本文提出了 PersistWorld,一种通过强化学习(RL)后训练来稳定视觉世界模型(World Models)长程生成的框架。该方法在 DROID 机器人操纵数据集上显著降低了 LPIPS 漂移,并在 11 秒的自回归预测中达到了新的 SOTA。
TL;DR
机器人世界模型(World Models)正逐渐成为复杂任务仿真的新宠,但它们都有一个致命伤:长程生成的崩溃。就像人类在极度疲劳时会产生幻觉一样,自回归模型会将之前的微小误差不断放大。PersistWorld 通过一种新颖的 RL 后训练(Post-training)方案,让模型在自己生成的“带毒”数据中学习如何纠偏。结果非常惊人:在保持 11 秒的长程视频生成中,它的视觉逼真度远超当前基线,人类偏好率高达 80%。
1. 痛点:自回归生成的“融化”噩梦
当前的机器人视觉预测模型(如 Ctrl-World)在预测下一秒画面时非常惊艳。然而,当你让它根据前一秒的预测结果继续往后生成 10 秒时,系统就会发生“解体”:
- 物体溶解:原本清晰的碗可能在几步之后变成一坨模糊的纹理(见下文图 3 左侧)。
- 结构漂移:机器人手臂的几何形状会逐渐扭曲,甚至脱离预定的控制轨迹。
这种现象被称为曝光偏差 (Exposure Bias)。模型在训练时看到的是完美的 Ground-Truth 历史,但在推理时面对的却是自己产生的、带有噪声的预测值。
2. 核心机制:对比式强化学习 (Contrastive RL)
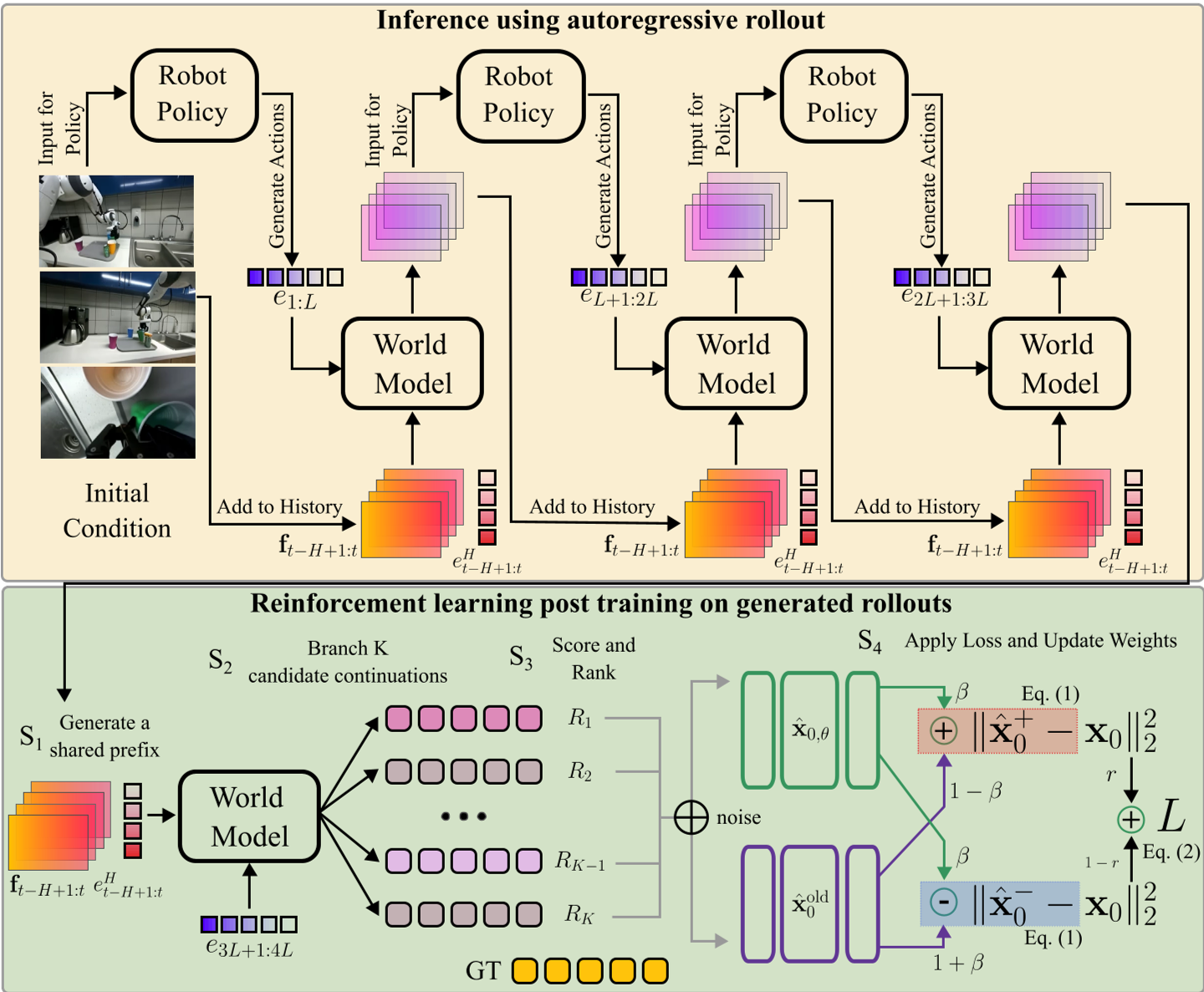
PersistWorld 的目标很简单:让模型看到不完美的历史,并学会产生高质量的后续。作者没有使用昂贵的传统策略梯度法,而是采用了一种更高效的对比式奖励训练。
2.1 适配 $x_0$ 预测
大多数扩散 RL 研究基于速度预测(Velocity-prediction),但本文适配了机器人领域常用的 EDM $x_0$ 预测参数化。作者在数学上证明了:通过构造正向分支 $\hat{\mathbf{x}}_0^+$(向新模型偏移)和负向分支 $\hat{\mathbf{x}}_0^-$(向旧模型反方向偏移),并用奖励权重进行加权,可以直接在扩散过程的前向步骤中优化策略,而无需通过复杂的反向去噪链进行反向传播。
2.2 变长分支协议 (Variable-length Branching)
为了模拟真实推理中的不同阶段,训练过程分为四步:
- 共享前缀生成:先让模型自回归生成随机长度(0-9 步)的视频,产生真实累积误差。
