本文推出了 ProRL Agent,这是一种专为多轮 LLM Agent 强化训练设计的可扩展基础设施。该系统首次提出“Rollout-as-a-Service (RaaS)”理念,通过解耦推理(训练)与环境交互(Rollout),显著提升了处理软件工程、数学和代码生成等长程任务的效率,现已集成至 NVIDIA NeMo Gym。
TL;DR
随着 LLM Agent 逐渐从“一问一答”转向“长程交互”(如修 Bug、写工程),强化学习(RL)成为提升 Agent 决策能力的关键。然而,现有的 RL 框架往往让 GPU 闲置待命,等着 I/O 极慢的沙盒环境返回结果。NVIDIA 团队提出的 ProRL Agent 通过 Rollout-as-a-Service (RaaS) 理念,将环境交互彻底剥离为独立服务,让 8B 模型在软件工程任务上实现了近 200% 的性能飞跃。
背景定位:从“单机耦合”到“服务化解耦”
在传统的 RLHF 流程中,Rollout 只是简单的文本生成。但在 Agent 领域(如 SWE-bench),一次 Rollout 意味着启动容器、编译代码、运行单元测试,可能耗时数分钟。
- 现状:Trainer 既要管 GPU 训练,又要管 Docker 容器生命周期。
- 后果:系统极难扩展,一旦 Docker 崩了,整个训练任务就挂了;且 root 权限要求让其无法在大型 HPC 集群上运行。
核心动机:解决“资源错配”与“逻辑粘连”
作者敏锐地发现,Rollout 和 Training 对资源的需求完全不同:
- Rollout 是 I/O 密集型:依赖磁盘寻址、网络请求和工具执行(Bash/IPython)。
- Training 是 GPU 密集型:依赖显存带宽和张量并行。 将这两者强行塞进一个进程(如图 7-11 所示的现有框架),会导致 GPU 频繁处于等待状态(Idle),且系统迁移成本极高。
架构解析:Rollout-as-a-Service (RaaS)
ProRL Agent 的核心是将复杂的 Agent 交互封装在 HTTP 接口之后。其架构由三个支柱支撑:
1. 三阶段异步流水线 (Three-Stage Pipeline)
系统不再让一个 Worker 盯死一个任务,而是模仿工厂流水线:
- INIT 阶段:专门负责准备沙箱环境。
- RUN 阶段:驱动 Agent 与 LLM 后端进行多轮对话。
- EVAL 阶段:运行测试脚本,计算 Reward 数值。 这种解耦允许三个阶段在不同节点上重叠执行,极大地提高了总吞吐量。
