本文建立了残差神经网络(ResNets)在深度 L、隐藏层宽度 M 和嵌入维度 D 同时趋于无穷大的联合极限下的训练动力学收敛性理论。作者证明了在最大局部特征更新(MLU)机制下,ResNet 的训练轨迹会收敛于一个确定的动力学系统,并给出了量化误差界。
TL;DR
本文实现了深度学习理论的一项重大突破:首次严格证明了包含深度(L)、宽度(M)和嵌入维度(D)在内的全维度 ResNet 在训练动力学上的联合极限收敛性。作者利用统计物理中的 Cavity Method(空腔方法)克服了高维相关性难题,给出了 empirically tight(经验紧致)的收敛速率 O(P^-1/6),并为“为何深度模型的宽度应比深度增加得更快”提供了坚实的数学解释。
背景定位:从宽度极限到全维度极限
在 AI 理论研究的坐标系中,我们曾先后经历了 宽度极限(NTK 机制与平均场理论)和 深度极限(Neural ODE)。然而,真实世界的模型(如 Llama 系列)并非只增加某一个维度。
现有的 Tensor Programs 框架虽然处理了宽度极限,但在处理“无限深度 + 无限宽度”的联合收敛时,往往需要假设特定的缩放比例。本文填补了这一空白:它不要求 L、M、D 成比例增长,而是给出了一个普适的动力学极限。
痛点与动机:为什么 D 趋于无穷很难?
当嵌入维度 D 趋于无穷时,权重矩阵的每一行在训练过程中产生的相关性会通过反向传播不断累积。
- Prior Work 的局限:以往的分析通常假设 D 固定,或者直接假设权重在极限下保持独立(Propagation of Chaos)。
- 物理直觉:作者意识到,在嵌入空间中,更新项之间其实存在一种类似自旋玻璃(Spin Glass)理论中的长程交互。为了量化这种交互,必须引入 Cavity Method。
方法论详解:骨架映射与空腔方法
1. 模型架构与 MLU 机制
作者研究的是带有两层感知器(2LP)块的标准 ResNet:
 这种结构在 Maximal Local Update (MLU) 机制下运行,确保了即便在无限规模下,模型依然能进行有效的 Feature Learning(特征学习),而非退化为线性核机制(Lazy Training)。
这种结构在 Maximal Local Update (MLU) 机制下运行,确保了即便在无限规模下,模型依然能进行有效的 Feature Learning(特征学习),而非退化为线性核机制(Lazy Training)。
2. 骨架映射 (Skeleton Maps)
