本文推出了 ProcureGym,这是一个基于马尔可夫博弈(Markov Game)的多智能体数据驱动模拟平台,专门用于建模中国国家组织药品集中采购(NVBP)。该平台利用 7 轮真实的 NVBP 数据(涵盖 325 种药物和 2,267 家企业),提供了一个高保真的模拟环境,支持强化学习(RL)、大语言模型(LLM)及规则算法的评估。
TL;DR
本文介绍了 ProcureGym,首个针对中国国家组织药品集中采购(NVBP)定制的多智能体马尔可夫博弈模拟平台。通过集成 7 轮真实集采数据,该平台不仅能高精度预测企业的中标行为(准确率达 74.81%),还通过 LLM 和 RL 的对比实验,揭示了药企在复杂监管下的报价逻辑。
痛点深挖:为什么集采博弈难以模拟?
自 2018 年启动以来,中国药品集采(NVBP)显著降低了药价,但也让决策环境变得极其复杂。药企作为理性的“自私代理人”,需要在信息不完全的条件下平衡市场份额风险与其生产成本极限。
现有的建模方法存在明显局限:
- 博弈论分析:往往依赖于过度简化的均衡假设,无法处理成百上千家企业的异质性。
- 传统代理模型 (ABM):行为规则僵化,无法模拟企业在面对政策变动时的策略演进(即卢卡斯批判)。
- 通用经济模拟器:如 AI Economist 侧重税收政策,缺乏对药品集采中“量价挂钩”、“价格联动”等微观规则的精细建模。
方法论详解:马尔可夫博弈下的集采建模
作者将集采过程抽象为一个 10 维向量组成的马尔可夫博弈,这不仅包括政策参数(最高限价 $P_{max}$、约定采购比例 $\rho$ 等),还通过真实数据分布采样了企业的生产成本 $C_i$。
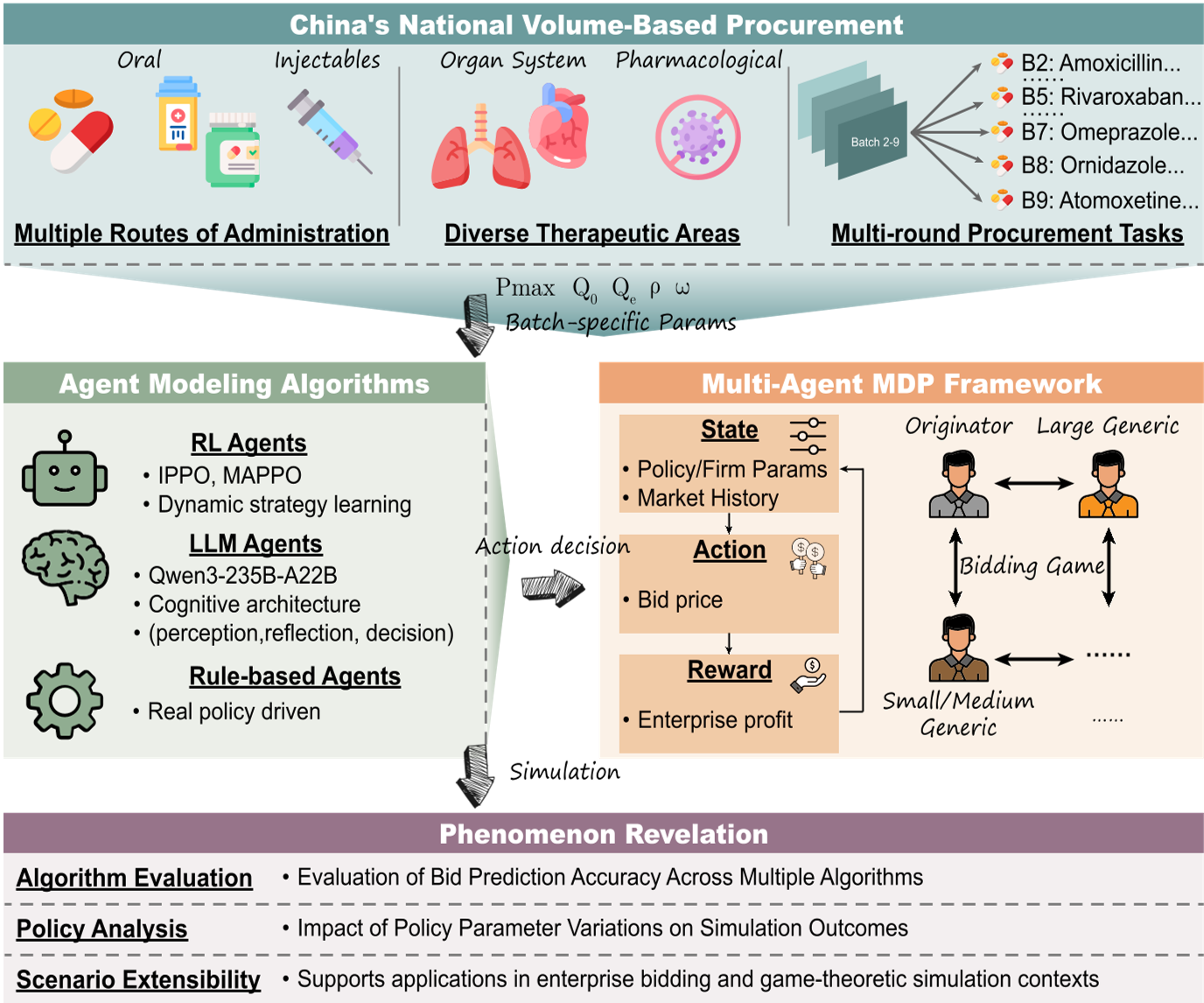
核心机制:
- 状态空间 (State Space):捕捉了包括企业规模、原研与否、原料药自给率等微观属性。