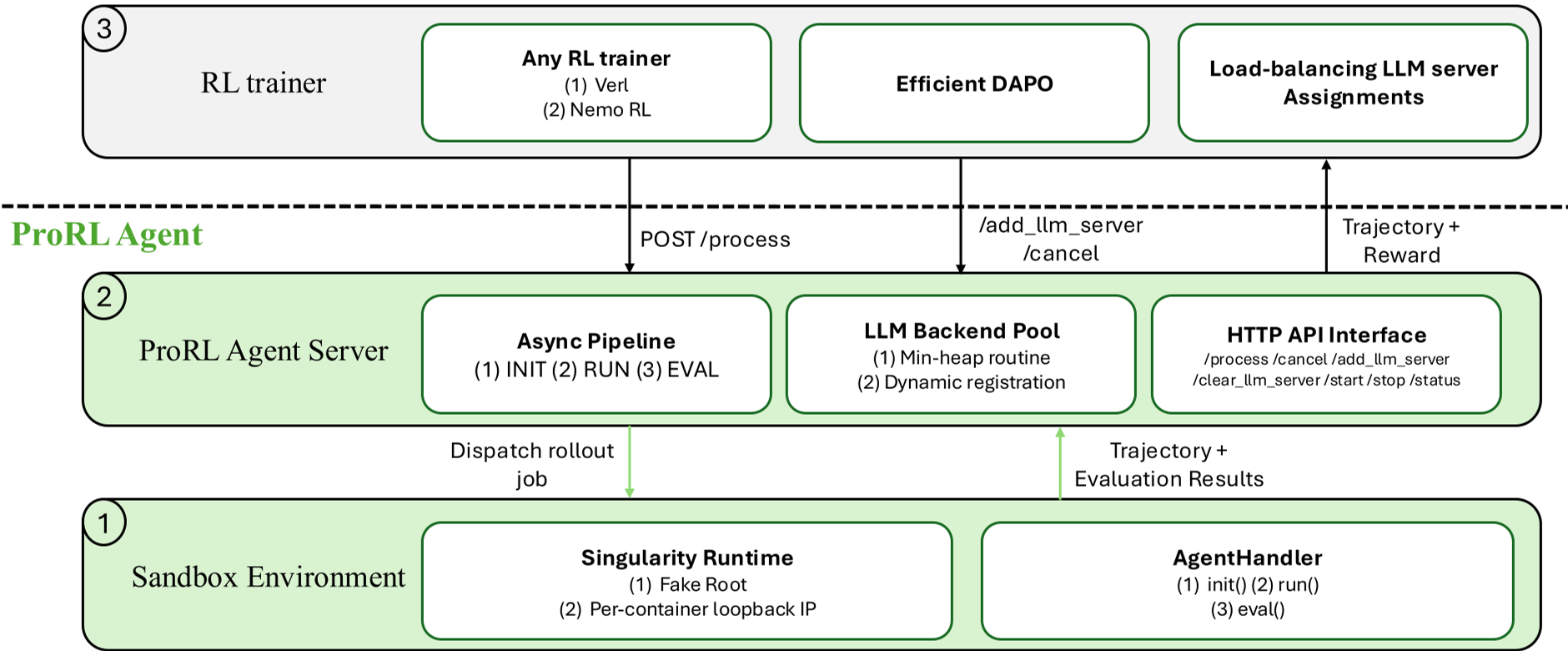
2. 针对 HPC 的 Rootless 沙盒
由于 HPC 环境通常禁止 Docker 的 root 权限,ProRL Agent 改用 Singularity 运行时。它不需要后台守护进程,支持用户态运行。此外,为了降低工具执行的延迟,作者实现了:
- Efficient Bash:跳过 tmux,直接通过 PTY 调用伪终端。
- UDS 通信:利用 Unix Domain Sockets 替代传统的网络回环,减少内部通信开销。
3. 消灭 Token 偏移 (Token-in/Token-out)
这是一个非常深刻的技术细节:如果 Rollout 之后将轨迹转为文本传给 Trainer,Trainer 重新 Tokenize 时可能会因为空格、特殊符号产生偏移(Drift)。ProRL Agent 全程传递 Token IDs,确保训练时使用的数据与 Rollout 时生成的完全一致,保证了数学上的严谨性。
实验战绩:SWE-Bench 见真章
在最具挑战性的 SWE-Bench Verified 软件开发基准上,ProRL Agent 展示了强大的威力和稳定性。

- 小模型奇迹:8B 规模的模型通过 ProRL 训练后,性能从 9.6% 飙升至 18.0%。
- 线性扩展:随着计算节点的增加,系统吞吐量呈现近乎完美的线性增长(见图 5),这对于超大规模 Agent 的迭代至关重要。
深度洞察:为什么这种架构是必然?
ProRL Agent 不仅仅是一个工具库,它代表了 Agentic RL 基础设施的成熟轨迹。
- 解耦带来灵活性:你可以用 PyTorch 练模型,但用 Rust 写环境交互逻辑,二者只需 HTTP 协议通信。
- 容错性:单个沙箱崩溃不会导致 Trainer 崩溃,系统可以通过重试或跳过来保证梯度更新的连续性。
- 算法友好:它专门针对异步采样算法(如 DAPO)进行了优化,支持过期任务的快速取消(Cancellation),避免了无效计算。
总结与局限
ProRL Agent 填补了深度学习框架与复杂操作系统交互之间的鸿沟。尽管目前它在处理极其复杂的图形界面(GUI)任务(如 OS-World)时仍需更多 QEMU 层的适配,但其构建的“RaaS”理念已为下一代具备自我演进能力的通用 Agent 铺平了道路。
ProRL Agent 已开源并集成至 NVIDIA NeMo Gym,是科研人员进军 Agent RL 领域的利器。