本文提出了 OmniWeaving,一个实现了全任务统一(Omni-level)的视频生成框架,支持自由形式的文本、多图及视频组合输入。通过集成视觉理解与生成模块,该模型在开源领域首次实现了具备深度推理与复杂组合能力的视频生成,并在新提出的 IntelligentVBench 基准测试中达到 SOTA 性能。
TL;DR
OmniWeaving 是腾讯混元团队联合浙大、南洋理工提出的全能型视频生成框架。它不再仅仅是“你给指令,我出视频”,而是通过集成 MLLM (视觉理解) 与 MMDiT (生成),让模型具备了“先思考、再生成”的能力。它支持交织的文本、多张参考图、甚至是视频片段作为输入,打破了开源模型任务碎片化的僵局。
背景定位:这是开源界首个真正能够对标闭源系统(如 Seedance-2.0)全能生成能力的尝试,填补了复杂多模态输入与抽象推理生成的空白。
痛点深挖:为什么视频生成总是不听话?
现有的视频生成模型(如早期的 Sora 仿作或各类专业 I2V 模型)主要面临两个瓶颈:
- 架构碎片化:做 T2V 的不能做视频编辑,做图文混合输入的更是凤毛麟角。
- 缺乏物理/逻辑常识:当你输入一个抽象意图(例如“两名少女重遇走失多年的爱犬”)时,模型往往不知道该表现出怎样的惊喜、跪地、拥抱等一系列连贯的动作流。
作者认为,视频生成模型必须从“被动渲染器”进化为“思维引导的智能体”。
核心机制:OmniWeaving 的“编织”艺术
OmniWeaving 的架构设计精妙地解决了理解与生成的脱节。
1. 激活“思维模式” (Thinking Mode)
不同于传统的将 MLLM 作为静态特征提取器,OmniWeaving 会引导 MLLM 对模糊的输入进行自主推理。模型会先生成一段详细的增强型文字描述(推理链),明确空间布局和动作时序,再将其隐藏层状态交给生成后端。
2. 多层特征堆叠 (DeepStacking)
为了在生成时兼顾底层细节(如物体纹理)和高层语义(如场景氛围),作者引入了 DeepStacking 机制。从 Qwen3-VL 的第 8、16、24 层提取特征,通过 MLP 连接器直接注入 MMDiT 的前几层。
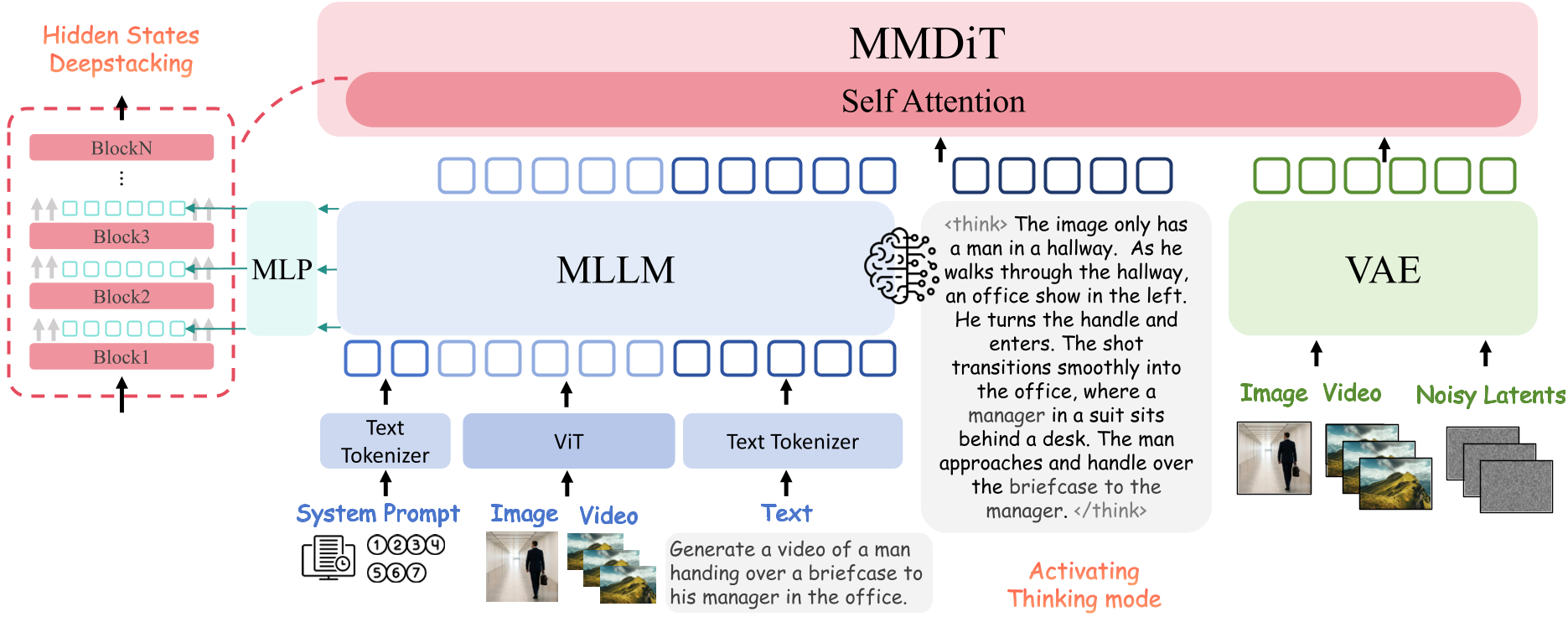 图 1:OmniWeaving 总体架构,展示了 MLLM 作为推理大脑与 MMDiT 作为生成躯干的组合。
图 1:OmniWeaving 总体架构,展示了 MLLM 作为推理大脑与 MMDiT 作为生成躯干的组合。
实验与结果:全能选手的硬核实力
作者不仅提出了模型,还推出了 IntelligentVBench,这是首个专门针对“高阶推理”和“自由形式组合”设计的测试集。
关键表现:
- 推理增强:在 Implicit I2V 任务中,开启“思维模式”后,模型的指令遵循(IF)和视觉质量(VQ)均有显著提升,甚至能反超某些闭源模型。
- 多任务平衡:在 OpenVE-Bench 编辑任务中,OmniWeaving 获得了 3.15 的高分,在全局风格转化和局部主体添加上表现非常稳健。
- 主体保持:即使输入 3 个不同的角色参考图(Compositional MI2V),OmniWeaving 也能准确“编织”人物,而不会出现常见的身份漂移或融合错误。
 图 2:定性对比展示。相比 VINO 和 UniVideo,OmniWeaving 在处理复杂指令(如替换沙发或添加特定人物)时展现了极高的保真度。
图 2:定性对比展示。相比 VINO 和 UniVideo,OmniWeaving 在处理复杂指令(如替换沙发或添加特定人物)时展现了极高的保真度。
深度洞察
OmniWeaving 的成功证明了数据构造与阶段训练的重要性。
- 三阶段训练:从“对齐(Alignment)”到“自由多任务(Free-form Pretraining)”再到“推理增强(Reasoning Fine-tuning)”,这种阶梯式的逻辑进化符合认知科学规律。
- 局限性:尽管它是开源界的佼佼者,但距离 Seedance-2.0 等顶级闭源模型在算力规模和数据极精细度上仍有差距。
总结
OmniWeaving 不仅仅是一个模型,它定义了下一代视频生成基准:未来的视频生成将不仅是视觉像素的流动,更是多模态逻辑的“编织”。它是社区通往完全 Omni-capable 视频生成的一个重要灯塔。