本文提出了 RecGPT-Mobile,这是首个在移动端部署 LLM 进行推荐意图理解的框架。该方法通过轻量化 Qwen3-0.6B 模型,配合自适应 Prompt 构建与意图漂移触发机制,实现了在端侧实时将用户行为转化为搜索查询(Next-query Prediction),显著提升了淘宝 Feed 流的推荐精度。
TL;DR
在移动互联网时代,用户的购物兴趣瞬息万变。传统的“云端计算”由于延迟问题,往往当你已经买完东西,系统还在推荐刚才搜过的商品。RecGPT-Mobile 改变了这一游戏规则——它是业内首个将大语言模型(LLM)直接部署在手机端的推荐框架,通过实时分析用户行为并自动生成精准的搜索 Query,实现了点击率(+1.8%)和交易额(+2.5%)的双重增长。
核心痛点:云端推荐的“滞后性”与“高昂代价”
推荐系统的本质是捕捉用户潜意识中的下一个需求。目前主流的 SOTA 方法虽然开始引入 LLM 来提升语义理解,但面临两大死穴:
- 端延迟 (Latency):用户在手机上刷淘宝时,每一次点击都代表意图的变化。如果行为数据传回云端、LLM 推理、再传回客户端,这长达数百毫秒甚至秒级的链路足以让“实时感”丧失。
- 算力成本 (Cost):面对淘宝数亿级别的活跃用户,如果全部依靠云端千亿参数模型进行每秒数万次的并发推理,其服务器硬件投入将是天文数字。
方法论:如何在“螺蛳壳里做道场”?
为了在手机有限的 RAM 和算力(NPU/GPU)中运行 LLM,作者提出了一套完整的“降维打击”策略。
1. 架构总览
RecGPT-Mobile 的核心流程分为:用户行为收集 → 自适应 Prompt 构建 → 意图 Agent(LLM)→ 本地/云端检索。
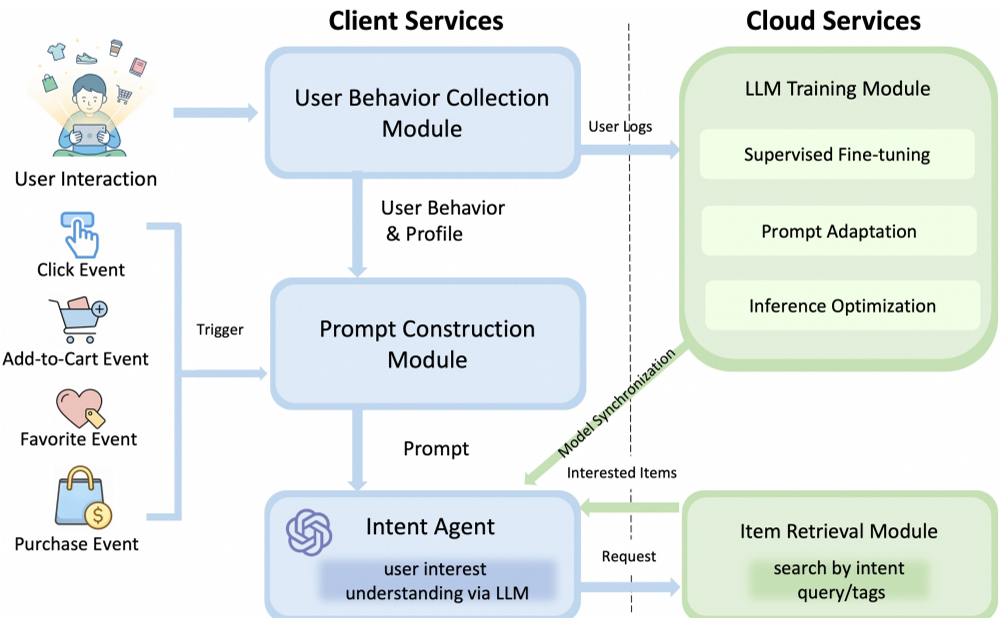 图 1:RecGPT-Mobile 整体架构,展示了从手机本地数据收集到 LLM 意图生成的全流程。
图 1:RecGPT-Mobile 整体架构,展示了从手机本地数据收集到 LLM 意图生成的全流程。
2. 自适应 Prompt 构建(Adaptive Prompting)
手机端的资源模型(Budget)是随时变化的。算法 1 提出了一套基于得分模型的动态 Prompt 方案:
