本文提出了 PAM,这是一个用于手物交互(HOI)视频生成的 Pose–Appearance–Motion 统一引擎。该方法通过解耦位姿生成、外观合成和运动生成三个阶段,仅需初始/目标位姿和物体几何即可生成高保真、时空一致的 HOI 视频,在 DexYCB 和 OAKINK2 基准上达到了 SOTA 水平。
TL;DR
手物交互(Hand-Object Interaction, HOI)是具身智能和 AR/VR 的核心。清华、北大等机构的研究者提出了 PAM,一个能够仅凭“起点”和“终点”位姿,就自动“脑补”出整段高画质交互视频的引擎。通过将位姿、外观、运动三个阶段解耦并结合多模态条件控制,PAM 在视频质量(FVD 29.13)和几何精度(MPJPE 19.37mm)上均大幅刷新 SOTA,并成功实现了“以假乱真”的合成数据增强。
痛点深挖:为何生成真实的“抓取”这么难?
在自动驾驶或通用场景视频生成火热的今天,手部交互视频依然是“重灾区”。主要挑战在于:
- 解剖约束严苛:手部有极高的自由度(DoF),轻微的像素偏差就会导致“断指”或“穿模”。
- Sim-to-Real 的瓶颈:很多 SOTA 模型(如 ManiVideo)要求给一个“真实的第 0 帧”,但这在机器人模拟器里是不存在的。
- 碎片化严重:现有的研究要么只管 3D 骨架(Pose-only),要么只管静态图(Single-image),缺乏一个端到端的动力学引擎。
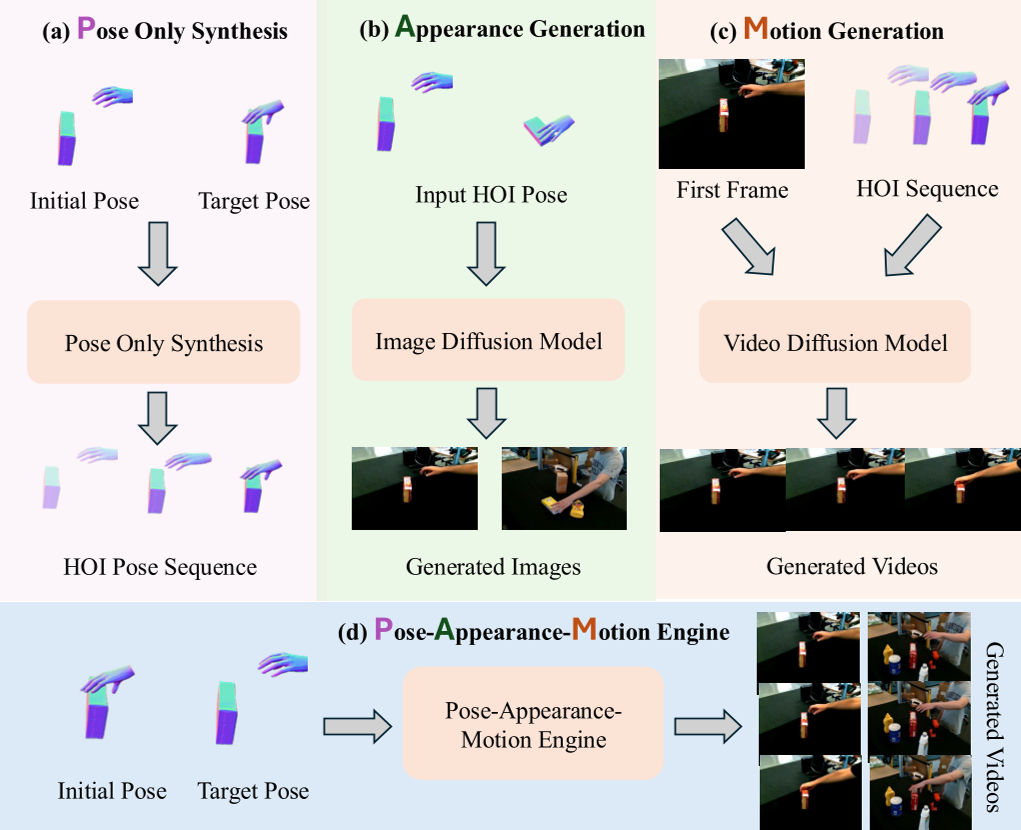 图 2:PAM 与其他主流路径的对比,展示了其在无首帧依赖和完整像素生成上的优势。
图 2:PAM 与其他主流路径的对比,展示了其在无首帧依赖和完整像素生成上的优势。
方法论:三阶段协同的解耦架构
PAM 认为,HOI 的生成不应是杂乱无章的像素堆砌,而应遵循物理直觉。其核心流程分为三步:
1. 位姿生成 (Pose Generation)
利用预训练的 GraspXL 模型。给定初始位姿 $h_0$ 和目标位姿 $h_T$ 以及物体几何,模型首先在 3D 空间内规划出一段符合生物力学的 MANO 运动轨迹。这一步确立了动作的“骨架”。
2. 外观生成 (Appearance Generation)
