本文提出了 RubricRAG,一种通过检索相关查询的领域知识来自动生成实例级评估准则(Rubric)的方法。该方法旨在解决 LLM-as-a-judge 评分不透明的问题,实现了在 HealthBench 等基准上更具可解释性且与人类专家对齐的 SOTA 评估效果。
TL;DR
传统的 LLM 评估(如 GPT-4 打分)往往只给一个笼统的分数,就像批改作文只给个“良”,却不告诉你错在哪。本文提出的 RubricRAG 通过检索相似案例的专家评估标准(Rubrics),引导 LLM 生成针对特定问题的详细评分量表。这不仅让评估结果有了“由于缺少临床避险建议,扣 2 分”这种颗粒度的解释,还显著提升了自动化评估的准确性。
背景定位:从“单一分数”到“结构化反馈”
在模型开发和高风险部署(如医疗咨询)中,我们需要知道模型为什么回答得好或不好。现有的 LLM-as-a-judge 存在两个痛点:
- 不透明性 (Opacity):单一分值无法提供改进方向。
- 泛化性真空 (Generality Gap):通用的评估标准(如“回答是否流利”)无法涵盖特定问题(如“针对农村环境的产科急救建议”)的特殊需求。
本文的研究直觉在于:评估准则应当像定制服装一样量体裁衣(Query-specific)。
核心方法:RubricRAG 机制详解
作者发现,即便是最强的 LLM,在没有参考的情况下生成的准则往往是“车轱辘话”(通用但无用)。RubricRAG 的核心逻辑非常直观:
- 检索 (Retrieval):给定一个新的用户查询 ,利用 Qwen3-Embedding 等模型在已有的专家库中搜索最相似的案例。
- 上下文增强 (In-context Learning):将找回的专家准则作为示例,告诉模型:“看,类似的问题专家是这样制定评分标准的,请模仿这种深度”。
- 多策略优化:除了 RAG,作者还探索了 SFT (监督微调) 和 GRPO (群组相对策略优化)。其中 GRPO 通过奖励函数同时优化格式、多样性和词义重合度。
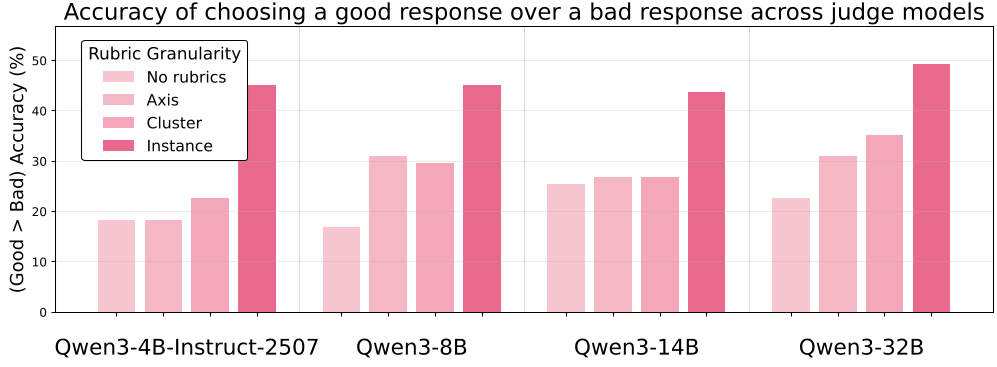 图 1:实验证明,越细粒度的准则(Instance-level),模型区分好坏回答的准确率越高。
图 1:实验证明,越细粒度的准则(Instance-level),模型区分好坏回答的准确率越高。
实验结果:RAG 战胜了微调?
