本文提出了个性化流式视频理解(PSVU)新任务,并发布了首个涵盖帧级(实体)和视频级(动作)标注的基准数据集 PEARL-Bench。同时提出了一种名为 PEARL 的插件式、免训练框架,通过双粒度记忆系统实现流式视频中的实时个性化响应。
TL;DR
本文通过提出 PSVU (Personalized Streaming Video Understanding) 任务,解决了 AI 助手在现实世界中“边看边学”的难题。作者不仅发布了包含 2173 个精细标注的 PEARL-Bench,还设计了一个名为 PEARL 的免训练框架。该框架让模型能够像人类一样,通过记忆系统动态注册新概念,并在持续的视频流中精准找回历史细节。
背景定位:从“看离线视频”到“理解流式生活”
尽管 VLM 在视频理解上取得了长足进步,但它们大多仍处于“离线处理”阶段:用户提供一段剪辑好的短视频,模型给出回答。但在真实的 AI 助手场景(如健身指导、工业辅助)中,视频是无尽的流,概念是随需定义的(例如:“这是我的药瓶”、“这种深蹲姿势叫我的专属动作”)。
这种 实时性 (Real-time)、流式输入 (Streaming) 和 动态定义 (On-the-fly definition) 的结合,形成了 PSVU 这一极具挑战性的任务。
痛点深挖:为什么现有的 SOTA 也不灵了?
- 上下文遗忘:离线模型通常将视频均匀采样为固定数量的帧(如 64 帧),对于长达数十分钟的流式视频,这种采样会丢失绝大部分关键信息。
- 概念脱节:用户定义的名称(如 "XiaoJing")对预训练模型来说是未知的,模型难以将这个抽象名称与视频中的特定视觉特征建立持久关联。
- 架构僵化:现有的在线模型(Online Models)往往由固定大小的隐藏状态组成,无法随着视频增长无限扩展记忆。
方法论详解:PEARL 的双粒度机密
PEARL 的核心在于它不试图改变 VLM 的参数,而是为其配备了一个高效的“外挂大脑”。
1. 双粒度记忆系统 (Dual-grained Memory System)
- Streaming Memory (串流记忆):利用场景切割技术,将视频流切分为语义连贯的片段,并存入基于 Embedding 的向量数据库。这保证了模型能随时“回看”。
- Concept Memory (概念记忆):当用户定义一个新概念时,模型提取其视觉特征,并自动生成一段语义描述(如:“黑发、戴眼镜的年轻女性”)。
