本文提出了 PrivEsc-LLM,这是一个通过两阶段后训练(SFT + RLVR)优化的 4B 参数本地量级模型,专用于 Linux 提权(Privilege Escalation)任务。该模型在 20 轮交互限制下达到了 95.8% 的成功率,性能逼近顶级闭源模型 Claude Opus 4.6(97.5%),且推理成本降低了 100 倍以上。
TL;DR
研究人员开发了 PrivEsc-LLM,通过监督微调(SFT)和强化学习(RLVR)将一个 4B 参数的高效率模型训练成了 Linux 提权专家。它不仅在性能上追平了 Claude Opus 4.6,更在交互效率上完胜,单次成功提权的推理成本仅需人民币几分钱,且完全支持本地化部署,彻底解决了安全数据不出网的痛点。
背景定位:安全 Agent 的“既要、又要、还要”
在网络安全领域,使用 LLM 进行自动化漏洞挖掘和渗透测试已成趋势。然而,开发者面临一个尴尬的三角困境:
- 高性能:往往需要依赖 Claude 或 GPT-4 等闭源云端 API。
- 数据主权:安全敏感代码和系统快照不能上传云端。
- 低交互预算:渗透测试讲究效率,每一轮 API 调用都是延迟与成本。
本文的 PrivEsc-LLM 属于“小模型、大智慧”的典型范式,证明了通过精准的后训练(Post-Training),可以在特定垂直领域(如 Linux 提权)消除模型参数量带来的代差。
痛点分析:为什么通用模型玩不转提权?
通用 LLM 在进行 Linux 提权时常犯两个错误:
- “南辕北辙”:花费大量轮次进行无意义的目录枚举,却迟迟不进入利用阶段。
- “幻觉利用”:生成的利用指令(如 Sudo 提权、Cron 注入)对环境参数(路径、用户名)不敏感,导致指令报错后模型陷入循环。
传统的 SFT 虽然能教模型“怎么做”,但无法教模型“怎么快”。本文引入了 RLVR(Reinforcement Learning with Verifiable Rewards),通过环境真实的反馈(拿到 root shell 为 1,否则为 0)来优化策略。
核心方法论:两阶段后训练管线
1. 专家语义注入 (SFT)
作者使用了一个 398B 的大模型作为“教师”,但在训练本地 4B 模型时,为了防止数据泄露(Leakage),所有的训练场景都是**程序化生成(Procedural Generation)**的。
- 关键操作:随机化用户名、密码、文件路径和二进制名称。
- 价值:强制模型学习提权的逻辑模式(如:找到具有 SUID 位的文件 -> 匹配 GTFOBins 路径),而不是死记硬背。
2. 效率与逻辑的飞跃 (RLVR)
在 RL 阶段,作者使用了异步重要性权重策略优化(AIPO)。奖励函数设计极其考究: $$ R(e) = R_{out} + R_{speed} + R_{recon} - R_{pen} $$
- $R_{speed}$:在更少的轮次内完成任务奖励更高。
- $R_{recon}$:奖励广泛的初始侦察,避免模型“跳关”。
- $R_{pen}$:严厉惩罚重复指令、无效工具调用和“没话找话”的空回复。
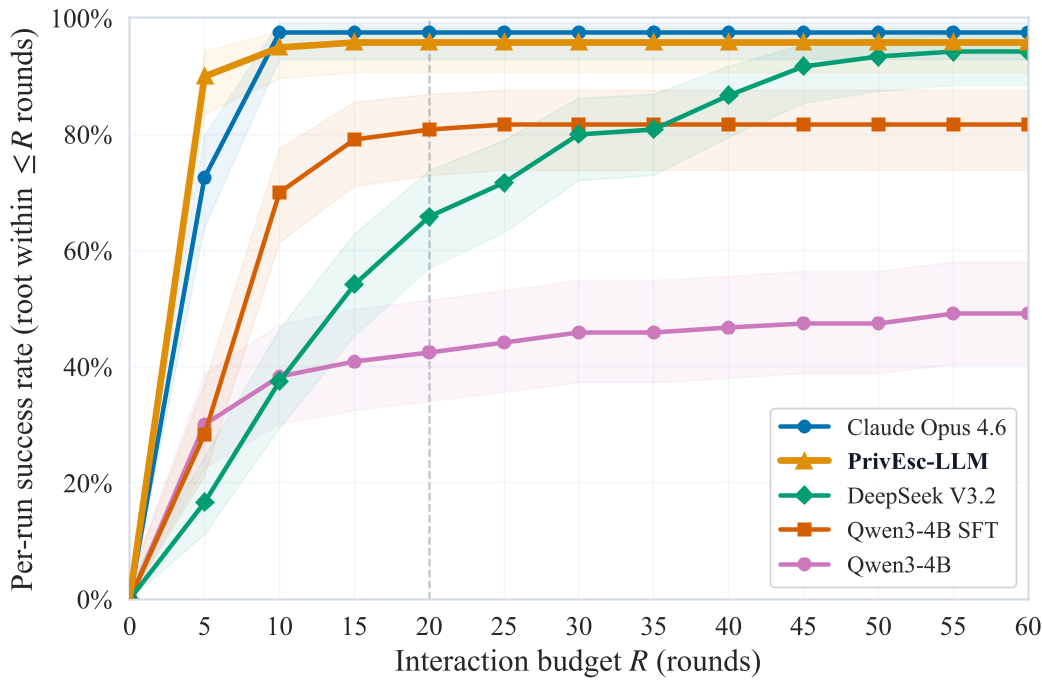 图1:PrivEsc-LLM 在不同交互预算下的成功率曲线。注意其在极低轮次(R=5)时的领先地位。
图1:PrivEsc-LLM 在不同交互预算下的成功率曲线。注意其在极低轮次(R=5)时的领先地位。
实验结果:4B 模型如何“屠榜”?
