本文提出了 PixelSmile,一个专注于细粒度面部表情编辑的扩散模型框架。通过构建包含 6 万张图像及连续情感标注的 FFE 数据集,PixelSmile 实现了对表情强度的精确线性控制,并在解决语义重叠表情(如“恐惧”与“惊讶”)的解耦编辑方面达到了 SOTA 水平。
TL;DR
在面部表情编辑领域,如何让模型既能理解“三分讥笑、五分凉薄”,又能保证变脸后“你还是你”?复旦大学与 StepFun 联合提出的 PixelSmile 给出了答案。它通过构建首个连续情感标注数据集 FFE,配合全对称联合训练架构,突破了传统模型在“相似表情”间的认知模糊,实现了极高保真度的线性强度控制。
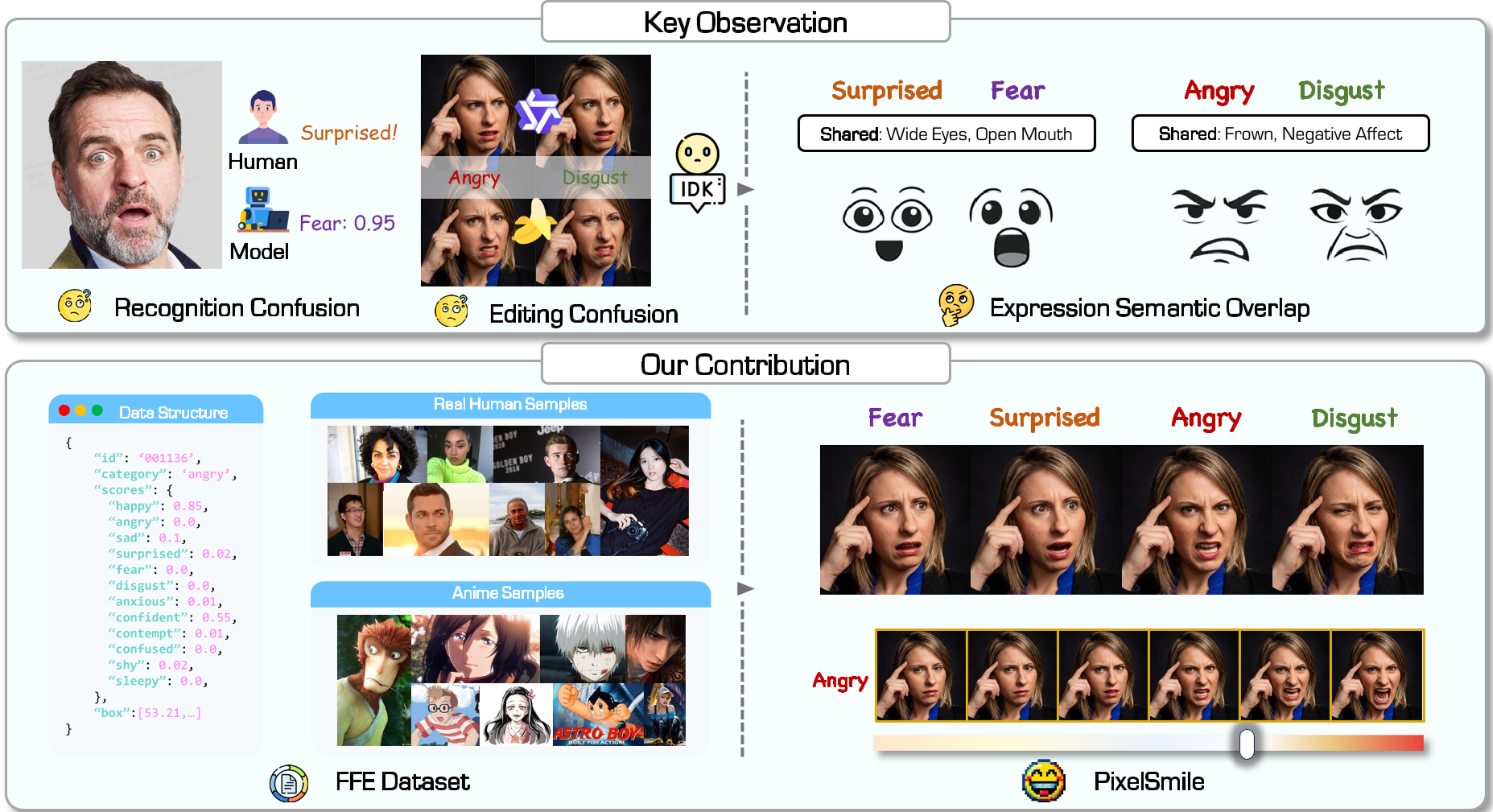
核心痛点:为什么 AI 总是分不清“惊讶”和“恐惧”?
