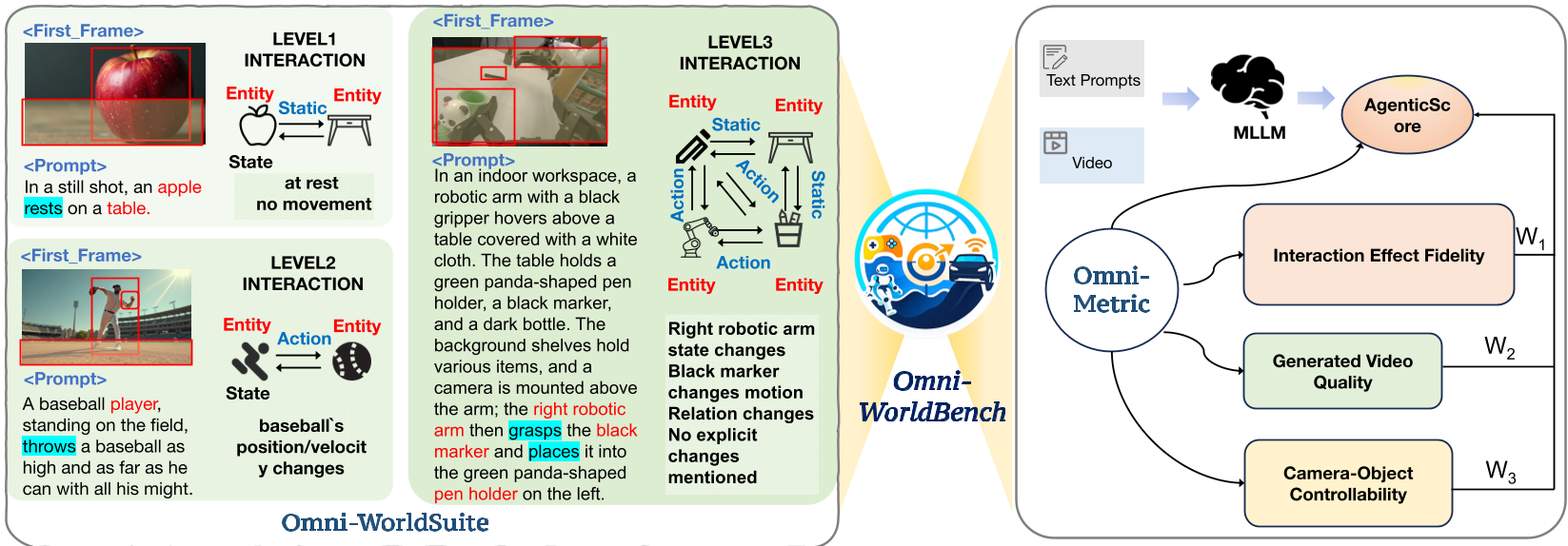 图 1:Omni-WorldBench 概览。左侧为提示词套件的分级定义,右侧为基于 Agent 的评分流。
图 1:Omni-WorldBench 概览。左侧为提示词套件的分级定义,右侧为基于 Agent 的评分流。
方法论:Omni-Metrics 与 AgenticScore
为了实现全方位评估,Omni-Metrics 引入了四个反映“交互忠实度”的核心指标:
- InterStab-L:长程稳定性,检查视频在经历一段动作后重回初始位置时,场景是否变形。
- InterStab-N:非目标区稳定性,如果你在挥拳,背景的房子不应该抖动。
- InterCov:动作覆盖率,利用 VLM 验证受影响实体是否产生了预期的语义响应。
- InterOrder:判别事件发生的先后顺序是否符合物理逻辑(如:必须先点火再起烟)。
最精妙的设计在于 AgenticScore:系统不再死板地对所有指标取平均值,而是通过一个 MLLM(多模态大模型)作为“主考官”,根据 Prompt 的侧重点(是看重相机控制还是看重物理因果)自动调整各项指标的权重。
实验战绩:谁才是真正的 4D 霸主?
