本文提出了 SIDReasoner,一个通过在语义 ID(Semantic IDs, SIDs)上进行推理来增强生成式推荐的两阶段框架。该方法结合了多任务对齐细调、教师模型引导的内容增强以及基于 GRPO 的强化学习,在多个数据集上刷新了生成式推荐的 SOTA。
TL;DR
传统的推荐系统往往是“直觉式”的概率预测,而 SIDReasoner 赋予了 LLM 在推荐前进行“逻辑思考”的能力。通过增强 Semantic ID (SID) 与自然语言的语义对齐,并利用强化学习(GRPO)优化推理路径,该方法不仅大幅提升了推荐精度,还解决了生成式推荐中长期存在的“黑盒”难题。
核心定位
在学术坐标系中,SIDReasoner 处于 生成式推荐 (Generative Recommendation) 与 大模型推理 (LLM Reasoning) 的交汇点。它不是简单的 Prompt Engineering,而是通过底层词表扩充与强化学习,实现了从“预测概率”到“推理意图”的本质跨越。
痛点深挖
目前的生成式推荐面临两大“深水区”课题:
- 语义鸿沟:虽然我们可以把商品编码成
<a_1><b_2>这样的 SID,但 LLM 并不理解这些 token 代表什么。对于模型来说,它们只是冷冰冰的数字,无法调动 LLM 预训练阶段习得的惊人常识。 - 评价困境:我们知道推荐结果对不对(Hit Rate),但我们不知道模型“想得对不对”。缺乏显式的推理标注,让模型空有强大的思维链(CoT)能力却无处施展。
方法论详解:两阶段进化
SIDReasoner 提出了一套数据驱动的流水线,分为“对齐”与“强化”两步:
1. 语义对齐:打破数字僵局
作者没有直接训练模型做推荐,而是先训练模型“说话”。通过调用 GPT-4o-mini 作为教师模型,合成了大量混合了 SID 和自然语言的语料:
- 项中心增强:让模型描述一个商品,并强制在描述中嵌入其 SID。
- 用户中心增强:以叙事化的方式描述用户的购物历史及其背后的动机。
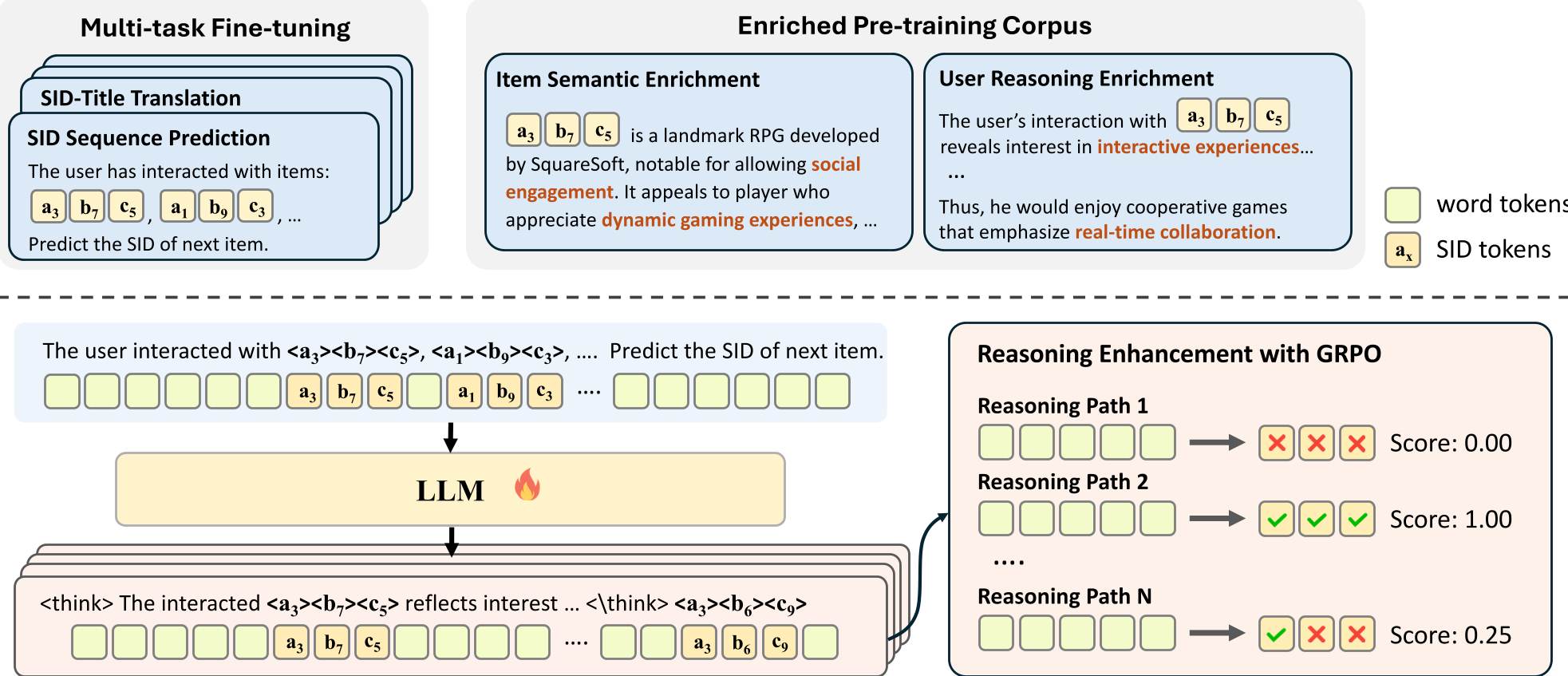 图 1: SIDReasoner 的两阶段框架:从对齐到强化训练
图 1: SIDReasoner 的两阶段框架:从对齐到强化训练
2. GRPO 强化学习:结果导向的路径优化