- 特征提取:提取用户行为的频率、多样性、新鲜度。
- 模板与结构自适应:系统会根据当前的计算余量,决定 Prompt 的详略程度。如果电量充足、算力空闲,就提供更详细的上下文;反之则精简。
3. 意图漂移触发机制(Trigger Pipeline)
这是节省端侧功耗的神来之笔。LLM 并不需要在每次点击时都运行。
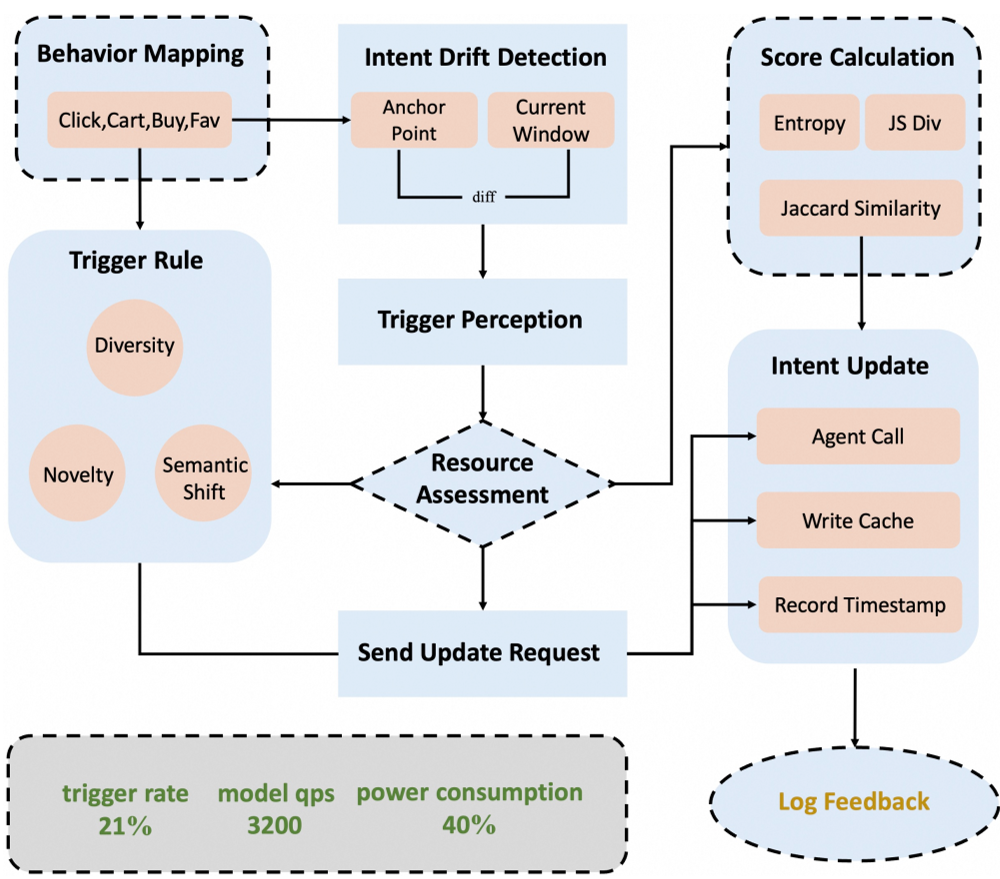 图 2:意图漂移检测 pipeline。
图 2:意图漂移检测 pipeline。
作者引入了三个数学逻辑来判断“什么时候该让 LLM 出马”:
- 熵变 ():用户意图是变得专注了还是更发散了?
- Jaccard 相似度:前后两个行为窗口的语义重合度。
- JS 散度:显式度量分布偏移。 只有当融合后的漂移分值 时,才会唤醒 LLM。
实验战果:端侧模型也能打
模型采用了 Qwen3-0.6B 作为底座,并进行了量化 LoRA 微调。实验数据表明,即使经过了极度压缩,模型在语义一致性和逻辑连贯性上依然保持了满意的水平。
| 场景 | CLICK (点击) | PAY (成交) | GMV (交易额) | | :--- | :--- | :--- | :--- | | 购物车页面 | +2.5% | +2.7% | +2.9% | | 物流追踪页 | +2.4% | +2.9% | +3.0% | | 平均提升 | +1.8% | +2.7% | +2.5% |
表 1:淘宝多个核心场景下的在线 A/B Test 结果。
在高分位延迟(P95)测试中,RecGPT-Mobile 表现出了极强的鲁棒性,没有因为长尾行为导致手机卡顿或发烫,证明了其在工业级生产环境的可行性。
深度洞察
RecGPT-Mobile 的成功本质上是对**端侧 Inductive Bias(归纳偏置)**的极佳利用。它不再追求 LLM 能够“上知天文下知地理”,而是将其约束为一个极其专业的“意图翻译官”。其提出的控制触发频率和自适应 Prompt 思想,对于所有希望在移动端部署 AI Agent 的开发者而言,都极具参考价值。
总结:未来的大模型应用,或许并不全在云端。RecGPT-Mobile 告诉我们,一个懂你当下、反馈迅速、且不消耗额外带宽的端侧小模型,往往能发挥出意想不到的巨大业务价值。