本文提出了 Visual Re-Examination (VRE),这是一个旨在增强多模态大模型 (MLLM) 视觉推理能力的自演进训练框架。通过引入“视觉再检查”机制,模型能够在其生成的推理链中主动重新关注原始图像特征,从而在 7B 参数规模下显著提升了在 MathVista、V*-Bench 等复杂推理任务中的表现。
TL;DR
多模态大模型(MLLM)在长文本推理时常常“虎头蛇尾”——刚开始看图说话,后半段就开始胡编乱造(即 Visual Drift)。来自中科大、华为及港科大的研究团队提出了 Visual Re-Examination (VRE),不仅让模型学会了在推理过程中“回头看”,还通过自迭代强化学习,在不借助外部插件的情况下,让 7B 模型在视觉感知与数学推理指标上刷新了 SOTA。
1. 痛点:为什么 MLLM 会“视而不见”?
在复杂的多模态任务(如几何证明、精密 OCR 提取)中,模型需要维持极长的推理链(CoT)。研究者发现,随着推理步数的增加,模型对图像 Token 的关注度(Attention Weight)呈单调下降趋势。
- 视觉漂移 (Visual Drift):模型生成越长,就越倾向于依赖语言模型的文本先验(Textual Priors)。
- 感知的“偶然性”:模型有时能看清,有时却“间歇性失明”。
- 现有方案的弊端:以往靠动态切图(Cropping)或调用外部工具(Tools)的方案就像给模型配“义肢”,虽然有效但增加了延迟,且容易导致感知对齐失调。
2. 核心直觉:挖掘潜伏的“检查员”
研究团队通过注意力分析发现,MLLM 内部其实存在一种潜在的后期视觉验证能力,只是它在推理时处于“休眠”状态。
VRE 的核心思想是:不需要外部老师教,也不需要新工具,通过模型自我博弈与迭代,将这种偶尔出现的“回头看”行为固化成一套可学习的策略。
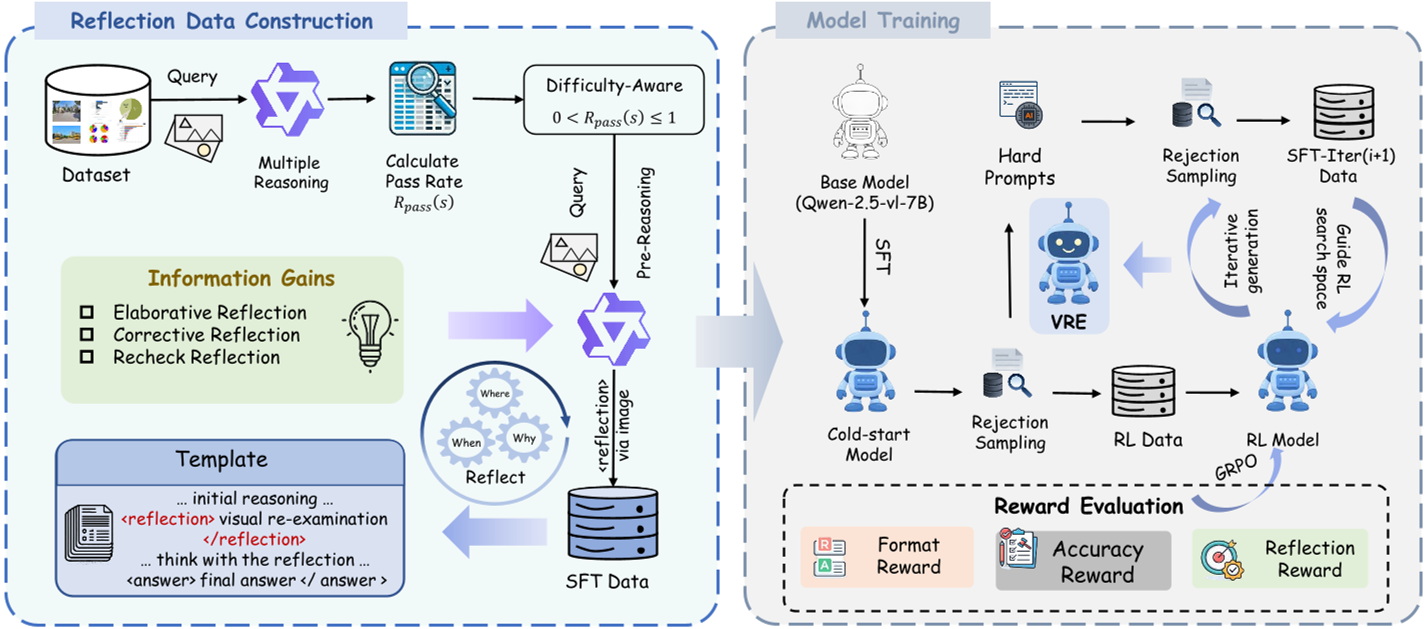 图 1:VRE 框架概览。通过对比不同阶段的推理轨迹,筛选出具有“信息增益”的反射片段。
图 1:VRE 框架概览。通过对比不同阶段的推理轨迹,筛选出具有“信息增益”的反射片段。
3. 方法论:VRE 的三阶自进化
VRE 的训练过程形成了一个闭环:
- 冷启动 SFT(Cold-Start):利用模型自身在不同温度下的采样结果,识别出那些“原本错了但通过反思能对”的轨迹,建立起
