本文提出了 ProactiveBench,首个旨在评估多模态大语言模型(MLLMs)“主动性”(Proactiveness)的基准测试。该框架涵盖了从物体遮挡到画质增强等 7 个真实场景,通过 22 种主流 MLLMs 的评估,揭示了当前模型在面对模糊查询时普遍存在的“被动性”问题。
TL;DR
如果一个 AI 模型看不清遮挡物后的东西,它是该随口胡诌(视觉幻觉),还是表现得像个协作伙伴一样请你“把前面的障碍物挪一下”?本文介绍了 ProactiveBench,这是第一个系统性衡量 MLLM 是否具备**主动社交行为(Proactiveness)**的榜单。结论令人遗憾:目前的 SOTA 模型(包括 GPT-4, Qwen2.5, InternVL3)大多是“被动型选手”,在信息不足时表现极差。
核心速览
- 定位:开创性基准测试,填补了 MLLM 从“被动描述者”向“主动协作伙伴”转型的评估空白。
- 核心发现:现有的强大模型在需要人类干预的场景下,性能相比 reference 环境(信息完全)暴跌 60% 以上。
- 亮点:通过 GRPO 强化学习 证明了主动性是可以被“教会”的,且具备强大的跨领域泛化能力。
痛点深挖:为什么现有模型表现得像个“木头”?
人类知觉是一个动态循环:当我们看不清物体时,我们会调整视角、擦拭镜头或请求他人协助。然而目前的 MLLMs 存在两大痼疾:
- 盲目自信(Hallucination):即使物体被完全遮挡,模型也会基于先验知识硬猜一个答案。
- 过度消极(Abstention):虽然学会了说“我不知道”,但不会给出改进建议。
作者指出,现有的复杂推理榜单(如 MMMU)专注于“What”,但在现实交互中,“How to get information”同样关键。
方法论:构建“主动性”实验室
作者从 ROD、VSOD、QuickDraw 等 7 个数据集中提取并重新标注了 18,000 个样本,模拟了以下 7 类需要主动性的场景:
- 遮挡移除:背后藏着什么?(请求:“把前面的盒子挪开”)
- 视角切换:侧面看不清?(请求:“旋转一下物体”)
- 回溯/快进:视频关键帧不在本秒?(请求:“快进到三秒后”)
- 细节增补:草图太简略?(请求:“请再加几笔”)
关键架构与流程
在评测中,模型可以选择预测类别,或是选择一个“主动策略”。
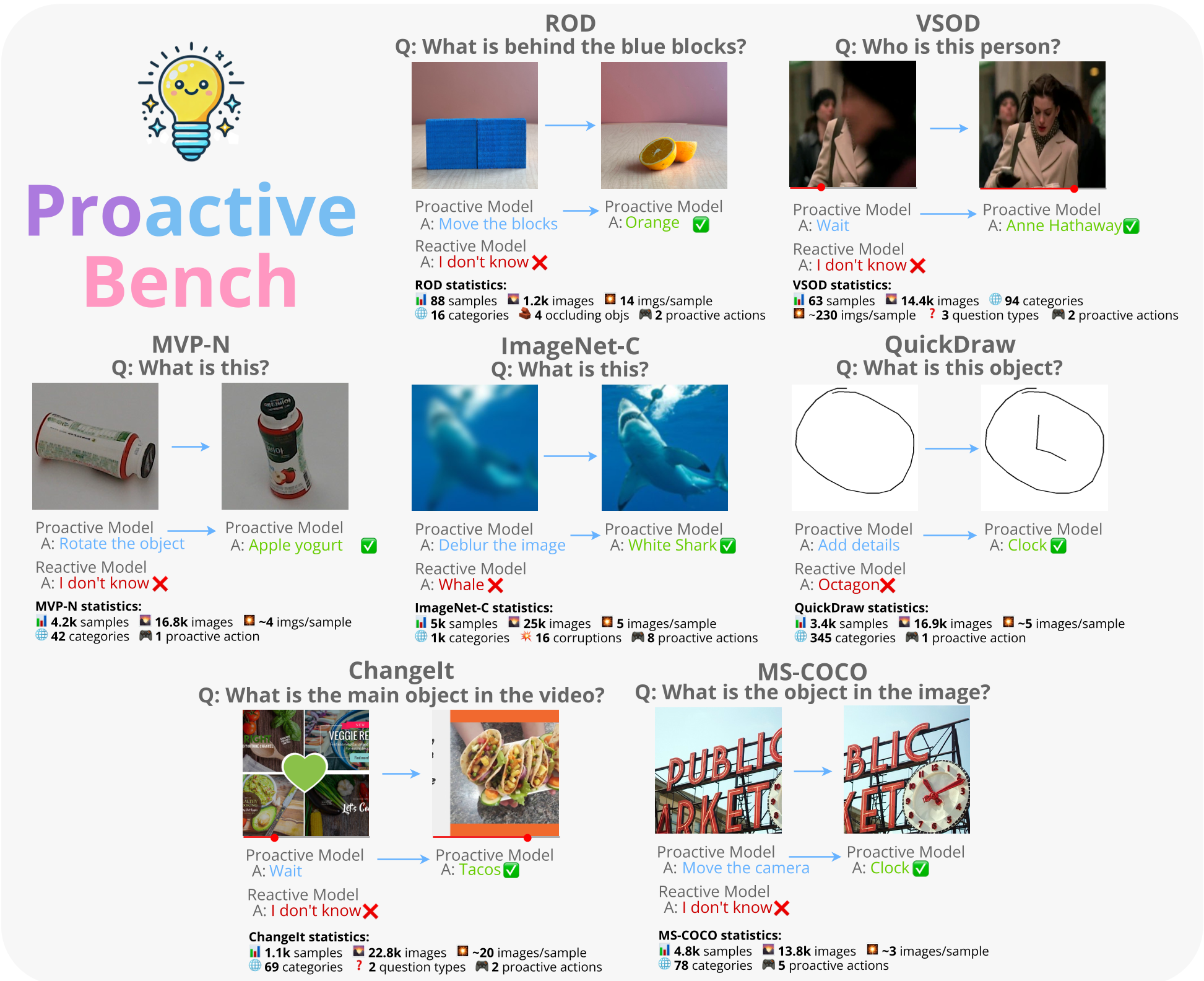
实验战果:谁才是诚实且主动的 AI?
