本文针对大语言模型(LLM)的策略内蒸馏(On-policy Distillation, OPD)进行了深入研究,提出了“教师 Top-K 局部支持匹配”(Teacher Top-K Local Support Matching)算法。该方法通过在教师模型的高概率 Token 集合上进行局部分布对齐,解决了传统采样 Token 蒸馏的不稳定性问题,在数学推理和多模态 Agent 任务中取得了显著的 SOTA 性能。
TL;DR
策略内蒸馏(On-policy Distillation, OPD)是提升大模型复杂推理能力的核心技术,但传统的“根据采样 Token 计算 log-ratio”的方法在长文本下极易崩溃。本文揭示了采样 Token 蒸馏的三个致命失效模式,并提出了一种教师 Top-K 局部支持匹配(Top-K Local Support Matching)机制。通过将点估计升级为局部分布对齐,该方法在数学推理和 Agent 任务中实现了更稳健的 SOTA 提升。
1. 痛点:为什么传统的 OPD 容易“跑偏”?
在长程任务(如连续数学推导或多步 Agent 交互)中,学生模型生成的轨迹(Rollouts)往往会逐渐偏离教师模型的训练分布。此时,传统的采样 Token 蒸馏(Sampled-token OPD)会暴露三个严重缺陷:
- 信号失衡:如图 2 所示,大部分被采样的 Token 都会收到负奖励,正向引导信号极度稀缺,导致优化过程被少数“偶然正确”的 Token 绑架。
- 教师失效:当学生模型进入“复读机”模式或生成了奇怪的 Prefix 时,教师模型虽然会给当前 Token 高分,但整个轨迹已经毁了。
- 分词器(Tokenizer)陷阱:如果教师和学生分词规则稍有差异(如处理
<think>标签时),单 Token 对比会产生毁灭性的梯度干扰。
2. 核心直觉:从“序列”到“Token”的权衡
作者首先在理论上对比了序列级 reverse-KL 和 Token 级 OPD 的方差。
- 序列级 (Sequence-level):虽然目标最准,但方差随序列长度 以 指数级增长,几乎无法收敛。
- Token 级 (Token-level):虽然有偏,但方差仅为 。
作者的哲学:保持 Token 级的低方差优势,但由于采样 Token 太脆弱,我们应该在**局部范围内(Local Support)**进行分布匹配,而不是只看那一个点。
3. 技术方案:教师 Top-K 局部支持匹配
该方法不再仅仅关注学生采样出的那个 ,而是在每个前缀 下执行以下三步:
- 确定支持集:提取教师模型概率最高的 个 Token。
- 局部归一化:在 集合内对学生和教师的概率进行重新缩放(Renormalization)。
- 计算截断 KL:最小化这个局部子空间内的 reverse-KL 散度。
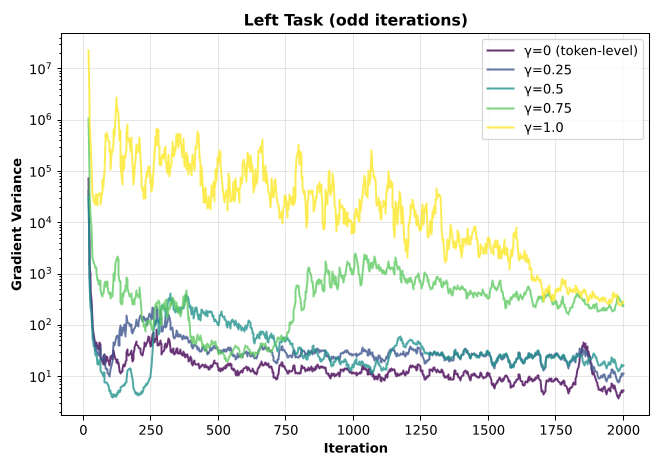 (图解:当 增大即耦合增强时,方差显著飙升,证明了保持局部性的必要性)
(图解:当 增大即耦合增强时,方差显著飙升,证明了保持局部性的必要性)
此外,作者引入了 Top-p 采样来约束轨迹质量,并使用 Special-token Masking 来规避不同模型间分词规则的冲突。
4. 实验战绩:数学与 Agent 双开花
实验在 Qwen2.5-7B 模型上展开。结果显示,在最具挑战性的 Math500 和 AIME 竞赛题目上,本文方法显著优于各种基线。
| Method | Math500 | AIME24 | Avg. Math | ALFWorld (Agent) | | :--- | :--- | :--- | :--- | :--- | | Qwen2.5-7B-It (Student) | 68.2 | 13.3 | 28.2 | 21.9 | | Sampled-token OPD | 80.0 | 10.0 | 36.4 | 90.6 | | Ours (Local Support) | 82.0 | 23.3 | 41.5 | 97.7 |
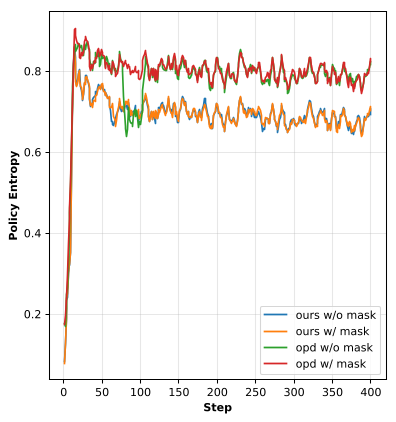 (图解:相比基线,本文方法拥有更平滑的梯度范数和更低的 Clipping 频率,优化过程极其稳定)
(图解:相比基线,本文方法拥有更平滑的梯度范数和更低的 Clipping 频率,优化过程极其稳定)
5. 深度洞察:奖励黑客(Reward Hacking)的隐忧
尽管局部对齐改善了训练,但作者诚实地指出:教师匹配(Teacher Matching)并非完美任务成功的代理。在一些坏案例(Appendix D)中,即使学生模型在胡言乱语,由于其每个 Token 在局部上都符合教师的“口癖”,教师模型依然会给出高概率。这意味着局部优化必须与全局奖励(如 Outcome Reward)结合,才能彻底解决 LLM 的推理稳定性问题。
总结
这篇论文为 OpenAI o1 风格的推理模型训练提供了极具参考价值的工程指南。它告诉我们:不要迷信单一采样的反馈,在“教师认同的局部空间内”进行分布对齐,才是兼顾效率与鲁棒性的正确姿势。