2. 概念感知检索 (Concept-aware Retrieval)
这里有一个非常巧妙的设计——查询重写 (Query Rewriting)。当用户问“XiaoJing 刚才在干什么?”时,PEARL 会利用 LLM 将其重写为“描述为‘黑发、戴眼镜的年轻女性’的人刚才在干什么?”,从而显著提升 Embedding 模型在检索历史片段时的精确度。
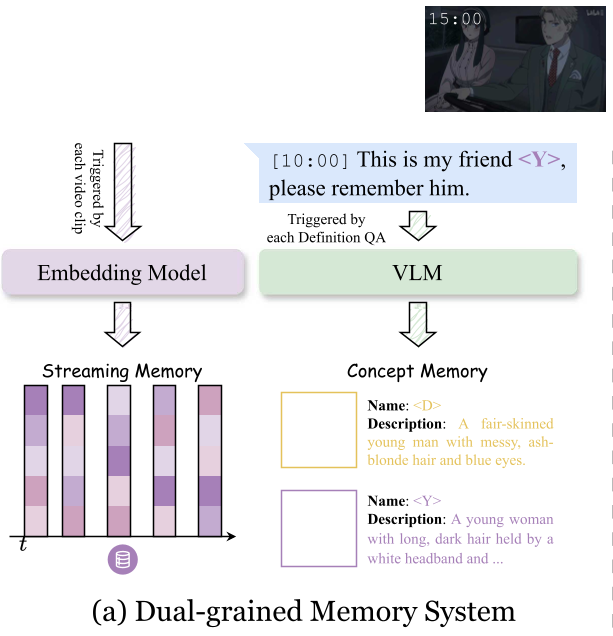 图 1:PEARL 框架流程:从双粒度记忆到概念感知检索的回路
图 1:PEARL 框架流程:从双粒度记忆到概念感知检索的回路
实验与结果:全线屠榜
在 PEARL-Bench 的测试中,集成了 PEARL 的模型表现出了碾压级的优势。
- 性能暴涨:在 Qwen3-VL-8B 上,PEARL 将平均准确率从 28.77% 提升到了 52.24%。
- 视频级突破:在处理动态动作定义(Video-level)时,PEARL 相比最强的在线基线模型 ReKV 领先了接近 24%,证明了其在时空建模上的优越性。
- 低延迟:如下图所示,PEARL 增加的检索延迟极低,主要耗时仍集中在 LLM 的推理阶段,这使其具备了极佳的工程落地性。
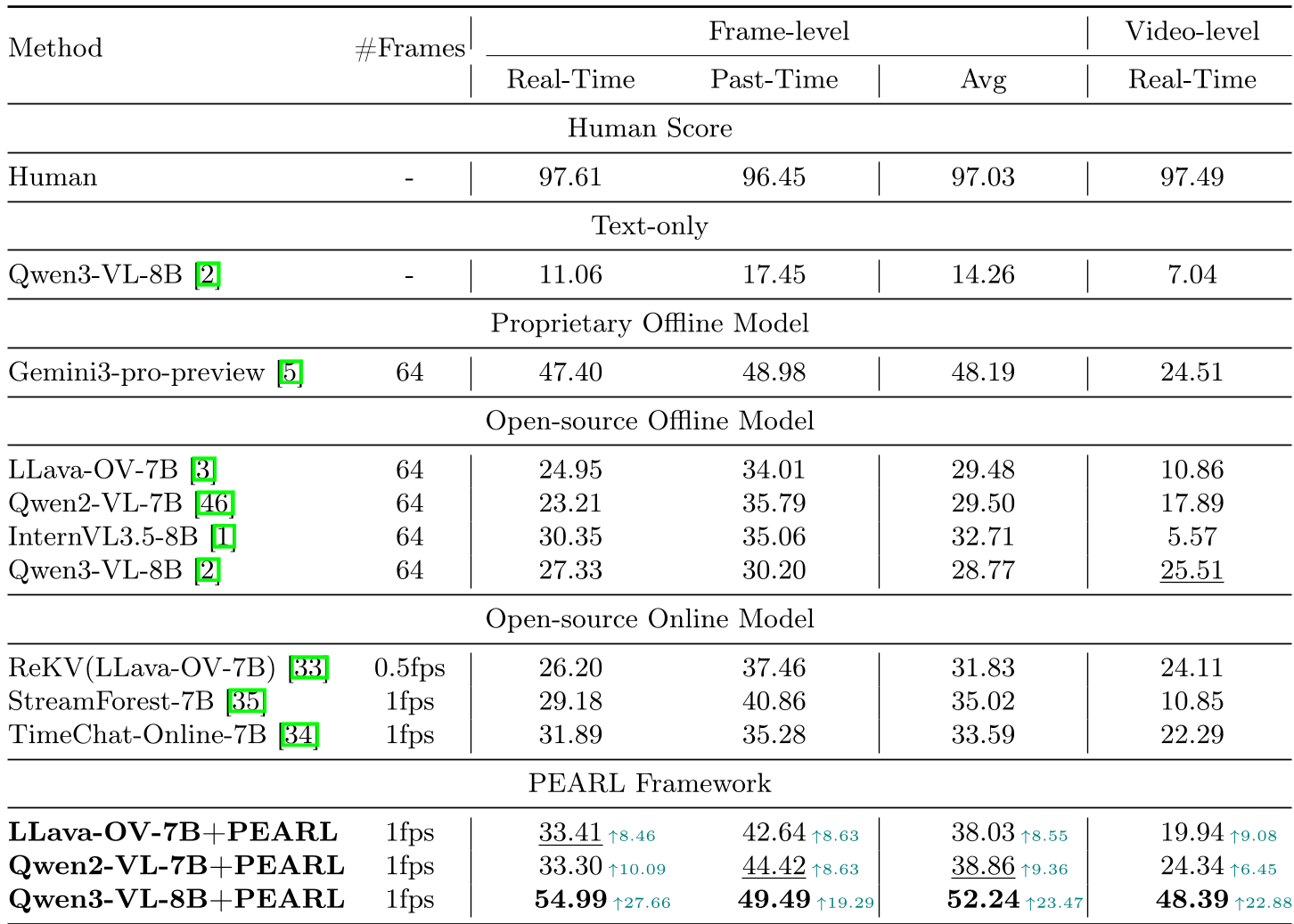 表 1:PEARL-Bench 上的性能对比,展示了 PEARL 对不同架构的普适性提升
表 1:PEARL-Bench 上的性能对比,展示了 PEARL 对不同架构的普适性提升
深度洞察:为什么 PEARL 有效?
PEARL 的成功揭示了一个深刻的直觉:理解个性化世界的关键不在于模型的参数规模,而在于模型能否有效地管理和检索它所见过的东西。
通过将“名称”还原为“视觉描述”,PEARL 绕过了大模型难以实时微调的困境。这种通过 RAG 技术改造 VLM 的思路,不仅解决了存储效率问题,还使得模型能够跨越数千秒的视频流进行精确溯源。
局限性与展望
虽然 PEARL 在准确率上取得了突破,但在处理超高频并发的场景定义时,向量检索的效率仍有待优化。此外,PEARL-Bench 的视频级动作合成目前依赖于数字人,未来若能引入更多真实复杂场景下的动作标注,将更具实用价值。
总结
PEARL 为我们展示了未来个性化 AI 助手的雏形:它不仅认识你,还能记得你几分钟前做过的那个动作,并能实时对你的行为作出反馈。这是迈向交互式具身智能的重要里程碑。