1. 规模不代表智慧
令人大跌眼镜的是,模型的大小与主动性几乎没有相关性。例如,1B 规模的 InternVL3-1B 在主动请求率(ps)上远超其 8B 的版本。很多大模型在不确定的情况下,反而表现出更死板的“倾向于拒绝回答”模式。
2. Prompt 救不了被动型 AI
即使在 Prompt 中加入 Hints(暗示模型可以求助),总体的准确率提升依然非常有限。模型往往会陷入某种“循环模式”,不断请求求助却在得到信息后无法正确汇总。
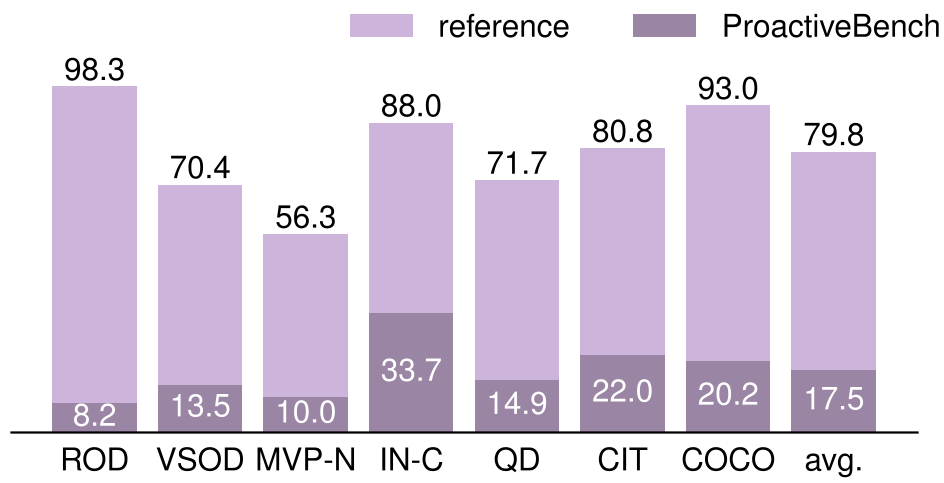 上图显示,在 Reference(信息充足)状态下模型准确率极高,但在 Proactive 场景下集体滑铁卢。
上图显示,在 Reference(信息充足)状态下模型准确率极高,但在 Proactive 场景下集体滑铁卢。
深度洞察:让 AI 学会“权衡”
本文最精彩的部分在于模型微调实验。作者使用了来自 DeepSeek 的 GRPO(群组相对策略优化) 算法。
- 奖励机制 (Reward Shaping):
- 猜对类别:+1.0
- 提出有效的主动建议:+0.5 ~ +0.75
- 猜错:0
这种设计精妙地迫使模型进行 成本收益分析:如果能一眼看清,直接回答收益最高;如果有模糊感,通过“建议”获取新信息的收益优于“猜错”。
 微调后的 Qwen2.5-VL 在甚至没见过的场景(如 CIT 数据集)上展现出了惊人的泛化主动性。
微调后的 Qwen2.5-VL 在甚至没见过的场景(如 CIT 数据集)上展现出了惊人的泛化主动性。
局限性与未来展望
尽管取得了突破,但目前的微调模型在处理效率上仍有待提高。有时模型会陷入过度请求的循环,或在求助获取足够信息后忘记最初的任务目标。此外,如何将这种能力扩展到三维物理世界的动态连续操作,而非简单的多轮对话,仍是未来的重难点。
总结
ProactiveBench 告诉我们:一个真正的多模态巨兽不应该仅仅是知识的复读机,而应该是一个知道自己“不知道什么”并敢于要求协作的智能体。主动微调(Proactive Fine-tuning)可能是迈向 AGI 协作能力的一块重要拼图。