OrbitNVS 是一个将新视角合成(NVS)重新定义为“轨道视频生成”任务的框架。该方法基于预训练视频扩散模型 Wan2.1,通过引入相机适配器、法向图生成分支和像素级监督,在单视图输入下实现了高度一致的 3D 对象生成,显著刷新了 GSO 和 OmniObject3D 榜单的 SOTA。
TL;DR
新视角合成(NVS)正从传统的几何重建转向视觉常识推理。OrbitNVS 通过将 NVS 建模为“轨道视频生成”,并对 Wan2.1 视频大模型进行深度定制(引入相机适配器、几何分支及像素级精调),在单图生成的质量与一致性上跨越式地超越了 SV3D 等先前 SOTA。
背景定位:从重建到“想象”
传统的 NVS 方法往往试图通过 NeRF 或 3DGS 进行显式重建,但在仅有单张或极少数视角输入时,这些方法在“盲区”的表现往往一塌糊涂。
OrbitNVS 的核心 Insight 是:人类之所以能通过一张照片想象物体的背面,靠的是看过万物后的“常识”而非精准的透视计算。 视频数据包含了物理世界的动态常识,因此,使用在大规模视频数据上预训练的模型来“补全”旋转视角,天然比从零训练 2D 模型更具优势。
核心方法论:三位一体的深度定制
1. 物理对齐:相机适配器 (Camera Adapter)
通用的视频生成模型(如 Wan2.1)并不理解欧式空间的相机姿态。OrbitNVS 引入了基于 Plücker 坐标的相机适配器,将相机的成像射线(Ray)直接编码并注入 DiT 的每一层。
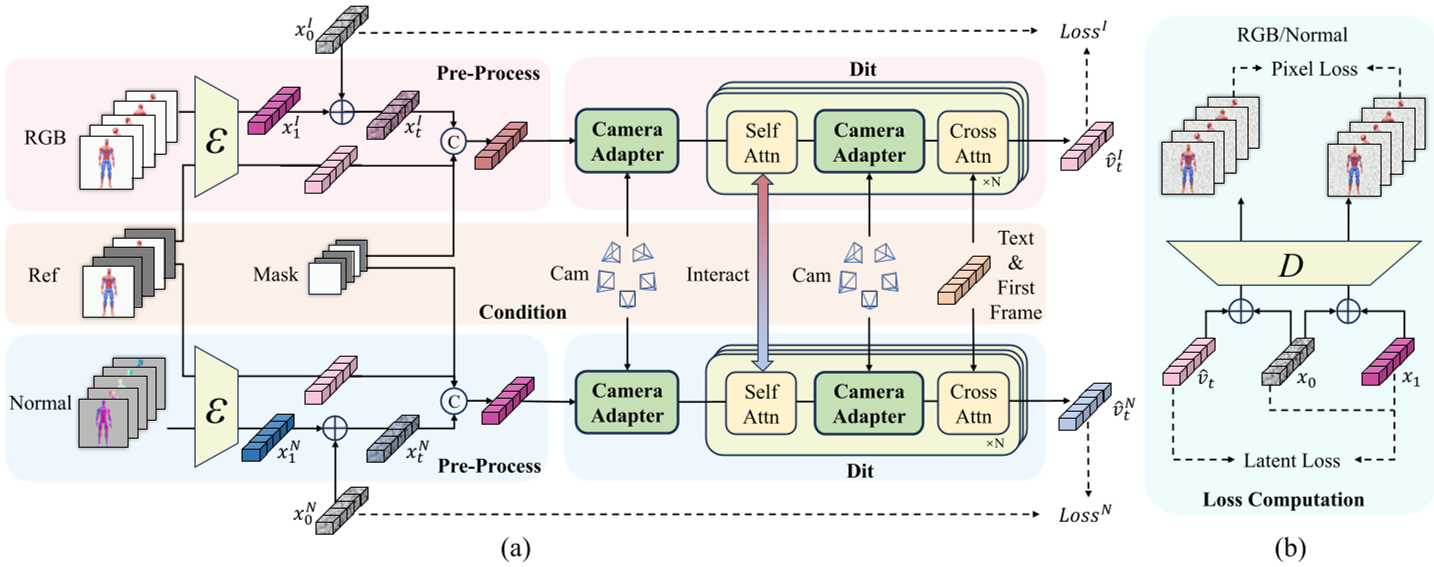 图 1:OrbitNVS 总体架构,展示了相机适配器与双分支结构
图 1:OrbitNVS 总体架构,展示了相机适配器与双分支结构
2. 几何约束:法向图分支 (Normal Map Generation)
为了防止模型在生成时出现“纹理对齐但几何崩坏”的问题,作者设计了一个并行的法向图生成分支。
- 原理:法向图表征的是物体的固有形状,不受环境光照和颜色纹理干扰。
- 机制:法向特征与 RGB 特征在 Self-Attention 层进行交互,强制 RGB 的生成符合物理几何逻辑。
3. 画质突破:像素空间后训练 (Pixel-Space Post-Training)
现有的 Latent Diffusion 在 VAE 压缩阶段会丢失 4x 或 8x 的细节。OrbitNVS 在训练后期加入了像素级监督:由于通过 VAE Decoder 反向传播,DiT 被迫学习如何产生更利于还原细节的潜变量。
 图 2:像素级损失对物体细节(如条形码)还原的显著提升
图 2:像素级损失对物体细节(如条形码)还原的显著提升
实验战绩
在 GSO 和 OmniObject3D 两个权威 3D 扫描数据集上,OrbitNVS 在各种相机轨道(水平、正弦波动)下均表现出色。
| 方法 | GSO (PSNR ↑) | OmniObject3D (PSNR ↑) | | :--- | :--- | :--- | | SV3D | 18.9 | 16.4 | | EscherNet | 20.8 | 18.6 | | OrbitNVS (Ours) | 23.7 | 21.0 |
这种量级(+3dB左右)的提升在 NVS 领域是极为罕见的,充分证明了其架构设计的优越性。
深度洞察与总结
OrbitNVS 不仅仅是一个刷榜的模型,它代表了一种趋势:将视觉任务降维打击。通过将静态 3D 任务包装成动态视频任务,它成功地利用了视频模型中蕴含的大规模物理先验。
局限性:尽管画质极高,但由于模型基于 14B 参数的 Wan2.1,推理成本相对较高。此外,对于完全未见过的极其复杂的非凸几何体,法向预测仍有微小瑕疵。
未来瞻望:这种“轨道视频”范式未来极有可能与多模态大语言模型(VLM)进一步结合,实现通过指令直接精细控制物体的纹理修改或姿态调整。