- 动作空间 (Action Space):智能体决定报价 $P_t$,其范围被严格约束在 $[C_i, P_{max}]$ 之间。
- 奖励函数 (Reward Function):直接定义为瞬时利润,倒逼智能体在“降价保中标”和“高价保利润”之间寻找最优平衡点。
实验与结果:RL 的强势与 LLM 的直觉
研究对比了 IPPO/MAPPO(强化学习)、Qwen(大模型)及基于规则(Rule-based)的三类智能体。
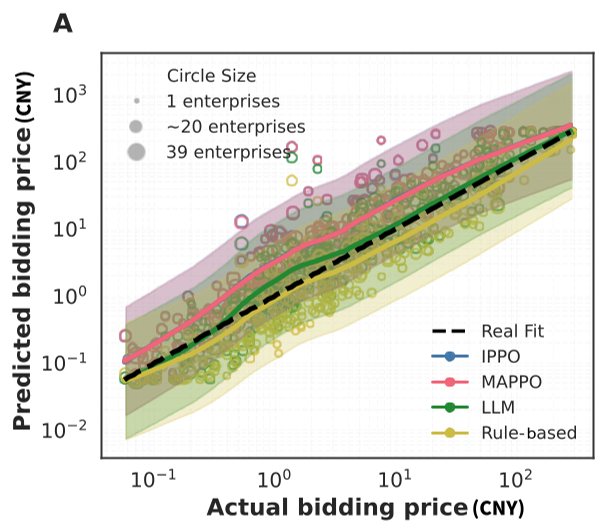
- 性能领先:强化学习(RL)不仅在报价预测的 Spearman 相关性上表现最优,其获胜者预测准确率也远超其他基线。这表明 RL 能够通过反复迭代捕捉到集采中非线性的竞争压力。
- 逻辑增强:虽然 LLM 在数值精准度上略逊于 RL,但其展现了强大的战略解释性。LLM 智能体能以自然语言解释其调价逻辑(如:“由于成本处于中等水平,策略性上调报价以恢复财务可行性”),实现了决策过程的可解释。
深度洞察:政策变动的敏感性分析
通过在 ProcureGym 中进行抗压测试,作者发现:
- 最高有效申报价 ($P_{max}$) 是影响报价最敏感的政策杠杆,直接决定了行业的盈利基调。
- 市场总需求量 ($Q_e$) 对利润的贡献远大于采购成本的节约。
- 低成本企业倾向于激进报价以锁定市场份额(报价常低于 $P_{max}$ 的 30%),而高成本企业则在中标边缘反复横跳以寻求利润空间。
总结与局限
ProcureGym 成功地将 AI 技术引入到了极具挑战性的公共卫生经济领域。尽管目前模型主要侧重于企业端的报价行为,尚未完整结合政府和医疗机构的复杂反馈闭环,但它为后续的反事实政策推理(即:如果规则变了,药价会怎么走?)提供了极其坚实的实验平台。
对于医药企业,这是一个优化的“报价教练”;对于政策制定者,这则是评估政策波纹效应的“显微镜”。