本文是对强化学习(RL)环境演进的大规模数据驱动实证研究。提出了一个涵盖代理能力、观测性、模态等维度的多维分类法,揭示了 RL 环境从早期物理模拟(如 MuJoCo)向以大语言模型(LLM)驱动的语义推理(如 WebArena, SWE-bench)转化的 SOTA 范式迁移。
TL;DR
强化学习(RL)的上限不由算法决定,而由它所处的“世界”(环境)决定。本文通过对过去 13 年、2000 多篇论文的定量分析,系统性地梳理了 RL 环境从物理模拟(如 Atari, MuJoCo)向数字感知与语义推理(如 WebArena, DeepSeek-R1 验证环境)的史诗级迁移,并揭示了 LLM 时代下“认知指纹”如何重塑智能的边界。
1. 痛点:被忽视的“环境侧”公式
长期以来,RL 社区沉迷于优化 Policy()和 Value(),却将环境 视为静态背景。作者指出,这种忽视导致了严重的算法脆性:代理在单一基准上达到超人类水平,但在面对细微扰动时会发生“灾难性遗忘”。
研究直觉(Insight):环境不仅是容器,更是数据的生成坩埚。 智能的进化轨迹与环境的结构复杂度、认知抽象度高度同步。
2. 核心架构:环境演进的“生命树”
作者提出了一个多维分类坐标系,将环境设计拆解为:代理群体、应用领域、认知能力、观测性、模态跨度、动作空间和奖励机制。
