本文提出了 Residual-as-Teacher (RaT) 方法,一种用于学生-教师(Student-Teacher)估计的新型架构。该方法通过让教师模型估计学生预测的残差而非直接拟合教师输出,在核岭回归(KRR)等任务中达到了 minimax 最优收敛率,显著优于传统匹配方法。
TL;DR
在学术界和工业界(如 DeepSeek, OpenAI),“学生-教师”范式是模型压缩与适配的核心。但传统方法(Soft Matching)存在一个致命伤:学生会全盘继承教师的偏见。MIT 的这项研究提出 Residual-as-Teacher (RaT),将教师的角色从“授课者”转变为“改错者”,通过迭代修正残差,使学生模型在理论和实验上均突破了教师的偏差瓶颈,达到了 Minimax 最优性能。
痛点深挖:为什么“好学生”学不到最优?
传统的知识蒸馏或伪标签学习(Pseudo-labeling)通常采用软匹配(Soft Matching, SM)。逻辑很简单:让学生去拟合教师给出的预测值。
然而,论文指出,任何教师模型(无论是随机森林、核方法还是多层神经网络)都自带 Inductive Bias(归纳偏见)。例如:
- 树模型倾向于轴对齐的阶梯函数。
- 浅层 RelU 网络倾向于低频振荡函数。
- 核回归的性能受限于正则化参数 $\lambda$。
在 SM 模式下,学生被强制要求“长得像教师”,这导致教师的系统性偏差(Systematic Bias)直接传播。即便你拥有海量的无标签目标数据,学生也只能在错误的道路上越走越远。
核心直觉:残差即梯度
作者的灵感来自于优化理论中的近端梯度下降(Proximal Gradient Descent)。
在 RaT 架构中,训练不再是一次性的模仿,而是一个迭代过程:
- 教师查漏补缺:教师模型不预测标签,而是预测学生当前预测值与真实标签之间的残差(Residuals)。
- 学生近端更新:学生利用教师预测的残差值作为“代理梯度”,在目标函数上进行一次近端映射更新。
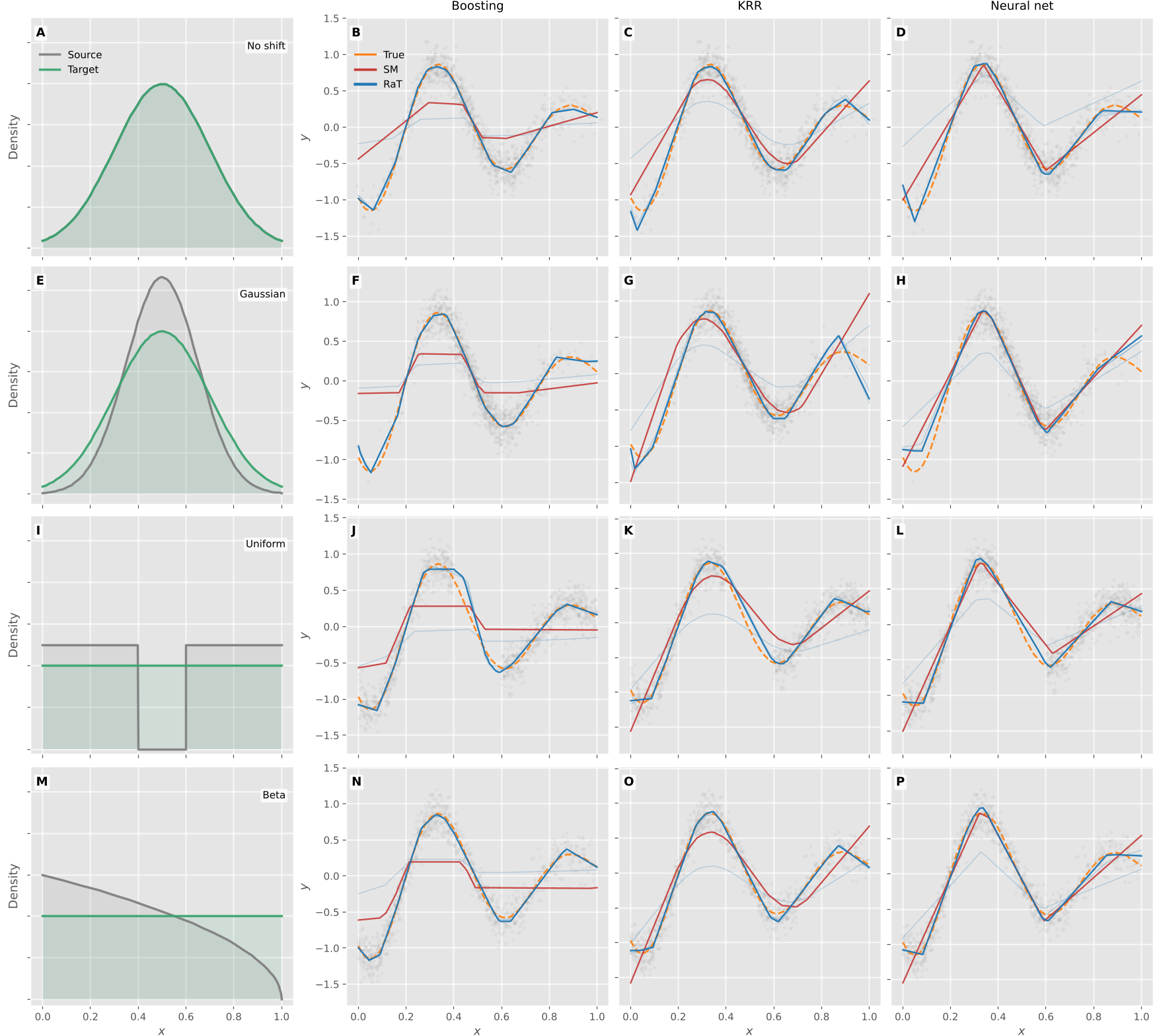 图 1:RaT 与 SM 在不同教师模型(Boosting/KRR/NN)下的拟合对比。可以看到 RaT(蓝色)能精准修正偏差,而 SM(红色)始终受限于教师。