- 分支采样:从这个不完美的起点出发,采样 16 个不同的候选后续。
- 多视角评分:结合手腕和外部摄像头的 LPIPS、SSIM 和 PSNR 综合打分,并进行组标准化(Group Normalization)。
- 模型更新:奖励高的分支被加强,奖励低的分支被抑制。
3. 实验结果:持久性与真实感的飞跃
PersistWorld 在 DROID 数据集上展示了跨维度的提升。在长达 11 秒的序列中,它的衰减速度明显慢于所有基线。
3.1 关键战绩
- 显著降低感知失真:相比 Ctrl-World,外部摄像头的 LPIPS 降低了 14%。
- 手腕视图的突破:由于手腕摄像头对操纵细节最敏感,该模型在手腕视图上的 SSIM 提升了 9.1%,这对于后续将模型用作仿真器至关重要。
- 任务相关性:通过 Object-Centric 遮罩实验发现,提升主要集中在被操纵物体和机器人手臂上,而非简单的背景复制。
 图注:在 11 秒的长程生成中,基线模型(中)中的物体已经解体,而 PersistWorld(右)依然保持了物体的几何完整性。
图注:在 11 秒的长程生成中,基线模型(中)中的物体已经解体,而 PersistWorld(右)依然保持了物体的几何完整性。
4. 深度洞察
为什么 PersistWorld 有效?
- 训练分布的对齐:通过生成变长前缀,模型学会了在处理不同程度的“历史污染”时保持稳健。
- 感知奖励的互补性:LPIPS 保证了深层特征的一致性,而 PSNR/SSIM 保证了底层的像素稳定性。
- 正则化的必要性:实验显示,即使是轻微的 KL 散度正则化也能有效防止模型在优化过程中过度偏移原始扩散先验。
5. 总结与展望
PersistWorld 将视觉扩散模型从单纯的“视频生成器”拉向了真正的“机器人仿真器”。尽管 16 路并行采样带来了额外的计算开销,但它所带来的长程稳定性是前所未有的。
局限性:目前的奖励函数高度依赖于 Ground-Truth 的视觉指标(如 LPIPS),未来如果能引入基于物理约束(如接触力、质量守恒)的奖励函数,世界模型的真实感将更进一步。
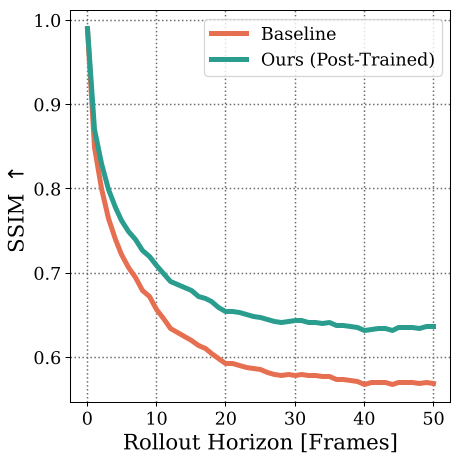 图注:随时间推进,PersistWorld(绿线)在各项指标上均显著优于基线,有效延长了稳定预测的视界锚点。
图注:随时间推进,PersistWorld(绿线)在各项指标上均显著优于基线,有效延长了稳定预测的视界锚点。