本文推出了 Pixelis,这是一个在像素空间内直接运行的视觉语言智能体。它通过一套紧凑的可执行操作(如缩放、分割、追踪、OCR、时间定位)在图像和视频中进行推理,并在 Qwen3-VL-8B 基准上实现了平均 +4.08% 的相对性能提升。
TL;DR
Pixelis 是一项突破性的工作,它将视觉语言模型(VLM)从“静态观察者”转变为“像素智能体”。它不再仅仅用文字描述图片,而是通过一套可执行工具(如 Zoom, Segment, Track)在像素空间内主动探索。通过三阶段训练(SFT -> CC-RFT -> TTRL),Pixelis 在 8B 规模下实现了更精准、更短且可审计的推理流程,并在多项视频与图像基准测试中刷新了 SOTA。
背景定位:这是视觉推理领域从“纯文本生成”向“动作驱动推理”进化的关键一步,解决了 VLM 在复杂长程任务中容易出现的幻觉和定位不准问题。
痛点深挖:被动观察者的局限
当前的多模态大模型(如 GPT-4V, Llama-3-VL)在处理静态描述时表现出色,但在需要精确物理挂钩的任务中常显疲态:
- 缺乏反馈检查:模型给出答案后,无法验证其关注的区域是否正确。
- 长程推理崩溃:在处理长视频或复杂空间布局时,模型由于缺乏对像素的直接操作手段,推理链条极易断裂。
- 环境自适应差:当光照、运动模糊发生偏移时,静态模型无法通过“测试时学习”来修正自身的判断逻辑。
Methodology:Pixelis 的三大进化阶段
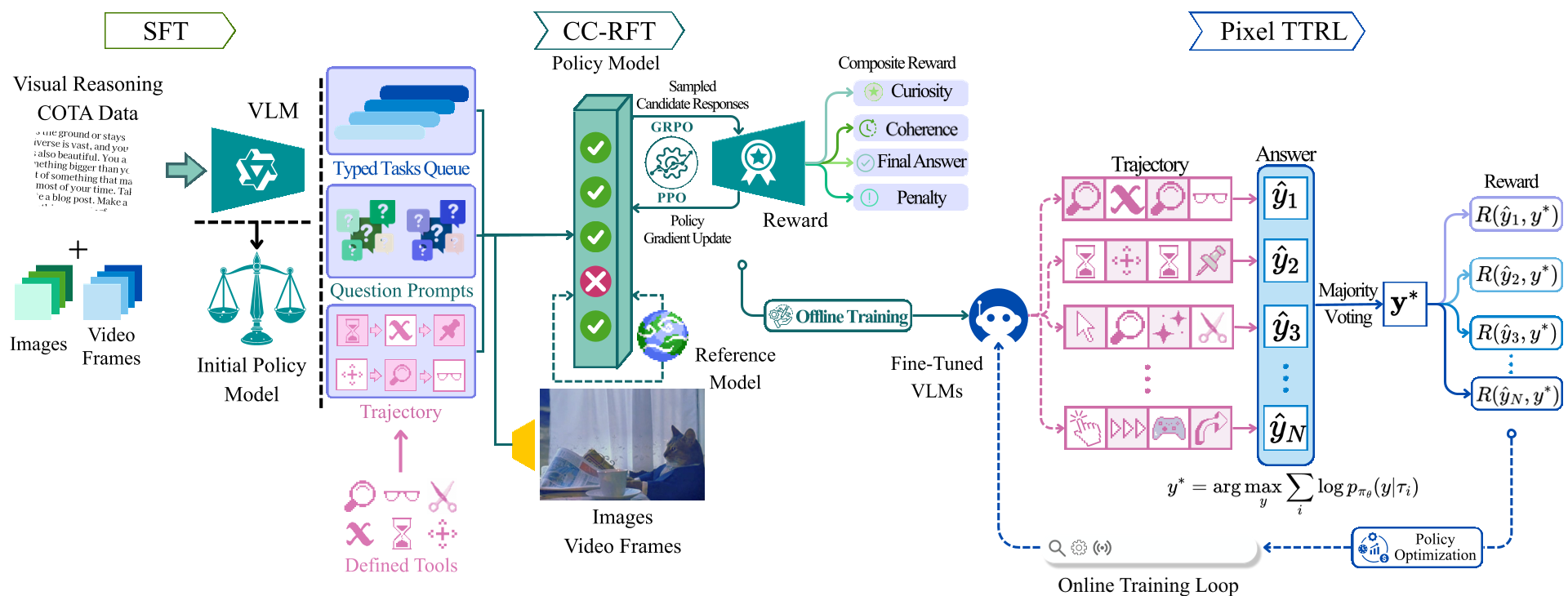