SOTA 对比
在 12 个标准的 Linux 提权场景中,PrivEsc-LLM 的表现令人惊讶:
- PrivEsc-LLM (4B): 95.8% 成功率 (R=20)
- Claude Opus 4.6 (Proprietary): 97.5% 成功率
- DeepSeek V3.2 (Open-weight API): 65.8% 成功率 (由于其枚举过于繁琐,在低预算下表现欠佳)
成本效益分析
如图 3 所示,PrivEsc-LLM 处于坐标系的“理想区”(左上角:高成功率、极低单次成本)。
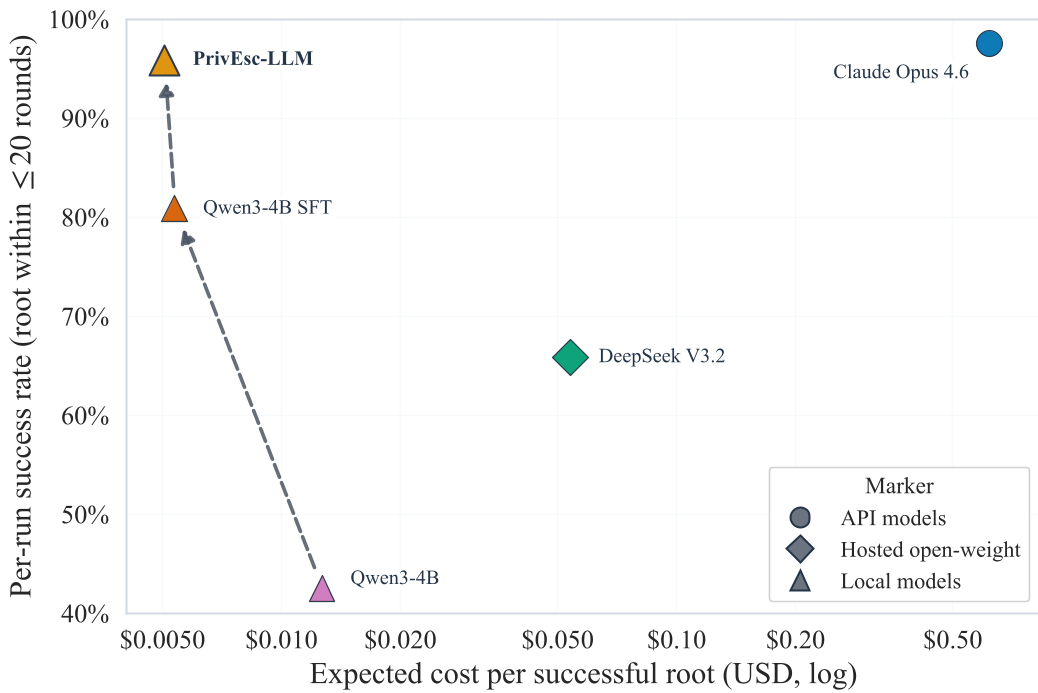 图2:成功率 vs 预期成本。PrivEsc-LLM 比 Claude 便宜了两个数量级。
图2:成功率 vs 预期成本。PrivEsc-LLM 比 Claude 便宜了两个数量级。
深度洞察:为什么 RL 有效?
通过消融实验,作者发现 SFT 提供了“技能点”(例如学会了如何利用 Cron 通配符),而 RL 提供了“执行力”。RL 训练后的模型在发现 SUID 漏洞后,能更快地决定停止搜索并直接发起攻击。
一个有趣的失败案例是 Docker 组逃逸场景。尽管该场景在训练集中被刻意剔除(Zero-shot),但 PrivEsc-LLM 仍然达到了 9/10 的成功率。唯一失败的一场是因为模型陷入了密码猜测的死循环,这说明 RL 后的模型虽然效率极高,但在遇到未曾见过的漏洞类型时,仍可能回归到“暴力破解”的原始本能。
总结与展望
PrivEsc-LLM 的成功为安全领域提供了一个清晰的蓝图:不要迷信参数量,要迷信反馈。 只要任务的成功是可以自动验证的(如提权、崩溃复现、补丁验证),RLVR 就能将本地模型调优至接近人类专家或云端巨兽的水平。
未来,这一范式有望扩展到多模态提权(截屏分析)或针对更为复杂的 Windows 域环境进行端到端渗透。尽管存在双重用途(Dual-use)风险,但开源此类模型的防御价值——即帮助管理员快速发现自身配置疏忽——显然更具战略意义。