传统的面部表情编辑任务通常将表情视为互斥的类别(如 Happy, Sad)。但在物理世界中,表情是位于一个**连续的语义流形(Semantic Manifold)**上的。
正如论文图 2 所示,人类的表情存在天然的语义重叠。例如,“恐惧”和“惊讶”在眉毛和眼睛的动作上高度相似。当模型使用硬性的 One-hot 标签训练时,它被迫在这些模糊地带进行非黑即白的划分,导致两个后果:
- 结构性混淆:想编辑“恐惧”,模型却附带生成了“惊讶”的特征(语义泄露)。
- 控制缺失:无法精准表达“微微一笑”和“狂笑”之间的细腻差别。
PixelSmile 的破局之道
1. FFE 数据集:从“类别”到“分布”
作者首先建立了一个包含 60,000 张图像(涵盖真人与二次元)的 FFE (Flex Facial Expression) 数据集。不同于以往,FFE 为每张图标注了一个 12 维的连续得分向量。这种“软标签”让模型学到的不再是孤立的点,而是表情之间的演变路径。
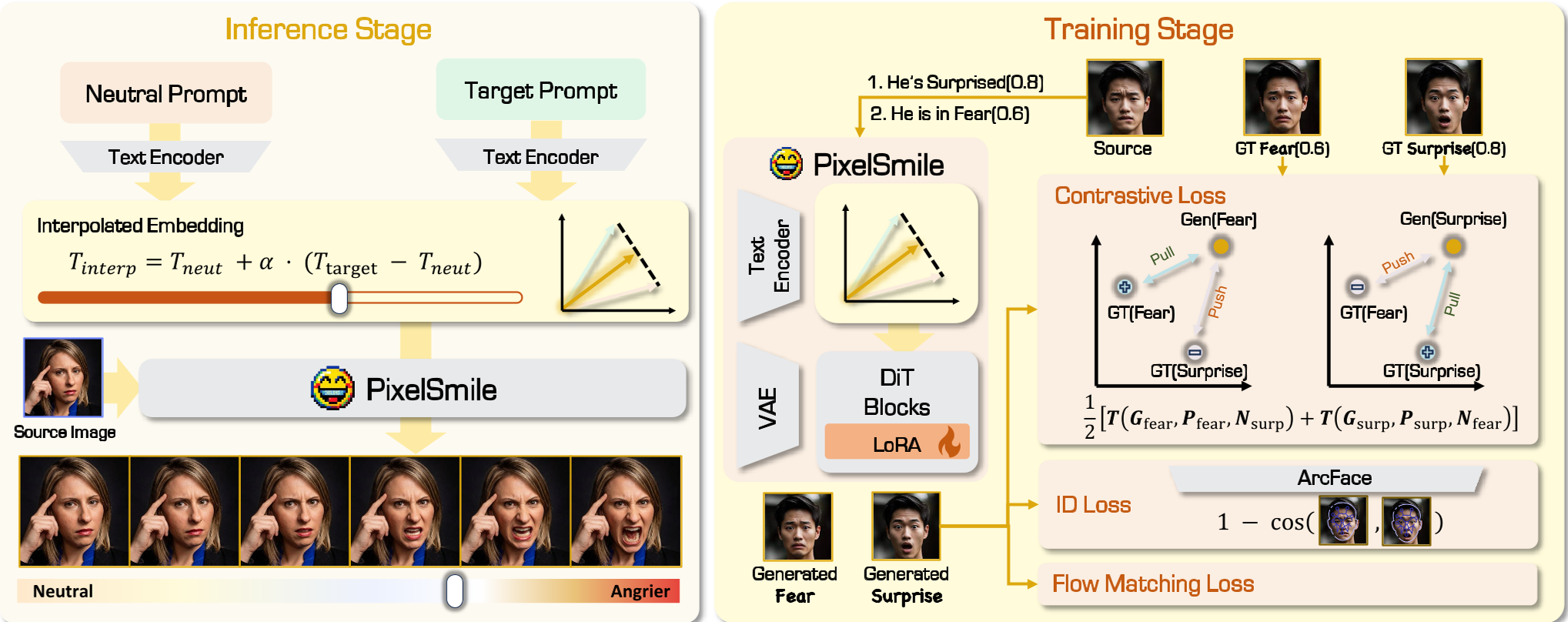
2. 文本潜空间插值 (Textual Latent Interpolation)
为了实现细粒度的强度控制,PixelSmile 摒弃了粗暴的参考输入,转而在文本嵌入层动刀:
- 定义中立描述 $e_{neu}$ 和目标描述 $e_{tgt}$。
- 通过公式 $e_{cond}(\alpha) = e_{neu} + \alpha \cdot (e_{tgt} - e_{neu})$ 进行插值。
- 配合 Flow-Matching 训练,使得参数 $\alpha$ 直接线性对应视觉上的表情强度。
3. 全对称联合训练 (Fully Symmetric Joint Training)