<reflection>格式的初步认知。 - 强化学习 (RLVR):采用 GRPO 算法,不仅奖励最终答案的正确性(Accuracy Reward),更关键的是引入了 Reflection Reward。只有当反射步骤提供了新增的视觉信息(而非废话)时,模型才会获得正反馈。
- 同源重构 (Homologous Reconstruction):强制要求推理和反射使用同一个 Vision Encoder,防止产生“驴唇不对马嘴”的感知偏差。
4. 实验战绩:小模型的大爆发
在 7B 参数量级上,VRE 展现出了惊人的韧性。
- *视觉感知 (V-Bench)**:VRE 达到 83.8%,超越了 DeepEyesV2 和 Thyme 等依赖复杂工具的模型。
- 数学推理 (MathVerse):相比基座 Qwen2.5-VL-7B 提升了 3.9%,证明了“回头看”对逻辑链纠错的巨大价值。
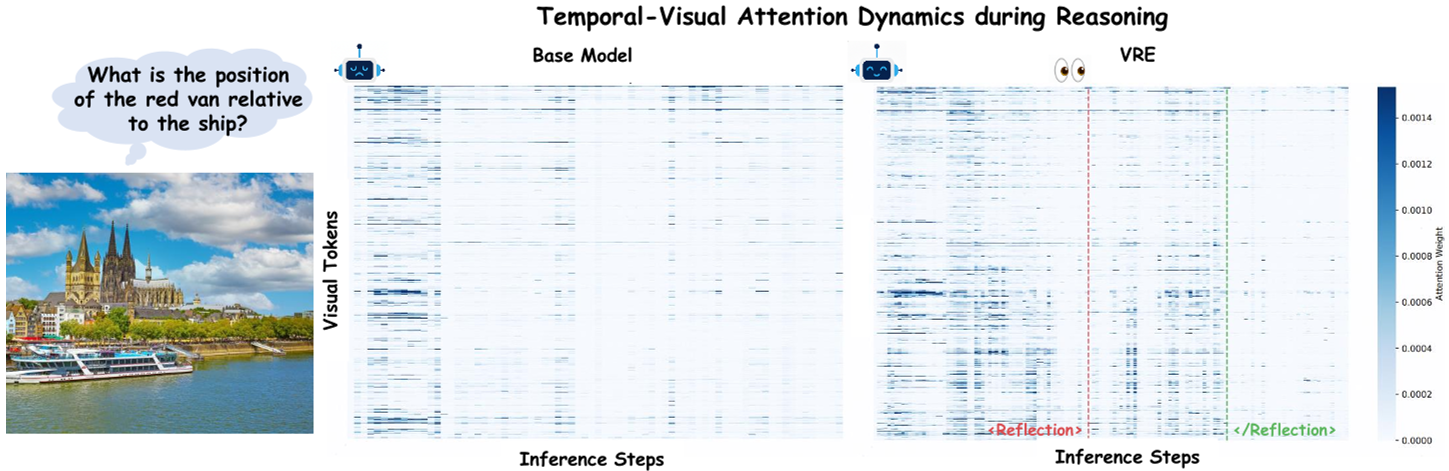 图 2:注意力可视化对比。基座模型(左)视觉注意力随步数消散,而 VRE(右)在反射阶段(Reflection Block)精确出现了注意力“脉冲回升”。
图 2:注意力可视化对比。基座模型(左)视觉注意力随步数消散,而 VRE(右)在反射阶段(Reflection Block)精确出现了注意力“脉冲回升”。
5. 深度洞察:模型到底在看什么?
VRE 训练出来的模型展现了三种高级反射行为:
- 纠错型 (Corrective):发现前面的视觉理解错了,定位到新区域重新提取特征。
- 核查型 (Recheck):即便算对了,也要在最后确认一次图中的关键数据,提高鲁棒性。
- 补充型 (Elaborative):针对 OCR 等密集任务,主动补充背景细节。
通过 Conditional Entropy(条件熵) 验证,VRE 生成的反射内容具有极高的信息密度,彻底解决了模型常见的“自我复读”问题。
6. 局限性与展望
尽管 VRE 在 7B 分布上表现优异,但其推理成本相比基础推理略有增加(因为多了一次反射步骤)。未来的研究方向可能会探索如何将这种“视觉再检查”在更底层的 Transformer 架构中并行化,实现真正的“单次前向、多次聚焦”。
总结:VRE 告诉我们,多模态推理的瓶颈可能不在于 Vision Encoder 不行,而在于推理机(LLM)不懂得如何有效地、有目的地去调用现有的视觉信号。“多想一点,多看一眼”,简单直观的直觉往往能带来 SOTA 级别的突破。