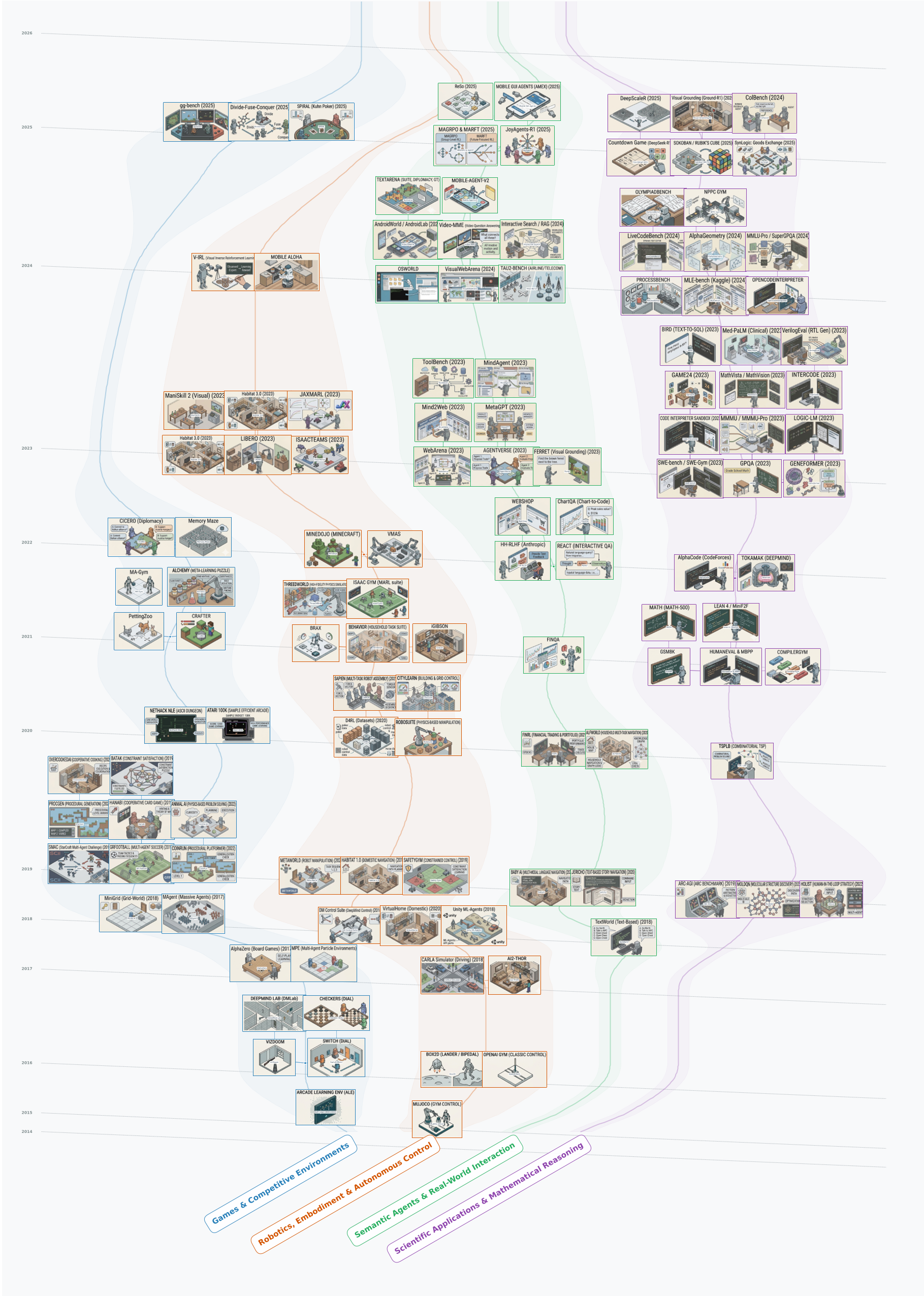 图 1:RL 环境进化树。可以看到从最初的 Toy Problems(GridWorld)到 Deep RL 时代的感知复杂性,再到当前的 Foundation Model 驱动的具身智能。
图 1:RL 环境进化树。可以看到从最初的 Toy Problems(GridWorld)到 Deep RL 时代的感知复杂性,再到当前的 Foundation Model 驱动的具身智能。
3. 范式迁移:从“系统 1”到“系统 2”
通过对不同阶段论文的聚类,文章识别出两个截然不同的生态位:
- 语义优先(Semantic Prior)生态:由 LLM 驱动,核心在于利用预训练的知识进行逻辑推理(Deduction)。如 SWE-bench 要求代理像工程师一样修复 GitHub 漏洞。
- 领域泛化(Domain-Specific Generalization)生态:侧重于物理控制。虽然由于硬件仿真成本高昂,传统的机器人 RL 占比在下降,但其在工业优化(如 48.6% 的系统运营任务)中找到了新出口。
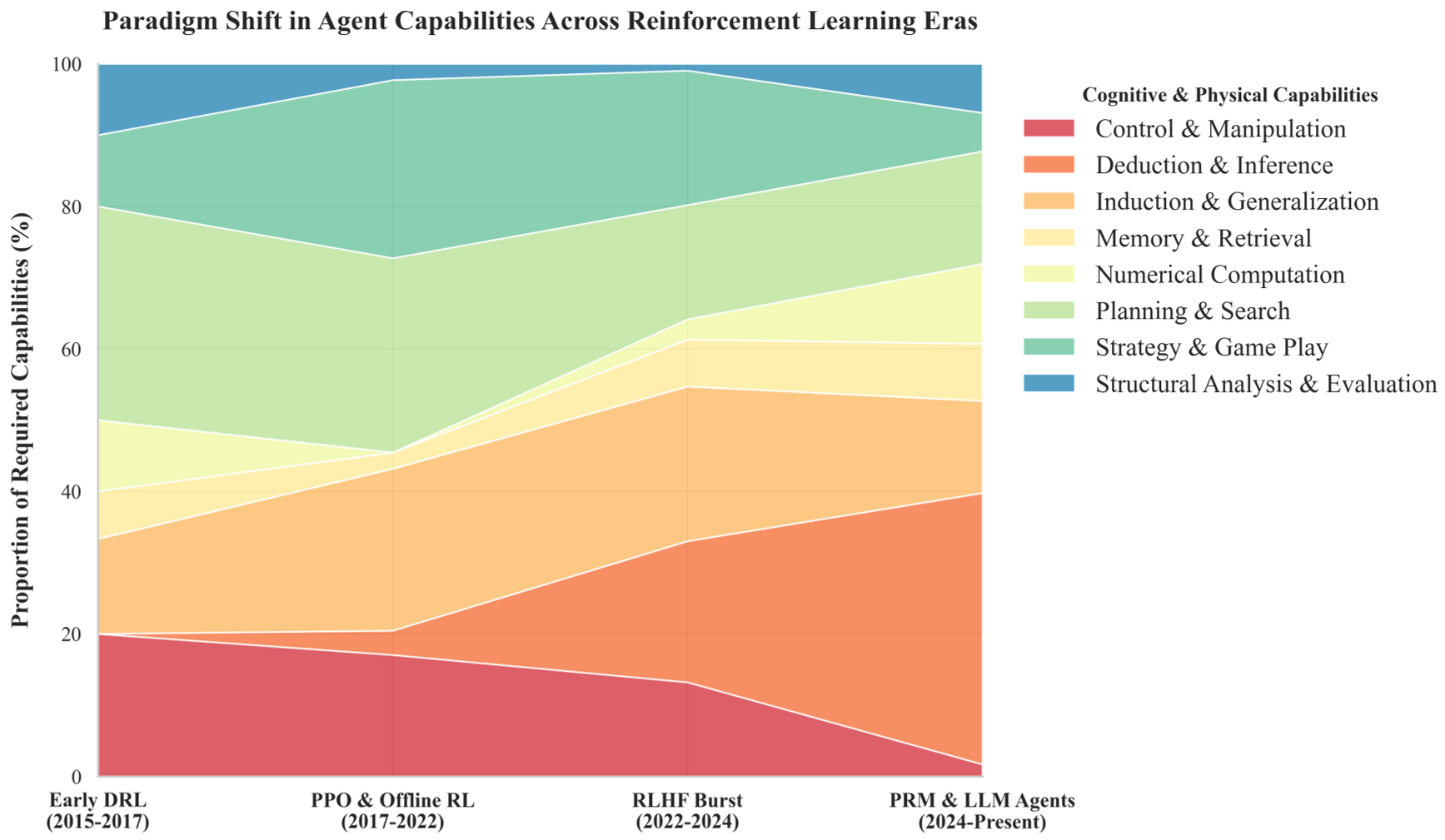 图 2:能力需求演变图。2024 年后,Deduction & Inference(演绎推理)和 Structural Analysis(结构化分析)的需求呈爆发式增长,标志着 RL 进入了“系统 2”思考时代。
图 2:能力需求演变图。2024 年后,Deduction & Inference(演绎推理)和 Structural Analysis(结构化分析)的需求呈爆发式增长,标志着 RL 进入了“系统 2”思考时代。