这是解决语义纠缠的神来之笔。如图 3 所示,训练时模型会成对处理容易混淆的表情(如 A 和 B)。当把 A 作为正样本、B 作为负样本进行对比学习后,立即交换角色再练一遍。这种对称性消除了训练偏见,强迫模型在潜在空间中把相似表情的界限拉开。
实验战绩:不仅仅是“更像了”
在定量分析中,PixelSmile 在两个维度展现了统治力:
- 解耦性能:其平均结构混淆率 (mSCR) 比 GPT-Image 提升了近一倍,这意味着它生成的表情最“纯净”。
- 线性控制度 (CLS):在表情强度与控制参数 $\alpha$ 的相关性上,PixelSmile 达到了 0.8 以上,远超之前的 SliderEdit 等方法。
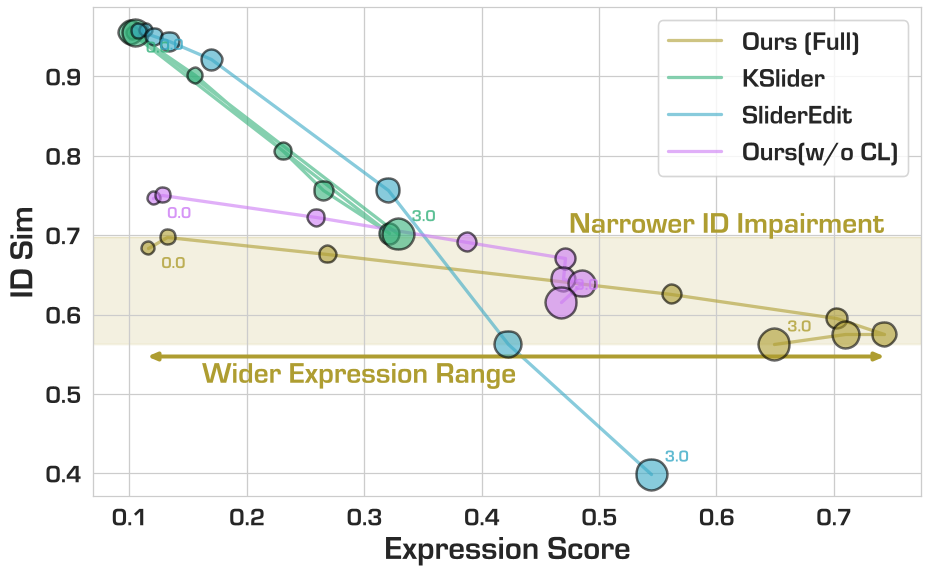
从定性结果(图 6)可以看出,随着参数增加,PixelSmile 的表情变化非常平滑,且关键的 identity 信息(如发型、肤质、五官比例)几乎没有漂移,而其他模型在强度较大时往往会出现“崩脸”现象。

深度洞察:为什么 identity 没丢?
论文中的消融实验揭示了一个关键平衡:Identity Loss。如果只追求表情强度(Contrastive Loss),模型会倾向于通过大幅度改变面部结构(甚至改变人种特征)来迎合标签;只有在 ArcFace 等预训练特征识别器的监督下,模型才学会了“在不改变骨相的前提下动皮相”。
结论与展望
PixelSmile 证明了:在 AI 生成领域,数据的标注质量和训练对称性比盲目增加模型参数更有效。它不仅能处理基本情感,还支持 15 种零样本(Zero-shot)混合表情生成。
局限性:尽管目前在静态图像上表现卓越,但在面临生理性冲突(如同时大笑且愤怒)时,模型仍可能出现不稳定的伪影。未来,将这种细粒度控制扩展到动态视频流,将是 3D 数字人及社交应用的重要方向。