本文提出了 OmniVTA,这是一个基于世界模型的视触觉(Visuo-Tactile)机器人操控框架,以及一个包含 2.1 万余条轨迹的大规模数据集 OmniViTac。该框架通过一个自监督触觉编码器、双流视触觉世界模型以及 60Hz 的反射式控制器,实现了对接触密集型任务(如擦拭、组装、切割)的高精度闭环控制。
TL;DR
传统的机器人视觉操控在遇到“擦拭”、“切割”或“精细组装”这类需要实时感知力量变化的接触密集型任务(Contact-Rich Tasks)时常常力不从心。本文通过提出 OmniVTA 框架,将“大脑”的预见性控制(世界模型预测)与“脊髓”的反射性调节(60Hz 高频控制)结合,配合目前规模最大的真实世界视触觉数据集 OmniViTac,实现了超越人类示教水平的稳健操控。
1. 痛点深挖:为什么视觉不是万能的?
在机器人操作中,仅凭视觉(Vision-only)很难判断物体表面的摩擦力波动、细微的卡扣对齐或划动时的压力分布。
- 数据匮乏:现有的视触觉数据集规模小、任务单一(大多只是简单的抓取)。
- 认知被动:大多数算法将触觉作为普通的输入特征,就像给视觉挂了个“传感器挂件”,却没有理解触觉随动作演化的物理规律。
- 反馈滞后:主流方法通常采用 Action Chunking(动作块)策略,一旦环境发生突发扰动(如物体滑动),机器人往往要等下一个规划周期才能反应,这在精细操作中是致命的。
2. 核心架构:TactileVAE 与双流世界模型
OmniVTA 的核心逻辑在于其层次化控制策略。
2.1 TactileVAE:触觉的“隐式”表达
为了高效处理高分辨率的触觉信号,作者没有直接使用原始图像,而是提取了 3D 标志位位移,并利用 隐式神经表示(INR) 训练了一个 TactileVAE。它可以根据空间坐标采样,连续地重建触觉表面的变形场(Deformation Field)。
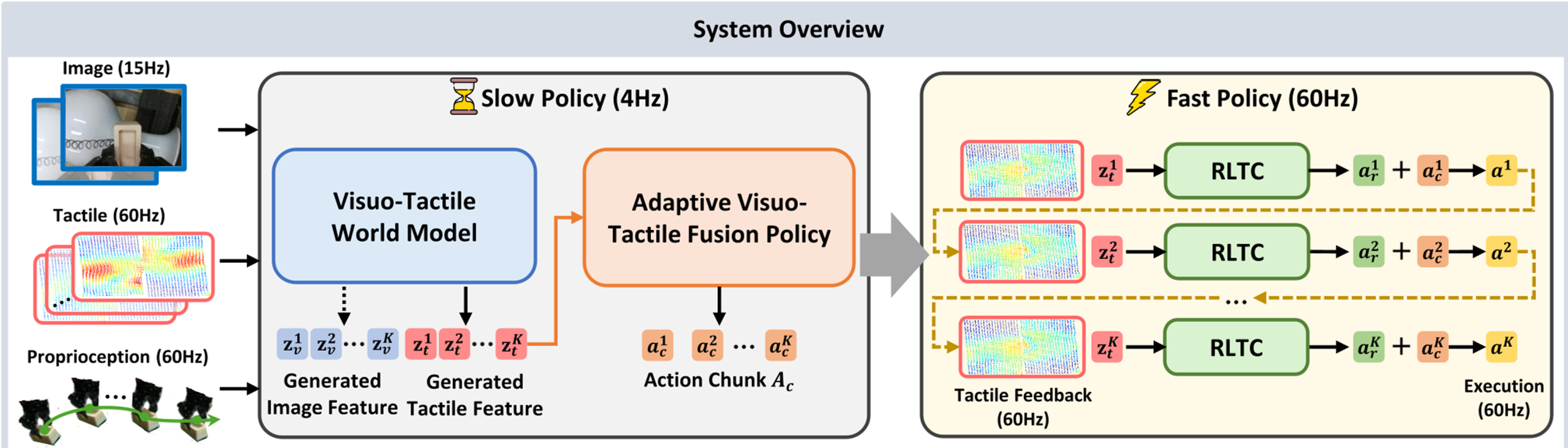 图 1:OmniVTA 框架概览,展示了从触觉编码到世界模型预测,再到闭环执行的全过程。
图 1:OmniVTA 框架概览,展示了从触觉编码到世界模型预测,再到闭环执行的全过程。
2.2 视触觉世界模型(VTWM)
作者构建了一个基于 扩散 Transformer (DiT) 的双流模型。它不仅“看”当前的图像,还能预测未来几步的视觉和触觉特征演化。这种**前馈预期(Feedforward Anticipation)**能力让机器人提前感知到即将发生的接触状态改变。
3. 操控革命:快慢结合的反射式控制
OmniVTA 借鉴了人类神经系统的“快慢系统”理论:
- 慢速规划(Slow Policy):以较低频率运行,融合预测的触觉差分(Latent Tactile Differential, LTD)生成全局动作轨迹。
- 快速反射(Fast Policy):即其提出的 Reflexive Latent Tactile Controller (RLTC),以 60Hz 的频率运行。它不断比对“世界模型预测的触觉”与“实际观测到的触觉”,如果发现出入(说明发生了偏移或扰动),立即产生极小的修正动作。
 图 2:在复杂的切割(Cut)和组装(Assembly)任务中,OmniVTA 展现了极其精确的力量控制。
图 2:在复杂的切割(Cut)和组装(Assembly)任务中,OmniVTA 展现了极其精确的力量控制。
4. 实验与实战表现
作者在六大类任务中进行了广泛测试,包括:擦拭、剥皮、切割、组装、抓取、在手调整。
- SOTA 对比:在几乎所有任务上,OmniVTA 的成功率均大幅领先于 Diffusion Policy (+50% 以上) 和 RDP 等方法。
- 扰动鲁棒性:在“擦拭”过程中突然改变物体高度,OmniVTA 能够通过 60Hz 反射控制器迅速找回接触点,而传统方法则会直接在空中“打空划”。
- 自适应融合:正如论文中图 14 所示,模型会根据接触概率自动调节视觉和触觉的权重——未接触时看视觉,接触后听触觉。
 表 1:各基线模型在复杂任务下的性能对比,OmniVTA(末行)在各项指标上均处于统治地位。
表 1:各基线模型在复杂任务下的性能对比,OmniVTA(末行)在各项指标上均处于统治地位。
5. 总结与启示
OmniVTA 的成功主要归功于其对触觉信号“空间局部性”和“接触驱动动力学”的深刻理解。它不再是机械地复现动作轨迹,而是学会了理解接触过程中的物理反馈。
局限性:尽管反射控制器大幅提升了鲁棒性,但目前世界模型的推理延迟(230ms)对于需要极速感知的极限任务(如捕捉滑落的冰块)仍有优化空间。
未来展望:OmniViTac 数据集的开源将为社区提供宝贵的燃料,未来将视触觉模型集成到更大规模的多模态大模型(VLA)中,指日可待。