4. 实验洞察:跨域转移与协同
本文通过对 300 多个 LLM 交互环境的“认知指纹”分析发现:
- 正向迁移(Synergy):数学、代码和科学领域的任务具有共享的逻辑底层。训练代理解决数学竞赛题(GSM8K)能显著提升其在代码验证中的逻辑严密性。
- 干扰效应(Interference):过度训练复杂的物理控制(如极致的 Locomotion)可能会破坏代理处理长程语义规划的能力。
- 奖励细粒度(Reward Granularity):在稀疏奖励(Sparse Reward)环境下,简单的二元胜负信号已失效。SOTA 工作(如 OpenAI 的 PRM)转向了“步骤级过程奖励”,这是解决复杂推理任务的关键。
5. 深度总结:未来的 AGI 熔炉
作者认为,当前的 RL 环境正处于“笛卡尔式分裂”状态:一边是纯文本的抽象逻辑,一边是纯物理的动力控制。
未来启示(Takeaway):
- 程序化语义生成:解决静态数据集被模型“背诵”的污染问题,环境必须具备实时生成逻辑拼图的能力。
- 具身语义模拟器(Embodied Semantic Simulators):真正的 AGI 诞生于“一边看懂说明书,一边组装精密仪器”的任务中,即 VLA(视觉-语言-动作)与物理控制的极致统一。
本文基于 arXiv 论文《FROM PIXELS TO DIGITAL AGENTS》深度重构。