为了解析权重更新,作者定义了骨架映射 和 。其核心 Insight 是:权重的更新仅仅取决于输入特征和反向传播梯度的路径。通过这种路径依赖的表达,复杂的张量运算被简化为初等函数及其梯度的递归关系。
3. 空腔方法 (The Cavity Method)
这是本文最精妙的数学处理。为了分析第 个坐标的演化,作者将其余 个坐标视为一个“环境”(Cavity),并对这个环境中的微小扰动进行一阶泰勒展开。
这种方法神奇地抵消了公式中 的发散项,揭示了即便 D 极大,每个坐标的独立性依然可以在均值场意义下被保持。
实验与结果
收敛速率的紧致性
作者通过数值实验验证了误差界 。
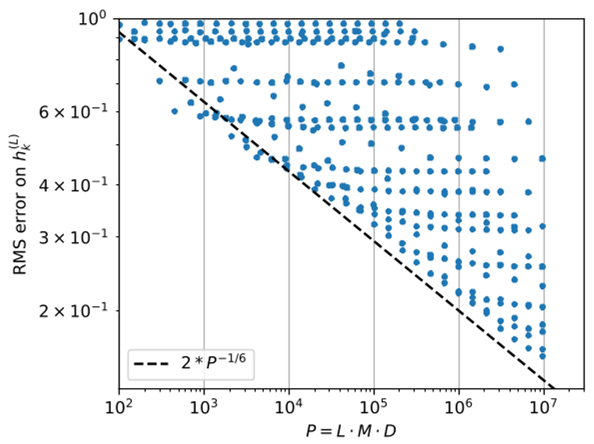 图 (a) 显示了随着嵌入维度 D 增加,隐藏层表示的 RMS 误差严格符合 的下降趋势。
图 (a) 显示了随着嵌入维度 D 增加,隐藏层表示的 RMS 误差严格符合 的下降趋势。
线性情形的显式解
在线性激活函数 时,极限系统可以简化为一组显式的 ODE 系统。
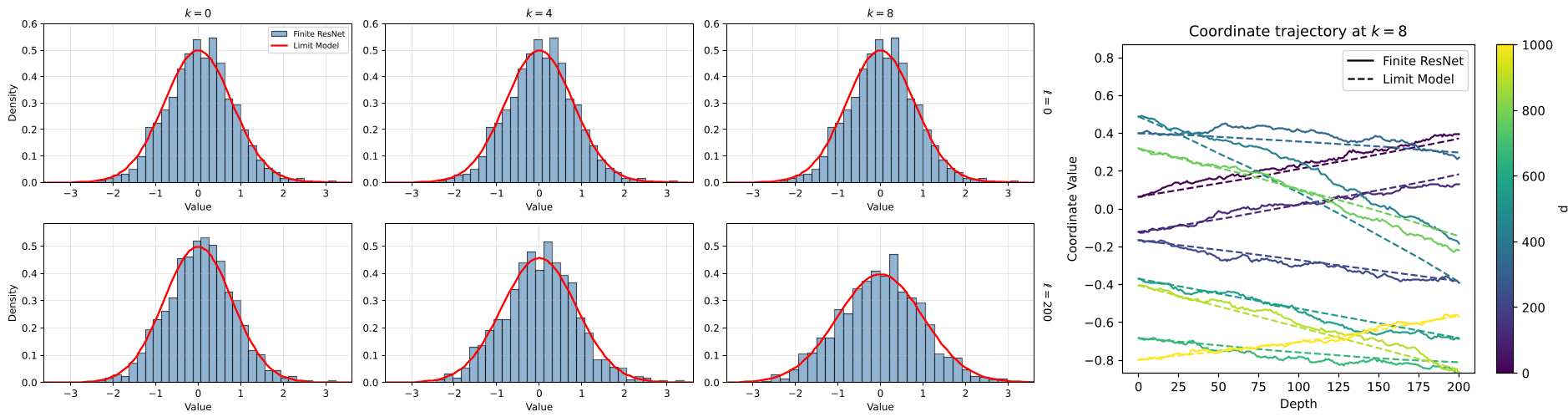 如上图所示,有限规模模型的坐标轨迹(彩色线)完美地围绕着极限模型的概率密度函数(红色线)演化,证明了理论极限的预测能力。
如上图所示,有限规模模型的坐标轨迹(彩色线)完美地围绕着极限模型的概率密度函数(红色线)演化,证明了理论极限的预测能力。
深度洞察:未来的模型长什么样?
Takeaway 1: 最优形状 如果你的总参数量预算是 ,为了让你的模型最接近那个“完美的无限极限”,你应该如何分配 L、M、D? 根据本文推理:
- 深度 L 增加最慢:
- 宽度 M 和 D 同步增加: 即:宽度应按深度的平方速度增长。这一理论结论与 Llama 3 等流行架构的比例设计惊人契合。
Takeaway 2: 从 ResNet 到 Transformer 虽然本文主要讨论 ResNet,但作者指出,该理论框架(骨架映射)可以形式化地推广到 Attention 机制。只要 Key-Query 的维度 保持固定,Transformer 的动力学同样遵循这一全维度极限。
总结
这篇论文将复杂的动力学平均场理论(DMFT)引入了严格的神经网络量化分析中。它告诉我们,大规模模型的稳定训练并非巧合,而是存在一个确定性的、可预测的数学极限。对于追求极致模型性能的工程师来说,理解这一“尺度定律(Scaling Law)”背后的动力学极限,是迈向下一代大模型的必经之路。