本文提出了 VLA-MBPO,这是一个针对视觉-语言-动作 (VLA) 模型微调的实用模型训练框架。通过集成统一多模态模型 (UMM) 驱动的世界模型、交错视图解码机制以及块级分支展开技术,该方法在机器人操作任务中显著提升了策略性能,其中在 LIBERO-Long 任务集上的成功率提升了 12.2%。
TL;DR
在机器人控制领域,Vision-Language-Action (VLA) 模型虽强,但在真实世界通过强化学习 (RL) 进化的代价却极高。本文提出的 VLA-MBPO 框架,通过构建一个高精度的“世界模型”,让机器人能够在想象中进行自我博弈和微调。它不仅解决了多摄像头视角打架的“一致性”难题,还通过巧妙的数学设计克制了长程动作的“误差累积”,在复杂操作任务中实现了显著的性能跃迁。
1. 痛点:真实世界太贵,想象世界太假
目前的机器人大模型主要靠行为克隆(Behavior Cloning, BC)学习,但这种“照猫画虎”的方法在面对没见过的情况时极易撞墙。RL 理论上能让模型变聪明,但在物理世界刷 RL 既不安全又极其缓慢。
转向世界模型 (World Models) 是行业共识,即在模拟器里练。但对于 VLA 模型,这面临三大挑战:
- 视觉建模难:需要生成高保真的像素级未来画面。
- 视角不一致:机器人通常有多个摄像头(如头部视角和手腕视角),如果预测出的两个视角对不齐,策略就会陷入混乱。
- 误差累积:在稀疏奖励(Sparse Rewards)下,初始的一点微小预测偏差会在长程路径中无限放大。
2. 核心架构:基于 UMM 的统一战线
VLA-MBPO 并没有堆砌复杂的视频生成模型,而是基于 Unified Multimodal Models (UMM) 构建。这种设计将视觉、语言和动作(Action Chunking)全部 Token 化,放在一个 Causal Attention 架构下。
2.1 交错视图解码 (Interleaved View Decoding, IVD)
为了解决多视角一致性,作者提出了 IVD。传统的做法是并行生成各个视图,容易导致“各说各话”。IVD 采用类似自回归的方式:先根据当前状态生成头部视图的未来帧,再将生成的头部帧作为条件去推导手腕视图。这种设计确保了全局几何关系与局部精细操作的严格对齐。
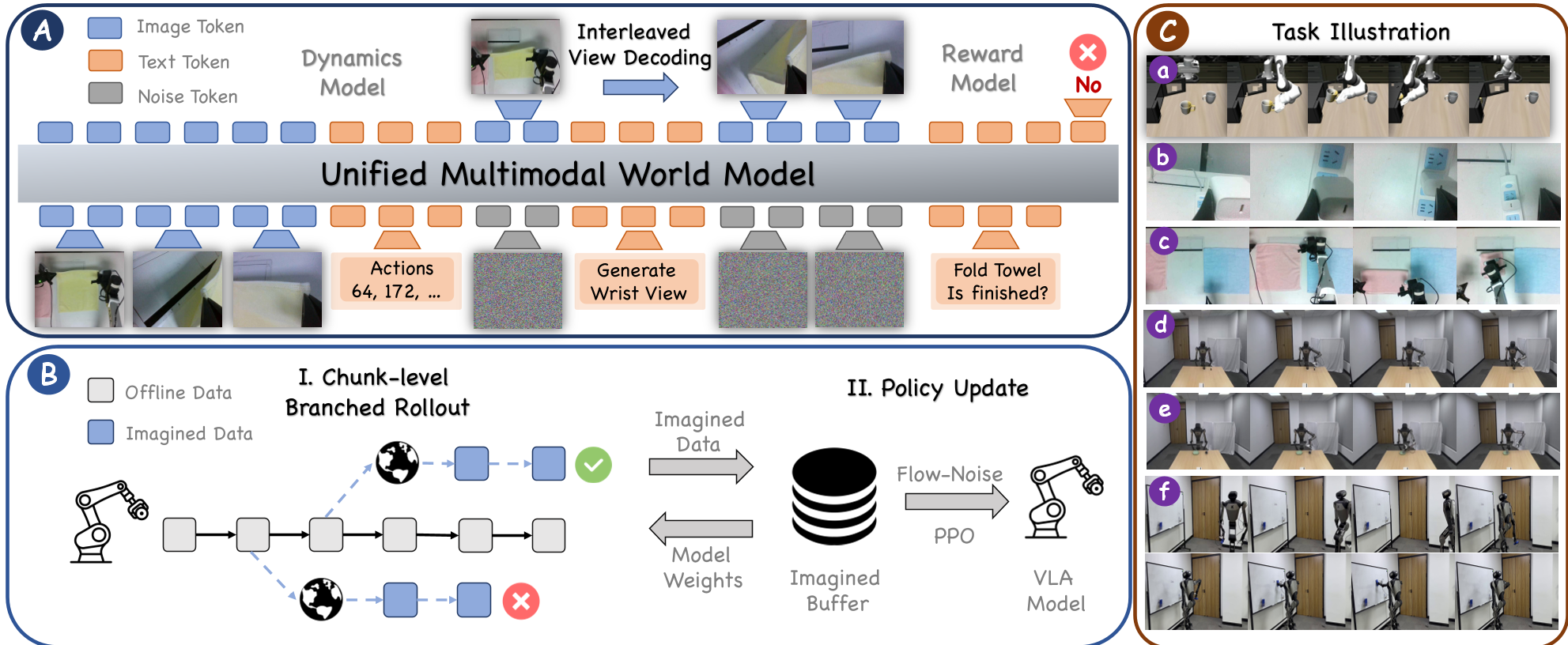 图 1:VLA-MBPO 框架概览,左侧 A 展示了 UMM 基础上的多视图预测。
