本文提出了 Points-to-3D,一个基于 Diffusion 的几何可控 3D 生成框架。该方法通过将显式点云先验(Point Cloud Priors)注入潜在 3D 扩散模型 TRELLIS 的结构潜空间,实现了在保持已知区域几何精度的同时,补全未观测区域。
TL;DR
尽管当前的 3D 生成模型(如 TRELLIS, LGM)在视觉效果上已臻幻境,但它们一直面临一个核心痛点:几何不可控。本文提出的 Points-to-3D 打破了这一局限,通过将 LiDAR 传感器或单图预测的点云直接作为“几何锚点”注入扩散模型,实现了既能尊重真实测量数据,又能逻辑自洽补全未见区域的 3D 生成能力。
1. 痛点:为什么 SOTA 模型生成的 3D 几何常有“幻觉”?
目前的 3D 生成基座模型大多遵循从 2D(图像/文本)到 3D 潜空间的映射。这种映射本质上是概率性的,缺乏物理约束。
- Prior Work 的局限:像 TRELLIS 这样的模型,其初始结构潜变量(Structure Latent)是从纯高斯噪声开始生成的。即使有图像参考,模型也可能忽略物体真实的结构比例或遮挡背后的几何细节。
- 研究直觉 (Insight):传感器(如 iPhone 的 LiDAR)或高效的预测器(如 VGGT)已经能提供局部点云。如果能将这些点云作为“硬约束”嵌入生成过程,就能显著减少几何不确定性。
2. Methodology:将生成任务重构为“结构修复”
Points-to-3D 的核心贡献在于将 3D 生成流程从“无中生有”转变为“基于锚点的补全(Inpainting)”。
2.1 潜空间注入
作者没有简单地将点云作为条件 Embedding 丢给 Transformer,而是通过以下步骤将其整合:
- Voxelization: 将点云转化为 $64 imes 64 imes 64$ 的体素占据网格。
- Latent Encoding: 使用 TRELLIS 的 VAE 将体素编码为 $16 imes 16 imes 16$ 的稀疏结构潜变量(SS Latent)。
- Latent Inpainting: 在潜空间中,已知点云对应的位置被保留,未知区域则填充噪声,通过一个专门训练的 Inpainting Flow Transformer 进行补全。
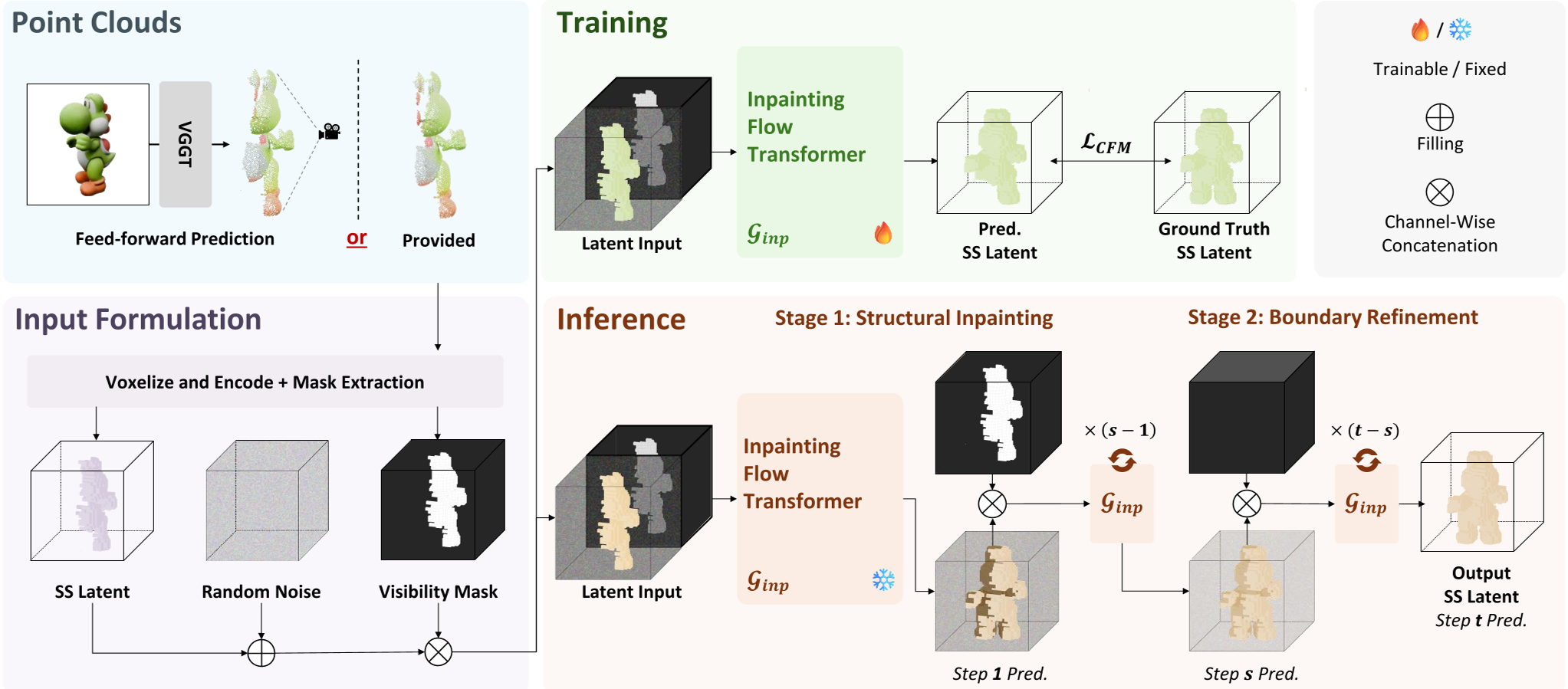 图 1:Points-to-3D 整体架构。紫色框展示了如何将点云转化为 Latent 并在扩散过程中进行 Inpainting。
