本文推出了 DiscoGen,一个用于自动发现机器学习算法任务的任务程序化生成器。该系统跨越了强化学习、计算机视觉等 10 个领域,能够生成超过 4 亿个具有独立 Meta-train/Meta-test 划分的独特任务,并配套推出了 DiscoBench 基准测试。
TL;DR
在 AI 自动做科研(AI Scientist)的浪潮下,我们是否拥有足够的“练习题”来训练最强科研智能体?本文提出了 DiscoGen,一个能自动产出 4 亿个机器学习算法开发任务的生成器。它不仅解决了测试集过小、数据污染等硬伤,还通过 DiscoBench 证明了当前的顶尖 LLM 在多模块协同开发时依然显得“力不从心”。
1. 痛点:科研智能体正在“背题”而非“思考”
目前的算法发现智能体(Algorithm Discovery Agents, ADAs)评估体系面临三大危机:
- 评估不规范:很多 Benchmark 直接在训练集上测表现,这在 ML 领域是重罪,无法衡量算法的迁移能力(Generalization)。
- 由于规模太小导致的过拟合:像 MLE-Bench 只有几十个任务,智能体很容易针对特定题目进行 Hardcoding。
- 数据污染:公开的 Kaggle 竞赛或经典算法代码早已存在于 LLM 的预训练语料中,智能体可能只是在复读,而非真正的“研究”。
2. 核心机制:模块化任务拆解
DiscoGen 的直觉非常清晰:将一个算法任务看作是多个积木的组合。
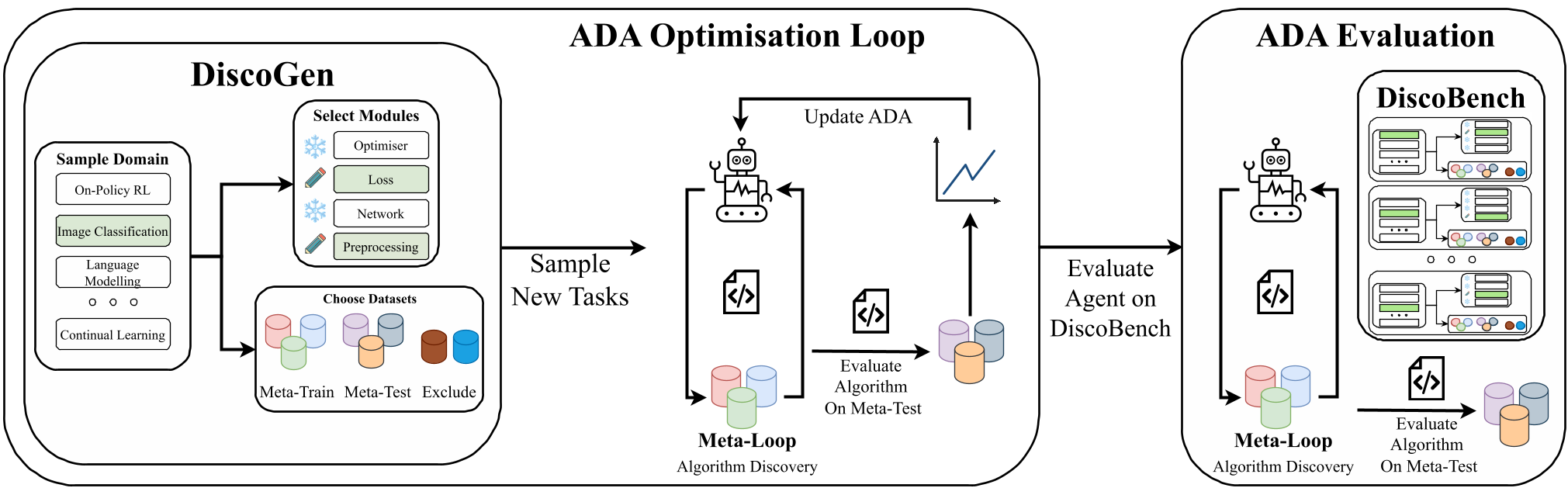
一个生成的任务由以下维度定义:
- Task Domain:涵盖强化学习 (On/Off-Policy)、语言模型、计算机视觉、脑电信号处理等 10+ 领域。
- Editable Modules:这是核心创新。系统可以指定哪些部分是“空白”的(如仅给接口),哪些是“固定”的。你可以让 AI 只写一个 Loss,也可以让它同时搞定架构和优化器。
- Meta-train/test Split:自动分配不同的数据集(如在 MNIST 上开发,在 CIFAR 上验证),严查泛化性。
这种组合爆炸产生的能力是惊人的。计算公式如下(详见原文公式 1): $$N_{tasks} = 2 \cdot 3 \cdot b \cdot (2^{m} - 1) \cdot (3^{d} - 2^{(d + 1)} + 1)$$ 仅在“在策略强化学习(On-Policy RL)”一个领域,通过组合不同的网络、Loss、训练循环和 13 个环境,就能生成 4.2 亿个任务。
3. 实验发现:LLM 的“深水区”
作者利用 DiscoGen 的子集 DiscoBench 对 Deepseek-v3.2 等模型进行了压力测试。

核心发现:
- 难度阶跃:当任务仅涉及一个模块(Single)时,Deepseek 成功率尚可;但当需要同时编辑多个模块(All)时,成功率断崖式下跌(从 80% 跌至 25%)。这说明 LLM 难以处理代码间的长程逻辑耦合。
- 泛化失效:许多智能体发现的算法在训练集(Meta-train)表现优异,但在未见的测试集(Meta-test)上甚至不如 Baseline。这意味着 AI 也会“刷榜过拟合”。
4. 深度洞察:为什么程序化生成是未来的关键?
本文最重要的价值在于它开启了 Meta-meta-learning。
在过去,我们手动设计 Prompt。但在 DiscoGen 下,我们可以:
- 自动优化提示词:正如第 7 章所示,在 30 个多样化任务上跑出来的 Prompt,其表现远超在单一任务上死磕的结果。
- 训练“算法世界模型”:利用生成的数百万个“算法-性能”对,可以训练一个专门预测“改动这段代码会如何影响准确率”的模型,作为智能体的辅助筛选器。
5. 总结与反思
DiscoGen 证明了:算法发现不仅仅是代码补全,而是对泛化能力的极限挑战。目前的 LLM 在处理复杂、多模块协同的科研任务时仍有巨大提升空间。
局限性: 虽然任务是生成的,但底层的代码框架仍需人类专家编写。未来的方向应该是如何让 AI 自动开拓全新的“领域(Domain)”。
关键词:Algorithm Discovery, Procedural Generation, LLM Agents, Meta-Learning, DiscoGen.