1. 语法习得 (SFT)
Pixelis 首先学习一套特殊的“工具语法”。通过 Chain-of-Thought-Action (CoTA) 轨迹数据,模型学会了何时调用 SEG(分割)或 TRK(追踪)。作者特别设计了掩码模仿损失(Masked Imitation Loss),显著加大了动作名称和参数 Token 的损失权重,确保模型不会在关键动作上“掉链子”。
2. 精简推理链 (CC-RFT)
为了防止模型进行冗余的、打乱仗式的工具调用,作者提出了 Curiosity–Coherence RFT:
- 好奇心奖励 (Curiosity):鼓励模型探索那些动态预测误差较大的像素区域(即预测下一步视觉状态较难的部分)。
- 连贯性奖励 (Coherence):这是本作的亮点。通过计算相邻步骤 Embedding 的余弦相似度并进行 Z-score 标准化,模型被引导生成“步步为营”、逻辑连贯的动作,从而将推理步数从 6 步优化到了 3.7 步。
3. 安全的在线进化 (Pixel TTRL)
在测试阶段,Pixelis 并不依赖标准答案,而是通过 Pixel Test-Time RL 进行自我进化:
- 它通过检索相似的邻域样本,对完整的“推理轨迹”进行投票,而非单纯投票给最终答案。
- KL-to-EMA 约束:引入一个缓慢移动的 EMA 目标作为“引路人”,确保在线学习过程中模型不会因为噪声数据而产生灾难性漂移。
实验结果:更短的推理,更强的战绩
Pixelis 在六大公开榜单(如 MVBench, InfoVQA)上均实现了显著提升。