在模型学会“理解”SID 后,作者引入了 GRPO(Group Relative Policy Optimization)。有趣的是,这里不需要人工告诉模型如何推理。模型会尝试多个推理分支(Rollouts),如果某个推理逻辑最终导向了正确的商品预测,它就会获得正向奖励(Reward)。这种“结果反推过程”的训练方式,让模型学会了最适合推荐任务的简洁逻辑。
实验与结果分析
SIDReasoner 在 Amazon 多个数据集上展现了压制性的性能:
| Model | Games (R@10) | Office (R@10) | Industrial (R@10) | | :--- | :--- | :--- | :--- | | SASRec (传统) | 0.0723 | 0.1167 | 0.0964 | | TIGER (生成式) | 0.0763 | 0.1429 | 0.1325 | | SIDReasoner | 0.1031 | 0.1648 | 0.1438 |
 注:即便在模型知识较少的工业品类上,SIDReasoner 依然保持了领先。
注:即便在模型知识较少的工业品类上,SIDReasoner 依然保持了领先。
关键发现:
- 跨域泛化:在一个领域学到的推理逻辑(如“分析用户对特定品牌的忠诚度”),可以无缝迁移到另一个完全不同的商品领域(见图 3)。
- 自我进化:随着强化学习的进行,模型生成的推理文字会变得越来越精炼(见图 5),剔除无关废话,直击用户痛点。
案例研究:透明化的决策过程
如图 6 所示,模型在推荐“Reflet amiibo”之前,先自我分析道:“系统观察到用户多次购买《火纹》及 Nintendo 相关周边,表明用户对角色驱动类策略游戏有强烈的收藏欲……”这种思考过程不仅提高了准确率,更让推荐系统具备了前所未有的可解释性。
 图 6: 模型如何通过“Let's think step by step”最终锁定目标商品
图 6: 模型如何通过“Let's think step by step”最终锁定目标商品
深度洞察与总结
SIDReasoner 的成功揭示了一个深刻的趋势:推荐系统的未来不再仅仅是特征工程的竞赛,而是语义对齐的深度挖掘。 当我们将商品转化为 LLM “听得懂、说得出”的语言符号时,推荐任务便从纯粹的点击率预估转化为了高级的意图推理。
局限性: 虽然模型在学术数据集上表现优异,但在超大规模工业场景(如数亿级候选池)中,SID 的多阶段解码延迟及训练显存压力仍是亟待解决的挑战。