图 1:Points-to-3D 整体架构。紫色框展示了如何将点云转化为 Latent 并在扩散过程中进行 Inpainting。
2.2 分阶段采样策略 (Staged Sampling)
为了解决 Inpainting 中常见的边界不连续问题(即“空洞”或“断层”),作者设计了两阶段采样:
- Stage 1: 结构修复:前 $s$ 步迭代中,强制保留可见区域的几何结构,确保全局骨架一致。
- Stage 2: 边界精化:后 $t-s$ 步切换为标准去噪模式,允许模型在小范围内对边缘进行微调,使生成的补全部分与原始点云完美无缝融合。
3. 实验结果:刷新几何忠实度
Pins-to-3D 在多个尺度上证明了其优越性,不仅是在物体级别(Toys4K),更是在复杂的场景级别(3D-FRONT)。
3.1 极高的几何保真度
在可见区域,该方法的 F-score 几乎达到了完美的 0.998。这意味着传感器捕捉到的每一个点,在最终生成的 3D 资产中都得到了忠实体现。相比之下,传统的生成模型往往会对这些已知区域进行“二次创作”,导致精度大幅下降。
 图 2:与 baseline 的可视化对比。注意 Normal Map 部分,Points-to-3D 在结构转折处的清晰度远超对比方法。
图 2:与 baseline 的可视化对比。注意 Normal Map 部分,Points-to-3D 在结构转折处的清晰度远超对比方法。
3.2 从单图预测到 3D 生成
即使没有 LiDAR,结合 VGGT 预测的点云,该框架依然能产生比直接 Image-to-3D 更好的效果。通过显式的点云中介,模型能够更好地理解物体的空间结构。
4. 深度洞察:为什么这种方法有效?
- Inductive Bias 的增强:直接在 Latent 层面注入占据信息(Occupancy Mask),赋予了模型更强的空间先验,这比 Attention 中的隐式 Cross-Attention 约束要直接得多。
- 解耦结构与细节:通过在 SS Latent(结构潜空间)做 Inpainting,而在 SLAT(外观潜空间)做细节补充,Points-to-3D 成功解耦了“形”与“色”的生成逻辑。
5. 总结与展望
Points-to-3D 为 3D 内容创作提供了一种“所见即所得”的方案。它不再是盲目地从文本中生成 3D 模型,而是允许创作者先通过简单的深度传感器扫描物体的正面,再由 AI 补全完美的背部和内部细节。
局限性:目前该方法依赖于预训练 VAE 的分辨率。对于超大规模或极端精细的局部细节,Latent 空间的压缩可能会导致微小信息的流失。未来的研究或许可以结合高分辨率的局部精修模块来进一步提升上限。