本文提出了 ExpRAG,一种结合经验检索与微调的 LLM Agent 框架。通过在系统提示词中注入通过 LoRA 微调学习到的历史轨迹,该方法在 ALFWorld 和 ScienceWorld 任务中显著提升了智能体的泛化能力,并在未见过的任务(Unseen Tasks)上达到了 SOTA 性能。
TL;DR
在 LLM Agent 领域,模型在训练集里很强、一换任务就抓瞎(OOD 崩溃)是长期存在的痛点。NAVER LABS Europe 的这项最新研究指出:我们不需要复杂的读写记忆机制。通过 ExpRAG-LoRA,在微调阶段就强迫模型看着检索出来的“历史攻略”做题,不仅能刷高 SOTA,更让模型获得了在未见过任务上的恐怖泛化力——在 ALFWorld 硬核任务上,泛化性能直接从 34% 飙升到了 88%。
1. 痛点:Agent 的“考试焦虑症”
目前的 LLM 智能体主要面临两大困境:
- 微调陷阱:用 LoRA 做行为克隆(Behavior Cloning)虽然能让模型在训练过的任务上很稳,但一旦任务指令变了(比如从“清洁物体”变成“加热物体”),模型就会因为分布偏移而完全失效。
- 检索无力:传统的 RAG 只是把文档塞给模型。对于 Agent 来说,检索出的历史轨迹往往很长且充满噪音,Frozen(冷冻)的模型经常不知道该看哪里,导致“Training-free”的效果甚至不如简单的 SFT。
2. 核心直觉:教模型“翻书考试”
作者认为,提升泛化性的关键不是“记住答案”,而是“学会查阅经验”。 他们提出了 ExpRAG 流程:
- 离线阶段:构建全量经验库(成功和失败的轨迹都留着)。
- 训练阶段 (ExpRAG-LoRA):在通过 LoRA 微调模型时,并在 Prompt 里动态注入检索到的
Top-K条轨迹。这强制模型在训练时就得学会在参考资料(Memory Block)和当前环境观测(Observation)之间建立逻辑关联。
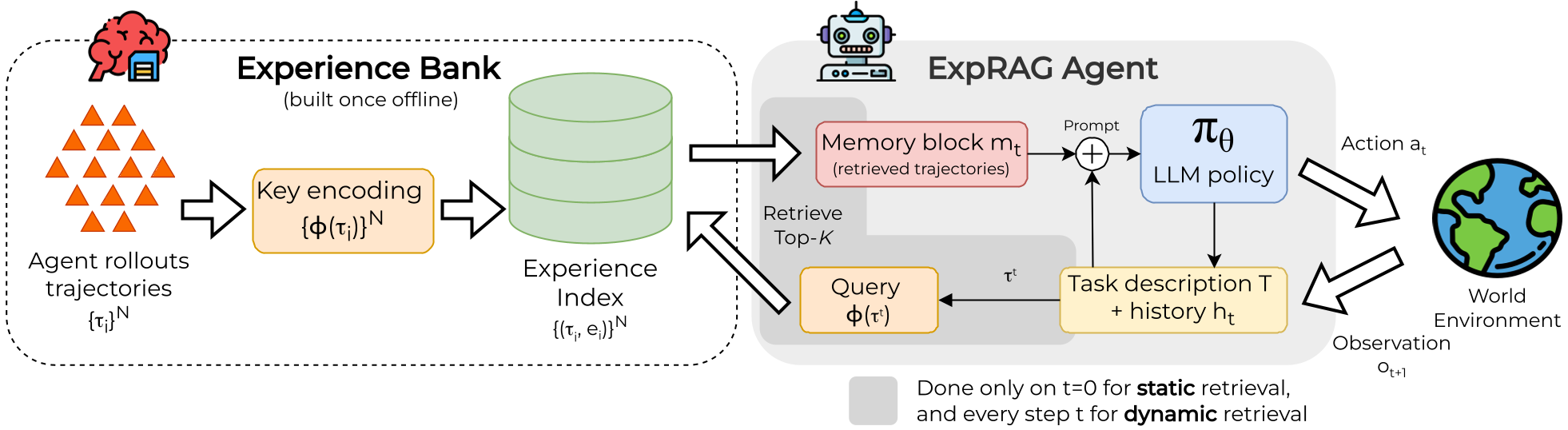 图 1:ExpRAG 流程图。离线构建经验库,推理时动态检索 Top-K 轨迹并注入系统提示词。
图 1:ExpRAG 流程图。离线构建经验库,推理时动态检索 Top-K 轨迹并注入系统提示词。
3. 方法论深挖
3.1 轨迹序列化
作者没有采用常见的“单步编码”,而是使用了 Multi-turn Chat (JSON) 格式。
- 优点:充分利用 KV-cache 重用,训练速度大幅提升,且保留了对话连贯性。
- 发现:JSON 格式对于 Qwen 等长文本模型非常友好,而纯文本(Textual)格式在 Top-K 增加时会导致性能下降(噪音干扰)。
3.2 延迟泛化现象(Delayed Generalization)
这是一个非常有趣的学术发现:在 Agent 的微调中,即使 Validation Loss 开始上升(看似过拟合),模型在未见过任务上的成功率竟然还在持续爬升。
- 作者建议不要过早停止训练(Early Stopping),在他们的实验中,50 个 Epochs 往往比 10 个 Epochs 的泛化效果更好。这与学术界研究的 Grokking 现象不谋而合。
4. 实验结果:泛化性的降维打击详解
在 ALFWorld 的“硬核”实验中,ExpRAG-LoRA 的表现极其亮眼。
 表 3:不同模型在 Easy(分布内)和 Hard(分布外)任务下的表现。可以看到 ExpRAG-LoRA 在 Hard 任务上远超传统 LoRA。
表 3:不同模型在 Easy(分布内)和 Hard(分布外)任务下的表现。可以看到 ExpRAG-LoRA 在 Hard 任务上远超传统 LoRA。
关键结论:
- 分布外(OOD)翻盘:传统的 LoRA 在 Hard 任务上几乎全线崩溃(低至 1.6%),而 ExpRAG-LoRA 能够稳在 70%-90%。
- 推理效率:虽然 Top-4 检索会让每一步的推理时间增加(从 0.43s 升至 1.03s),但由于 Agent 决策更准、步骤更少,在某些复杂任务下,总任务完成时间反而更短。
5. 局限性与洞察
- 索引依赖:如果检索不到任何相关的经验(Empty Index),模型性能会大幅下降。此时,保留一份“训练集索引”作为保底,效果好过没有。
- 长文本能力是基石:Qwen 2.5-7B-1M 展现了比普通版本更强的 Top-K 容忍度,说明长文本优化对于 Retrieval-based Agent 至关重要。
总结
ExpRAG-LoRA 告诉我们,Agent 构建不一定非要追求复杂的读写内存管理。回归本质,通过微调教授模型如何“借鉴”历史,才是解决泛化难题的一力降十会的方案。