图 1:RaT 与 SM 在不同教师模型(Boosting/KRR/NN)下的拟合对比。可以看到 RaT(蓝色)能精准修正偏差,而 SM(红色)始终受限于教师。
这种变换的深刻之处在于:教师的偏见现在只影响对“残差项”的估计,而不是对“整个函数”的估计。
理论成就:Minimax 速率的完美证明
论文在数学上提供了一个极具冲击力的 Separation Result。 在存在协变量偏移(Covariate Shift)的核回归场景下:
- RaT 上界:通过调整学生的正则化参数 $\gamma$,RaT 能达到 $n^{-\frac{2\beta}{2\alpha+1}}$ 的收敛率。
- SM 下界:无论如何调整参数,SM 的预测误差始终大于一个正的常数 $c_1$。
这意味着:RaT 是统计一致的,而 SM 在偏差面前是无能为力的。
实验验证:ImageNette 与 协变量偏移
为了验证在真实复杂场景下的有效性,作者在 ImageNette 数据集上施加了不同强度的图像噪声(Pixelate/Elastic Blur)。
 图 2:在 ResNet 特征空间中,随着腐蚀等级增加,RaT 在交叉熵损失上的表现明显优于 SM,且在教师模型极度受限(如 Hidden Units=4)时优势更巨。
图 2:在 ResNet 特征空间中,随着腐蚀等级增加,RaT 在交叉熵损失上的表现明显优于 SM,且在教师模型极度受限(如 Hidden Units=4)时优势更巨。
资深主编点评
这篇论文最精彩的地方在于它并没有去设计一个更复杂的网络,而是重新审视了 Loss Function 的结构。它告诉我们,在“师生对话”中,教师不应该给出“标准答案”,而应该指出“学生哪里做错了”。
局限性:目前的收敛性证明(Theorem 3)在很大程度上依赖于算子的强单调性和近似粘性(Co-coercivity),这在非凸的深度学习景观中可能难以完全满足。
未来研究方向:这种残差反馈机制是否可以引入到当前火热的 LLM RLHF 过程中?如果 Reward Model 也能作为“残差教师”来修正 Policy,或许能有效缓解奖励模型的偏差传播。