研究团队对 18 个模型进行了大规模评测,包括 Wan 2.2、Cosmos、HunyuanVideo 等。
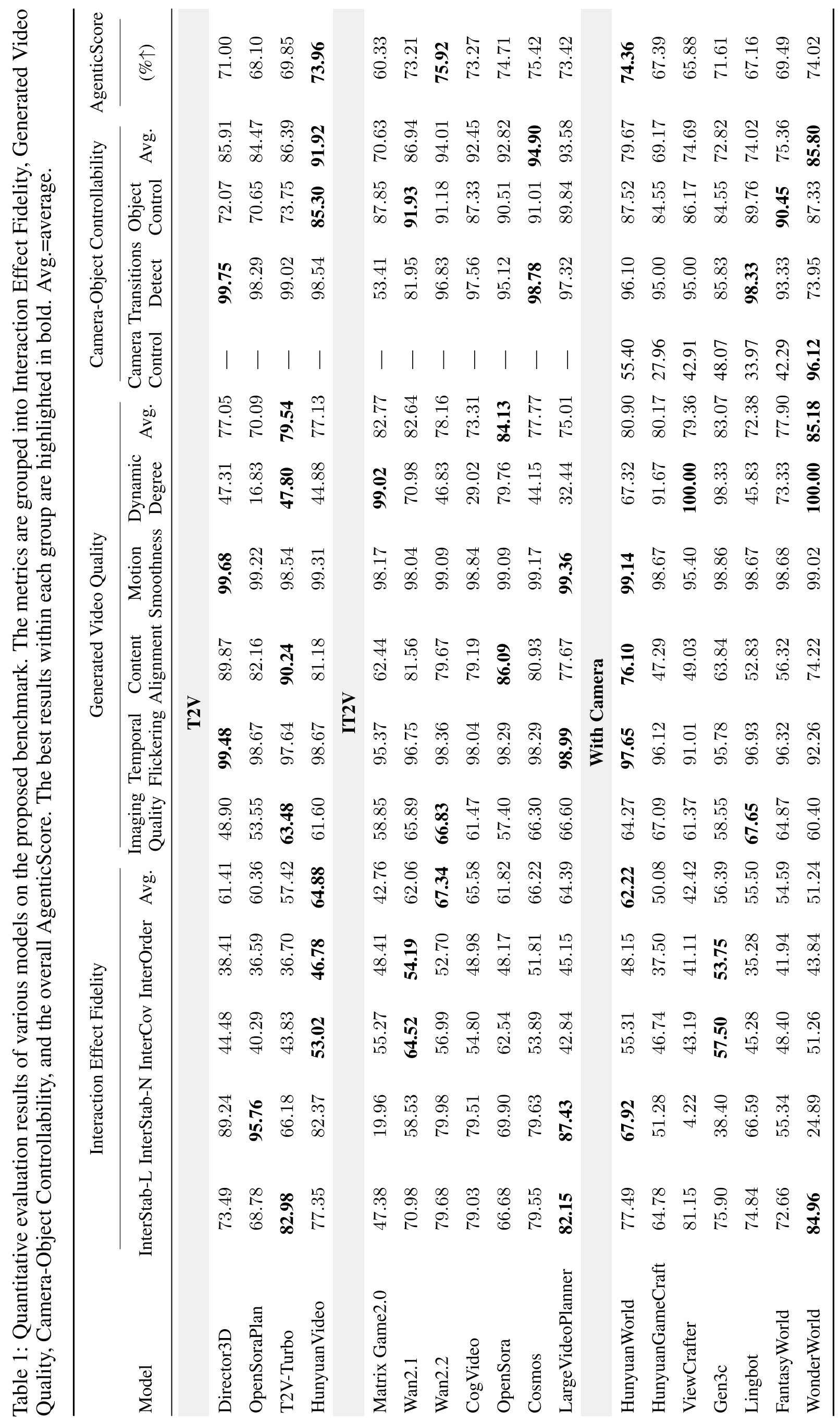 表 1:各模型在交互忠实度、视觉质量、可控性上的量化表现。
表 1:各模型在交互忠实度、视觉质量、可控性上的量化表现。
关键发现:
- IT2V (Image-to-Video) 展现潜力:相比纯文本生成,给模型一张初始帧(Image prompt)能大幅提升其交互稳定性。Wan 2.2 在多项指标上刷榜。
- 物理认知的缺失:在图 5 的对比中可以明显看到,某些模型在生成“强力投球”动作时,人体由于无法承载复杂的运动学逻辑,直接发生了“塌陷”和消失。
- 相机与动态的权衡:类似于 WonderWorld 这样的模型在相机控制(Camera Control)上拿到了近乎满分,但在处理非目标区域的稳定性(InterStab-N)上表现糟糕,说明模型在追求大幅度相机运动时,难以兼顾背景的物理静止。
 图 2:Wan2.2 与 Matrix-Game2.0 在复杂物理动作下的表现差异。
图 2:Wan2.2 与 Matrix-Game2.0 在复杂物理动作下的表现差异。
深度洞察与总结
Omni-WorldBench 的出现标志着视频生成评估进入了 “因果时代”。
- 价值:它揭示了当前 SOTA 模型虽然能通过“补帧”骗过人的眼睛,但无法通过“物理一致性”骗过逻辑验证。
- 展望:未来的 4D 世界模型需要更紧密地耦合感知、动作与物理规律。对于机器人、自动驾驶等安全敏感领域,Omni-WorldBench 提供的这套评估框架将成为不可或缺的准入标准。
正如作者在结论中所述:“视觉保真度已成基操,交互响应才是未来。”