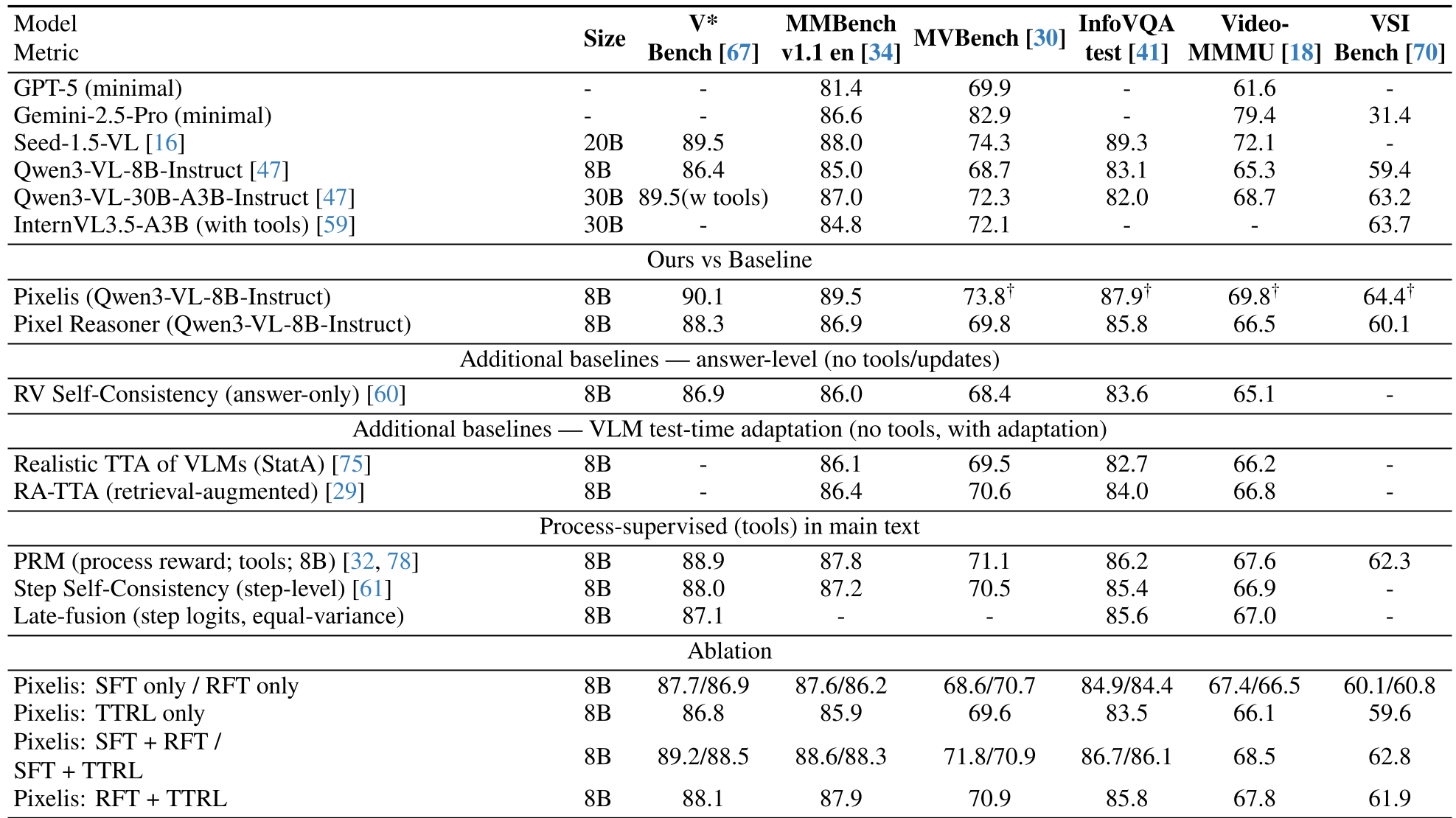
量化指标:
- 准确率提升:在 VSI-Bench 上相对提升达 +6.03%。
- 推理效率:生成的工具链不仅更短(3.7 步),而且具备可审计性——每一步你都能看到模型点击了哪、追踪了谁。
- 安全性:在 8K 次在线更新后,Token-KL 稳定在 0.15 附近,远优于无安全控制的基线。
深度洞察:为什么“像素空间动作”如此重要?
Pixelis 的成功证明了 Inductive Bias(归纳偏置) 在具身智能中的价值。传统的 VLM 将一切转化为 Token,丢失了像素间的拓扑和时空连续性。而 Pixelis 通过 ZOOM 和 SEG,强迫模型在推理前先进行物理层面的“验证”。
这种“先行动、后校验、再回答”的模式,本质上是在模拟人类视觉注意力的切换机制。通过连贯性奖励(Coherence),Pixelis 学会了不轻易在毫无关联的物体间跳跃,从而形成了更加稳健的对象追踪和特征关联能力。
总结与展望
Pixelis 成功统一了像素级的动作执行与高层的语义推理。尽管目前它在处理极其微缩的物体或超快速运动时仍存在工具层面的局限,但它为多模态智能体提供了一个可行的进阶路线图:
- 工具化:不再盲目信任神经网直接输出,引入物理工具。
- 结构化:利用强化学习修剪冗余动作。
- 在线化:通过轨迹投票实现持续的自我迭代。
对于未来的具身智能系统,Pixelis 这种在像素空间进行逻辑闭环的设计,将是通往通用物理感知智能的关键基石。