图 1:VLA-MBPO 框架概览,左侧 A 展示了 UMM 基础上的多视图预测。
3. 算法创新:分支采样与数学证明
针对 Compounding Errors 这一顽疾,VLA-MBPO 采用了 Chunk-level Branched Rollout。
- 动作分块 (Action Chunking):每次不只发一个动作,而是发一组(如 10 步),显著缩短了逻辑时钟。
- 分支展开 (Branched Rollout):不从头开始漫无目的地幻想,而是从已有的离线经验池中随机“起跳”,只进行短程(n 个 chunk)的预测。
理论价值
作者在论文中给出了严谨的 Theorem 4.2 证明。通过比较可以发现,VLA-MBPO 的价值差距(Value Gap)对模型误差的依赖仅是线性阶 ,而传统的全路径模拟则是二次阶甚至更高。这为算法的稳定性提供了物理直觉支持:在看清一小段路的前提下进行高频修正,比试图看清整条街更有效。
4. 实验复盘:从仿真到真机
在 LIBERO 复杂长程任务测试中,VLA-MBPO 的表现大幅超越了包括 IDQL 在内的强基线模型。
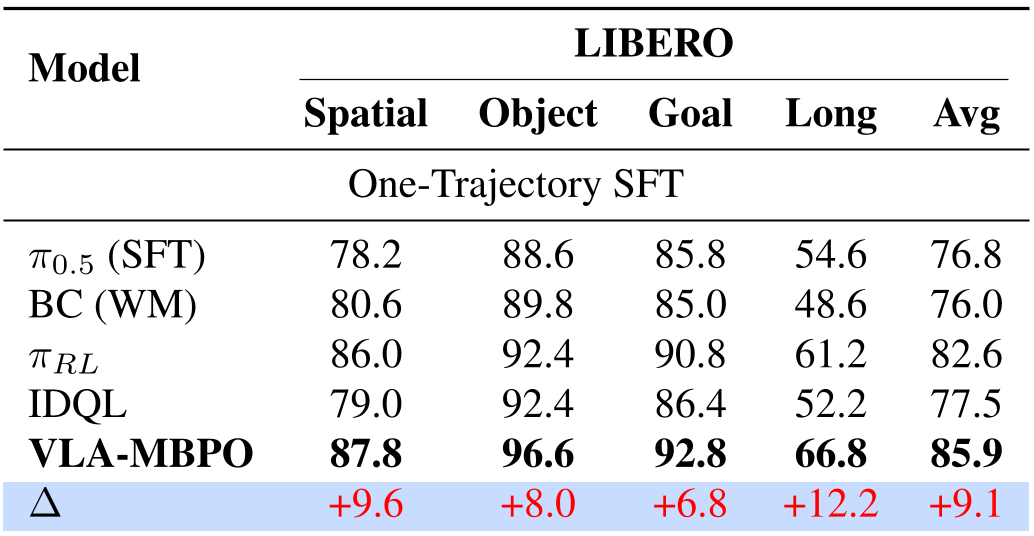 表 1:在各项 LIBERO 子集上的成功率对比,Long 任务提升最为显著。
表 1:在各项 LIBERO 子集上的成功率对比,Long 任务提升最为显著。
真实世界表现: 在双臂机器人 Arx-X5 和全身移动机器人 Galaxy-R1 上,VLA-MBPO 成功完成了插拔细微电缆、折叠柔软毛巾以及全身协调擦黑板等高难度动作。即使面对光照变化和没见过的物体,由于世界模型提供了多样化的“幻想数据”,模型也表现出了极强的 Zero-shot 迁移能力。
5. 深度洞察与局限性
VLA-MBPO 的成功在于它将 大模型的能力(预训练语义) 与 经典强化学习的智慧(MBPO 的分支采样) 进行了有效融合。
- 优势:极高的数据效率;无需模型保守性约束即可稳定收敛;单套超参数即可适配多个场景。
- 局限:
- 算力需求:虽然推理效率高,但生成大量幻想样本仍需消耗 8x H100 等重型资源。
- 大幅运动失效:在面对极其剧烈的运动(Motion Collapse)或视野外的物体幻觉时,世界模型偶尔会“掉帧”或失效。
总结
VLA-MBPO 为实效性的具身智能后训练提供了一条清晰的道路。它告诉我们,与其追求完美的模拟器,不如通过动作分块和分支预测来巧妙地绕过误差。这不仅是学术上的 SOTA,更是迈向通用家务机器人等商业化场景的重要一步。