本文推出了 Principia 这一针对复杂数学对象(如矩阵、分段函数)推理的基准与数据集,并提出了两种核心算法:RLLM(基于在线训练 LLM 作为奖励模型的统一对齐框架)和 ParaGator(通过在线 RL 学习多样化生成与测试时聚合的方法)。在 PrincipiaBench 上,该方法显著提升了 Llama 和 Qwen 系列模型的推理能力,并在 AIME(数学竞赛)和 GPQA(研究生级问答)中展现了跨格式的泛化性能。
TL;DR
Meta FAIR 团队发布的这篇文章是一项极具野心的工作,它不仅指出了当前 LLM 推理评估的“多选题陷阱”,还通过 Principia 数据集、**RLLM(模型即奖励)**和 **ParaGator(在线聚合)**三位一体的改进,让模型开始学习派生矩阵、分段函数等复杂数学对象。实验证明,这种针对复杂对象的训练不仅能刷爆新基准,还能意外带动 AIME 等传统数学任务的跨越式提升。
1. 痛点:被“多选题”宠坏的模型
目前的 AI 能够通过 AIME 或 GSM8K 考试,但它们真的会推理吗?作者发现,当把 SuperGPQA 中的单选题选项删掉,让模型直接写出数学表达式时,强如 o3 和 Qwen3-235B 的性能都会下降 10-20%。
原因很简单:模型学会了**“倒推法” (Backward Chaining)**。模型在有选项时会以此为锚点,而在真正复杂的科研场景(比如推导物理方程)中,并没有选项可以参考。此外,现有的 math-verify 库在面对 LaTeX 格式略有差异的等价表达式时极易报错,导致 RL 信号质量极差。
2. Principia 体系:为“硬核推理”定制数据
为了解决这一问题,作者构建了 PrincipiaBench 和 Principia Collection。
- 覆盖范围:涵盖等式、不等式、区间、集合、矩阵、分段函数。
- 构建机制:利用 GPT-OSS-120B 基于 MSC2020(数学分类)和 PhySH(物理标题)进行分级生成,并结合 Transitivity-aware Majority Voting(考虑传递性的众数投票)机制,确保合成数据的标签准确性。
 图:模型在有选项时的捷径行为与无选项时的逻辑崩溃对比
图:模型在有选项时的捷径行为与无选项时的逻辑崩溃对比
3. RLLM:把 Rewards 交给“会思考”的模型
传统的奖励模型(RM)是一个输出标量的黑盒,难以解释且容易被 Trick。 RLLM (Reinforcement Learning with LM as RM) 提出:既然我们要优化推理模型,那为什么不用一个推理能力更强的 LM 来当老师?
- J1 流程:先训练一个“会思考”的 RM。它不仅给分数,还要给出一段
<think>过程来解释为什么这个答案是错的。 - On-policy 优势:通过在训练中实时采样 Policy 模型的输出来迭代 RM,解决了分布偏移(OOD)带来的评判失准。
- 结果:即使是 1.7B 的微小模型,在 32B 的“思考型老师”指导下,其数学能力也能大幅跃升。
4. ParaGator:学会“查缺补漏”的聚合者
并行推理(Parallel Thinking)是当前的趋势,但简单投票(Majority Vote)无法处理“一堆错解中藏着一个对解”的情况。 ParaGator 的核心直觉是:
- 多样性生成:在生成候选解时,使用 Pass@k 优化,不再要求每个解都对,而是要求“这组解里至少有一个是对的”,这迫使模型去探索不同的解题路径(模式去塌陷)。
- 主动合并:训练模型作为一个聚合器(Aggregator),通过阅读前面的 N 个解,自动修正错误、提取有效步骤,并生成终版答案。
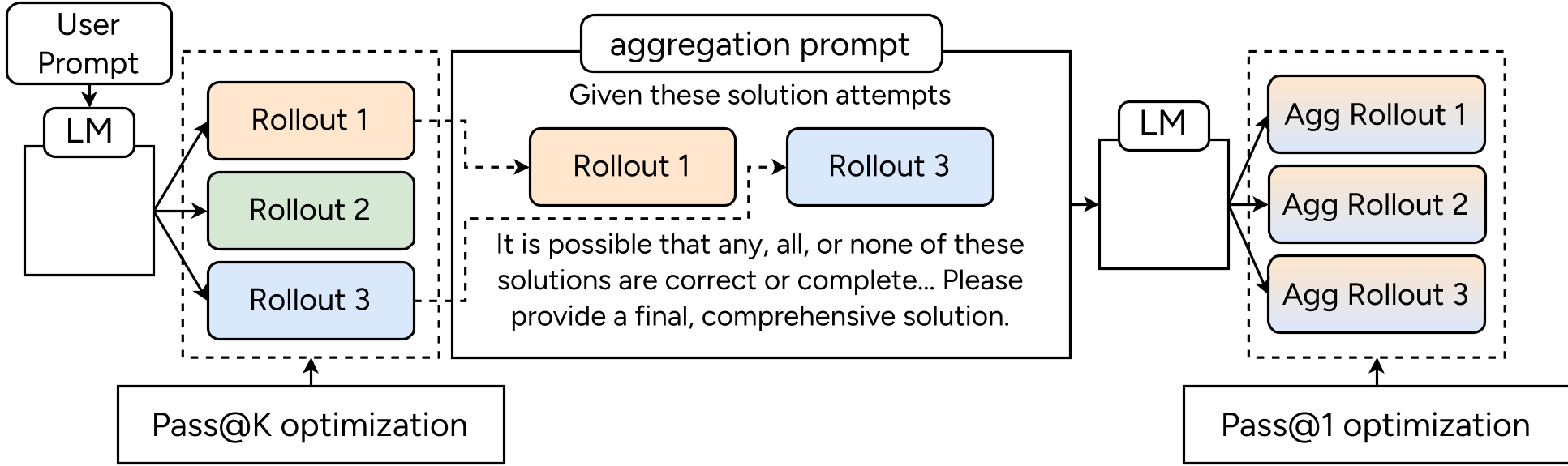 图:ParaGator 的训练流程:Pass@k 采样 + Pass@1 聚合
图:ParaGator 的训练流程:Pass@k 采样 + Pass@1 聚合
5. 实验战绩与洞察
- 战绩:在 PrincipiaBench 上,所有的基础模型经过 Principia Collection 训练后都获得了 7-18% 的绝对提升。
- 意外惊喜:专门针对“复杂数学对象”训练的模型,在 AIME(数值任务)上的表现竟然比直接用数值任务训练的模型更好。这说明:掌握了更难的结构化推导,简单的数值计算只是其能力的子集。
- 关键发现:模型作为校验器(Model-based Verifier)的 Recall 远高于规则校验器。
6. 总结与启示
Meta 的这项工作标志着 LLM 推理研究的一个转折点:
- 告别 Benchmarking 虚假繁荣:数值和多选题无法承载真正的逻辑深度,Principia 代表了更真实的需求。
- 自循环的闭环:通过推理模型评判逻辑(RLLM),再通过在线 RL 修正逻辑,这可能是通往真正“自我进化” AI 的关键路径。
未来的模型不仅要考高分,更要能像科学家一样,在一片虚无中推导出那行整齐的矩阵方程。
注:文中涉及的 Principia-7B-Zero, ParaGator-4B 等模型与数据集已在作者提供的 Huggingface 链接中发布。