在对齐人类专家的实验中,RubricRAG 展现出了惊人的生命力:
- 语义相似度大幅领先:在 HealthBench 硬核测试集上,RubricRAG (nothink) 的 LLM-Judge 得分达到 0.523,显著高于 Zero-shot 的 0.474。
- 下游评估一致性:使用 RubricRAG 生成的准则进行评分,其结果与使用人类金标准(Gold Rubric)评分的相关性最高(Spearman's ρ = 0.545)。
- 有趣的发现:SFT 虽然在字面重合度(BLEU/ROUGE)上得分很高,但在实际评估效果上却不如 RubricRAG。这说明模型在微调中可能学会了“模仿人类说话的语气”,但并没有真正理解“评估的逻辑”。
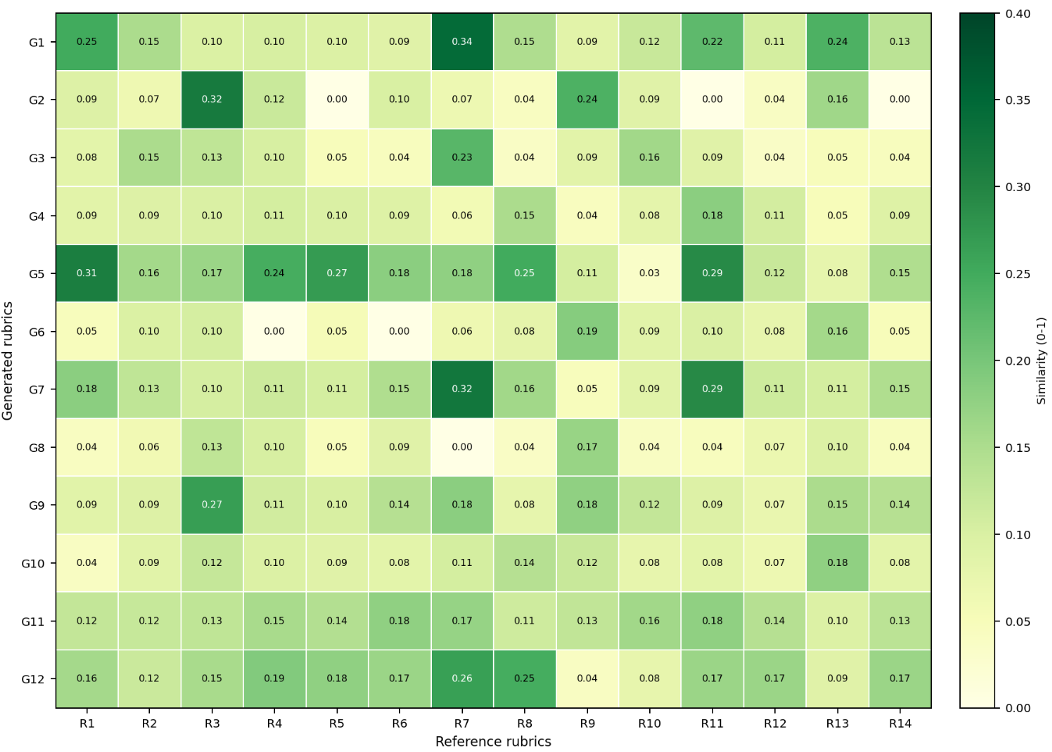 图 2:热力图显示 RubricRAG 生成的准则(右侧)比 Zero-shot(左侧)更密集地命中了专家关注的评估维度。
图 2:热力图显示 RubricRAG 生成的准则(右侧)比 Zero-shot(左侧)更密集地命中了专家关注的评估维度。
深度洞察:可解释性的代价
尽管 RubricRAG 表现优异,但作者也冷静地指出其副作用:冗余性 (Redundancy)。 由于检索回来的多个示例可能在强调同一点(例如都在强调“必须建议转院”),生成的准则有时会出现重复。这提示我们,未来的研究方向应关注语义去重(Semantic Deduplication)。
此外,论文还发现了一个“反直觉”的现象:在准则生成任务中,开启模型的 Thinking Mode (CoT) 有时反而会降低质量(即 Overthinking),导致准则变得嘈杂。这在追求标准化的评估场景中是一个值得警惕的信号。
总结与展望
RubricRAG 证明了:知识管理比单纯的模型扩容对评估更重要。 这篇论文为构建更可靠、更具反馈意义的自动化评估系统指明了方向。对于行业开发者而言,建立一个垂直领域的“专家准则库”,并配合检索增强技术,可能是目前提升 AI 评测公信力性价比最高的方案。
关键词: LLM Evaluation, Rubric-based, RAG, Interpretability, NAACL 2025