这是解决 Sim-to-Real 的关键。作者微调了 Flux(强大的扩散模型),并引入了一个三模态控制模块。它不仅仅看语义遮罩(Mask),还结合了深度图(Depth)和手部关键点(Keypoints)。这种“三位一体”的控制确保了生成的手部不仅漂亮,而且结构完全正确。
3. 运动生成 (Motion Generation)
基于 CogVideoX 架构,将第一阶段的 3D 轨迹映射成连续的深度/遮罩序列作为控制信号,再将第二阶段生成的首帧作为参考。通过时空注意力(Temporal Attention),模型将静态的质感“流动”起来,形成 480x720 的高清视频。
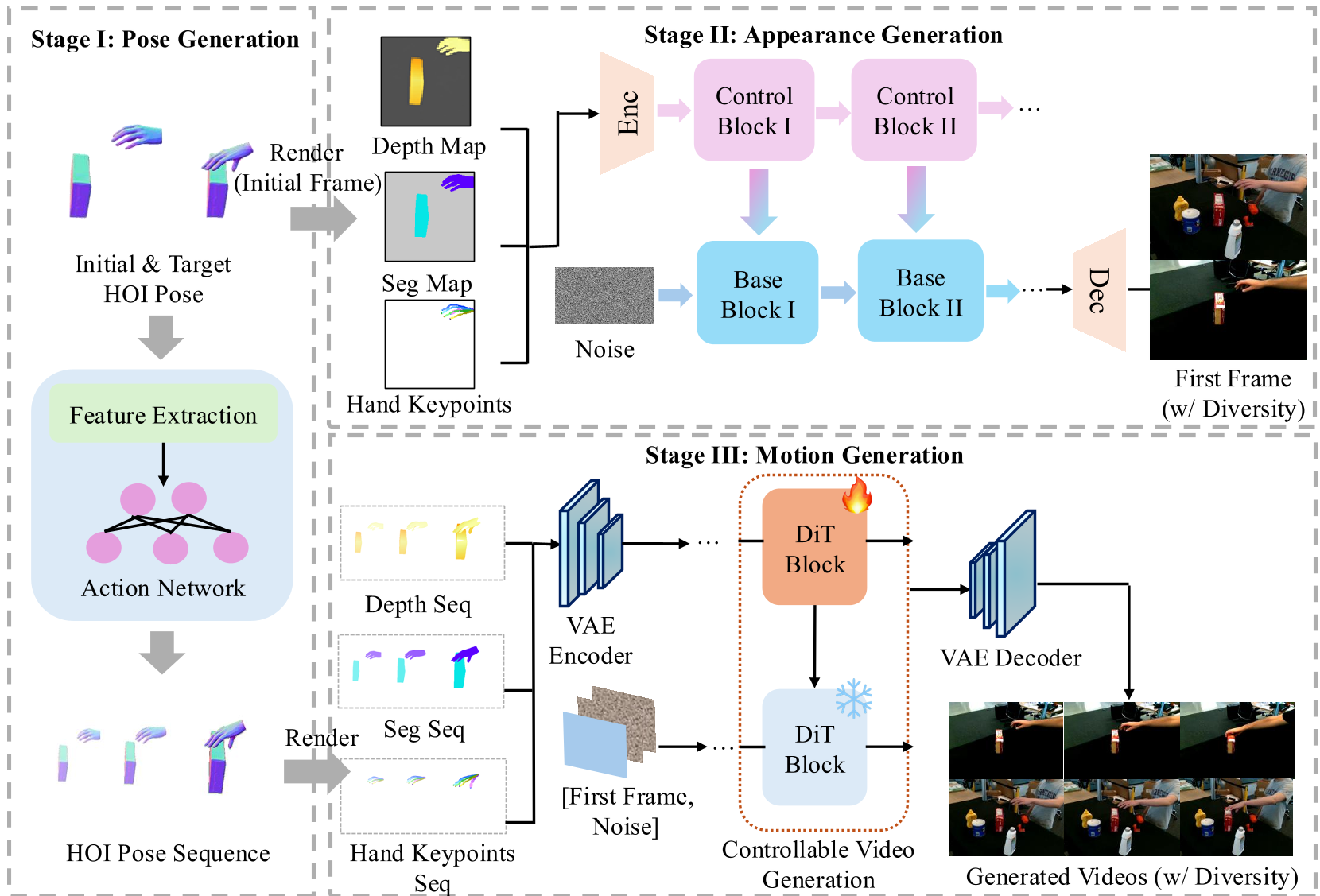 图 3:PAM 的三阶段生成管线:从稀疏位姿到完整视频。
图 3:PAM 的三阶段生成管线:从稀疏位姿到完整视频。
实验与结果:不仅是好看,更是好用
PAM 在 DexYCB 和 OAKINK2 两个硬核数据集上进行了验证。
- 性能碾压:相比于此前的标杆 InterDyn 和 CosHand,PAM 在衡量视频真实性的 FVD 指标上降低了约 25%,而在衡量物理精度的 MPJPE 上提升了 35%。
- 消融发现:多模态条件(深度+语义+关键点)的组合是必不可少的。只用关键点会导致背景崩坏,只用遮罩会导致手部畸形。
 表 1:在 DexYCB 上的定量性能对比,PAM 在各项指标上均处于领先。
表 1:在 DexYCB 上的定量性能对比,PAM 在各项指标上均处于领先。
杀手锏:下游任务加速
最令工业界振奋的是:PAM 生成的视频能直接拿来训练其他手部模型。 实验显示,如果你手头只有一半(50%)的真实标注数据,只要加上 PAM 合成的 3400 段视频,训练出的手部估计模型精度就能和 100% 全量真实数据训练的效果打平。这极大地降低了 HOI 领域的标注成本。
深度洞察与总结
PAM 的成功在于对“Inductive Bias(归纳偏置)”的理解:它不强求扩散模型从零学习物理规律,而是先通过专门的位姿模型确立物理骨架,再让扩散模型进行视觉“上色”。这种**显式控制层(ControlNet 变体)与强大底座(Flux/CogVideoX)**的解耦组合,是目前复杂交互生成的最优解。
局限性:目前的误差传播仍是一个挑战。如果第一阶段的位姿模型出现了穿模,生成的视频虽然看起来美观,但在物理上仍是无效的。 展望:未来将尝试将位姿与外观阶段进一步融合,或扩展至更复杂的双手动操作任务中。