本文提出了 PackForcing,这是一个旨在解决自回归视频生成中 KV-Cache 线性增长和长视频误差累积问题的统一框架。通过创新的“三分区 KV-Cache”策略和 32 倍 Token 压缩技术,PackForcing 仅需 5 秒短视频训练,即可在单张 H200 GPU 上实现 120 秒高动态、长相干视频的 SOTA 生成。
TL;DR
在自回归(Autoregressive)视频生成的道路上,开发者一直面临“显存溢出”与“长程失效”的双重夹击。PackForcing 给出了一份优雅的答卷:通过将 KV-Cache 进行分区管理并实施 32 倍的高倍率 Token 压缩,它仅凭 5 秒短视频的微调,就能在单卡上生成 2 分钟连贯的高动态视频。
核心痛点:为什么长视频生成这么难?
自回归模型虽然能理论上“无限”生成,但现实极其残酷:
- 内存黑洞:视频 Token 极为密集。生成 120 秒视频对应的 KV-Cache 约需 138GB,这意味着目前的单卡 GPU 根本无法承载其“记忆”。
- 渐进式崩溃:传统的缓存截断(Truncation)会导致模型“失忆”,随着时间推移,生成的物体会变形、消失,或者背景完全错位(Semantic Drift)。
PackForcing 的绝招:三位一体的缓存管理
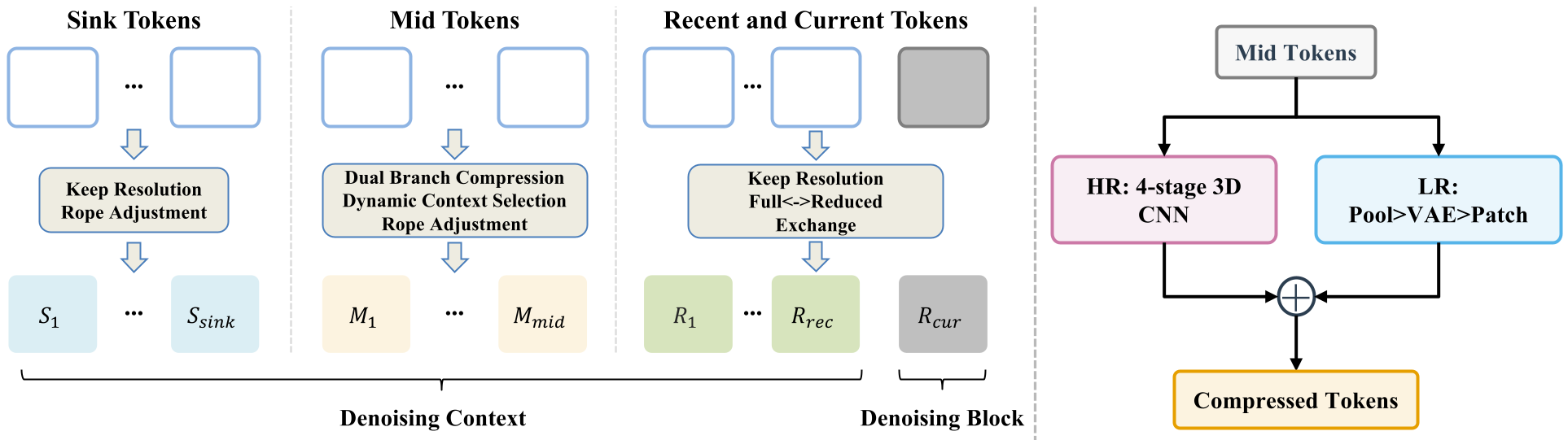
作者提出,视频的记忆不应该是扁平的,而应该是具有层次结构的 Three-Partition KV-Cache:
- Sink Tokens(语义锚点):保留视频最初的几帧。它们像“定海神针”一样锁定全局布局和主体身份,防止语义漂移。
- Compressed Mid Tokens(中程记忆):这是本文的重头戏。中间的大量历史帧不直接保留,而是通过一个双分支(Dual-Branch)模块进行 128 倍体积压缩(Token 数减少约 32 倍)。
- HR 分支:利用 3D 卷积保留精细结构。
- LR 分支:通过 VAE 重编码捕获全局语义。
- Recent Tokens(近期触感):保留最近生成的帧,不进行压缩,以确保动作的流畅和局部时序相干性。
破解位置偏移:增量 RoPE 旋转
在动态丢弃(Eviction)旧 Token 时,剩下的 Token 会面临位置编码断层的问题。PackForcing 引入了 Incremental RoPE Adjustment。
- 物理直觉:既然 RoPE 是复数旋转,那么删除 $\Delta$ 块后,只需对 Sink Tokens 应用一个补偿旋转因子 $e^{i heta_t(\delta)}$,即可让记忆在时间轴上实现“无缝对接”,计算开销几乎为零(<0.1%)。
实验战绩:短练长用的奇迹
PackForcing 最令人惊艳的是其外推能力。即便只在 5 秒的短片上训练,它也能稳定输出 120 秒的视频。
- 显存效率:KV-Cache 稳定在 ~4.2GB。
- 画质表现:在 VBench 的 Dynamic Degree 指标上,PackForcing 达到了 56.25,远超同类模型。这意味着它生成的视频不是“PPT 动画”,而是具有丰富摄影机运动和主体动作的真实视频。

在长达 2 分钟的“水獭冲浪”测试中,PackForcing 保持了极高的主体一致性,黄色救生衣和水花纹理在 120 秒后依然清晰可辨,而对比 baseline(如 Self-Forcing)在 60 秒处就已出现色彩塌陷。
深度洞察
PackForcing 的成功在于它精准捕捉到了视频数据的 Spatiotemporal Redundancy(时空冗余)。它不仅仅是简单地“丢弃”记忆,而是通过学习一种压缩表征,让模型在有限的注意力带宽内,依然能看到“过去”。
局限性:尽管动态度极高,但在极端长的时间窗口(>2min)下,主体一致性仍有微幅下滑。此外,目前的 32 倍压缩率是否是帕累托前沿的最优点仍值得进一步探索。
总结
PackForcing 为我们展示了长视频生成的一个重要趋势:高效的上下文管理比单纯扩大模型参数更有意义。它打破了显存的物理枷锁,标志着个人工作室级别的硬件也能产出电影级长度的 AI 视频。