本文提出了 RPiAE (Representation-Pivoted Autoencoder),这是一种基于预训练视觉表示模型的图像分词器。通过引入“表征锚点正则化”和分阶段训练策略,该方法在保持高保真图像重建的同时,为扩散模型(Diffusion Models)提供了语义丰富的压缩潜空间,显著提升了图像生成与编辑的质量。
TL;DR
在 Latent Diffusion Model (LDM) 的范式中,分词器(Tokenizer)直接决定了潜空间的“质量”。本文提出的 RPiAE 巧妙解决了预训练表征模型在生成任务中的“水土不服”:通过表征锚点正则化和变分桥接,它既保留了 DINOv2 这类模型的强大语义,又实现了像素级的重建精度。实验表明,它在图像生成和精细化编辑上均刷新了记录。
背景定位:分词器是 LDM 的隐藏瓶颈
自 SD 和 Flux 爆火以来,研究者的重心多放在 Diffusion Transformer 结构的堆叠上,而忽略了定义潜空间的 VAE。
- 传统 VAE:重建好,但空间杂乱,扩散模型学得痛苦。
- 表征重用(如 RAE):直接拿预训练模型当编码器。语义虽强,但为了保语义通常冻结编码器,导致重建细节丢失(一编辑就变脸/糊掉);且维度太高,扩散模型推理开销大。
RPiAE 的出现正是为了终结这种“既要又要”的矛盾。
核心动机:如何优雅地解锁编码器?
作者发现,提升重建上限必须微调编码器,但一旦微调,编码器就会为了“像素对齐”而丢掉“语义结构”。
为了解决这个 Drift(漂移)问题,RPiAE 提出了 Representation-Pivot Regularization。其直觉非常简单:训练时多放一个冻结的预训练副本(Pivot Replica)作为导师,强制微调中的编码器在提取特征时,不要偏离导师的表征空间太远。
架构详解:三位一体的改进
RPiAE 的结构包含三个关键部分:
- RM Encoder (Eθ):基于 DINOv2 初始化。它是可训练的,但受到
L_piv损失的约束。 - Variational Bridge (VB):由一对 Transformer 组成。它负责把 768 维的稀疏表征压缩到 64 维的紧凑潜空间,并引入 KL 散度约束,确保存储的是“扩散友好”的分布。
- Decoder (Dϕ):采用 ViT-XL 架构,负责最终的像素回显。
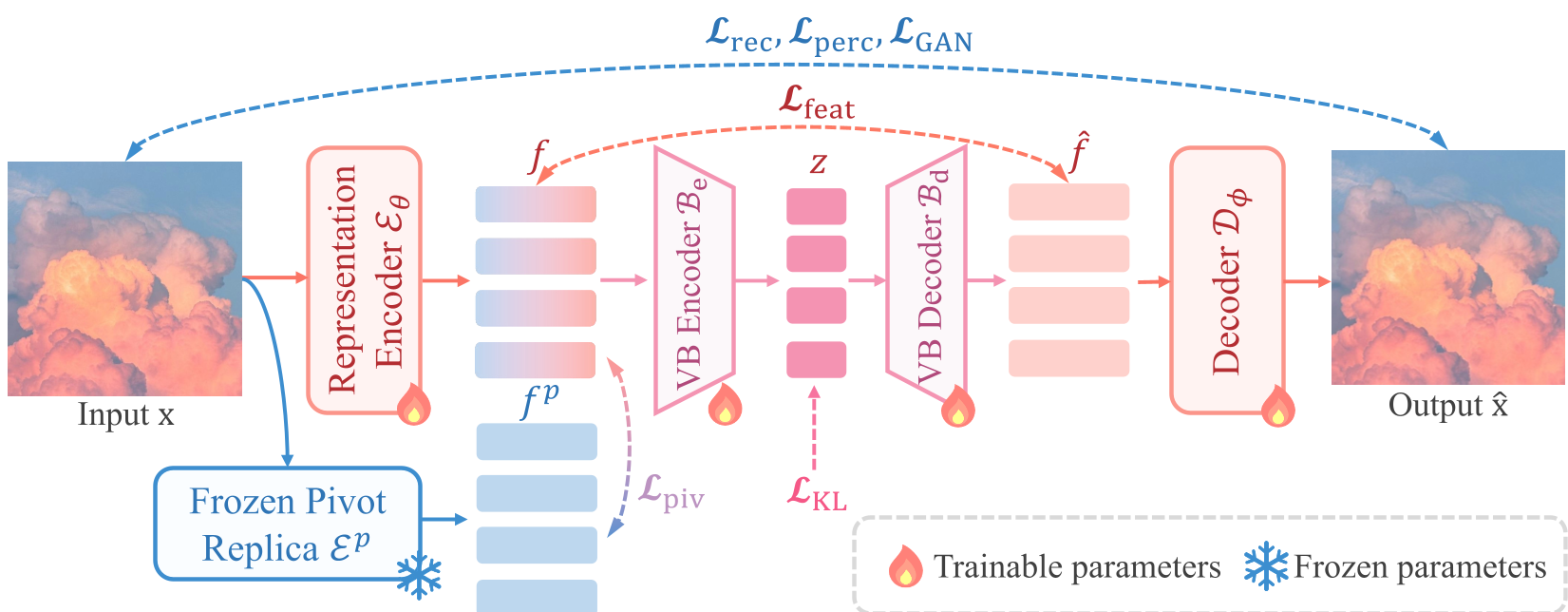
目标解耦的训练策略
为了训练稳健,作者将过程分为三步:
- Stage I:微调编码器和解码器,重点在“重建 + 表征对齐”。
- Stage II:冻结两头,只练中间的 Variational Bridge,重点在“潜空间压缩”。
- Stage III:冻结其他,单独精修解码器,重点在“消除伪影,提升视觉观感”。
实验战绩:重建与生成的双重胜利
在 ImageNet-1K 的评估中,RPiAE 展现了极强的统治力:
- 生成精度:gFID 达到 1.09,超越了包括 VA-VAE 和 RAE-B 在内的所有基线。
- 重建保真度:相比于同样基于 DINOv2 的 RAE,RPiAE 的 rFID 从 0.57 提升至 0.50,肉眼可见地修复了复杂的几何纹理(如网格、瓦片)。

图像编辑的“硬实力”
在 GEdit-Bench-EN 等编辑基准上,RPiAE 的优势更加明显。由于重建能力强,它在执行“给猫戴帽子”这类指令时,能完美保留猫的原始身份(Identity)和复杂的背景,而不会像其他模型那样出现颜色偏移或语义走样。

深度洞察:表征真的被保留了吗?
一个有趣的细节是,作者将 RPiAE 训练后的编码器直接接上原始 DINOv2 的分类头,发现 ImageNet Top-1 准确率仅下降了不到 0.4%(84.56 vs 84.18)。这有力地证明了 Pivot Regularization 的魔力:它在不破坏下游感知能力的情况下,成功让编码器学会了生成任务所需的细节。
总结与展望
RPiAE 的成功标志着“统一表征与生成”迈出了重要一步。它告诉我们,与其在大模型端死磕,不如回头把“潜空间”这个地基打牢。 局限性:尽管维度已经压缩,但对于超低算力平台,基于 ViT 的解码器推理延迟仍是一个挑战。 未来启示:这种“锚点微调”的思想可以进一步扩展到视频生成或 3D 资产生成等对空间结构极其敏感的领域。
本文由资深学术技术主编解读,更多前沿 arXiv 追踪请持续关注。