SAGE(Self-evolving Agents for Generalized reasoning Evolution)是一个针对大语言模型(LLM)推理能力的自进化框架。通过将单一模型实例化为 Challenger、Planner、Solver 和 Critic 四个专业代理,在数学和代码生成任务中仅需 500 条初始种子数据即可实现闭环自进化,在 LiveCodeBench 和 OlympiadBench 等 benchmark 上取得了显著提升。
TL;DR
传统的 LLM 推理训练往往需要几十万条高质量的人类标注数据。而本文提出的 SAGE 框架,仅依靠 500 条“种子数据”,通过将大模型分身为四个不同角色的代理(挑战者、规划者、执行者、评论家),在数学和编程领域实现了卓越的自驱动演化。在 Qwen-2.5-7B 模型上,不仅在 OOD(分布外)测试中大放异彩,还成功构建了一个规模扩大了 18 倍的高质量自动生成题库。
痛点深挖:为什么 Self-play 容易跑偏?
当前的 LLM 推理进化面临两个核心挑战:
- 数据荒:高质量的奥数或编程题标注成本极高,且模型达到一定水准后,人类数据将成为上限。
- 课程失效:许多自博弈(Self-play)系统在生成新任务时缺乏难度控制和路径规划。如果生成的题目太简单,模型原地踏步;太难或格式混乱,训练信号就会变成噪音,导致性能崩溃。
Methodology:四位一体的 SAGE 架构
SAGE 的核心直觉在于“角色解耦”。作者将模型能力拆解为四个互补的 Agent:
- Challenger (挑战者):负责“出题”。它不仅生成题目,还生成配套的 Verifier(如代码测试用例)。它的奖励函数很有趣——Solver 做错了,它才能拿高分(难度奖励),但前提是题目必须通过 Critic 的质量审核。
- Planner (规划者):负责“思路”。模型不再直接跳到答案,而是先产出结构化的步骤说明。
- Solver (执行者):负责“解题”。根据 Planner 的蓝图执行,通过外部验证器(Vgt)获取真实奖励。
- Critic (评论家):负责“质检”。对题目和规划进行打分,充当“过滤器”,只有高分项才能进入训练循环和数据池。
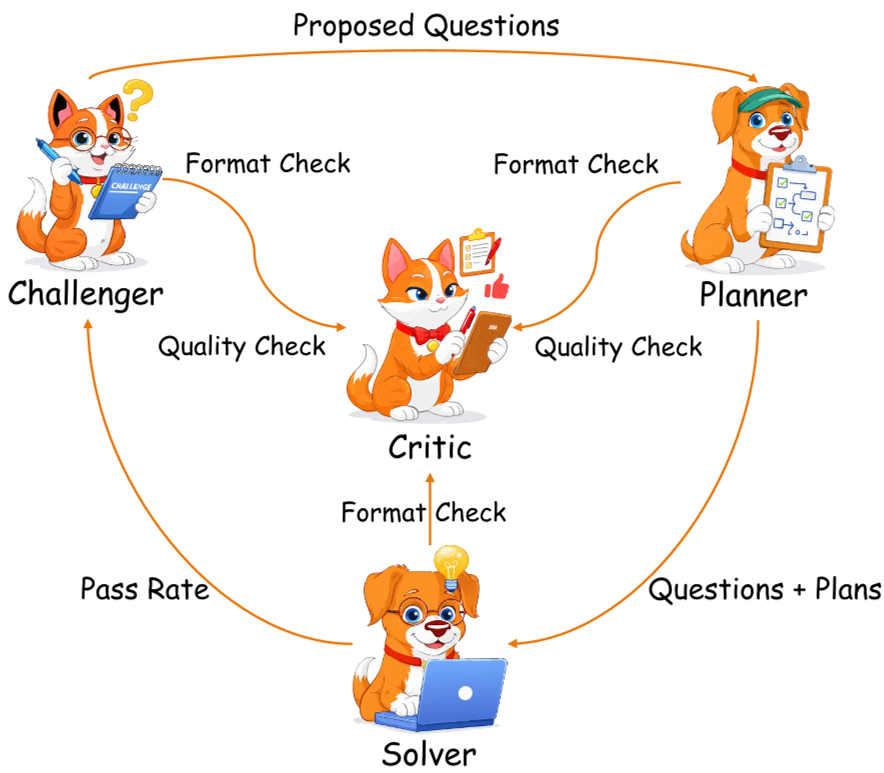 图 1:SAGE 框架概览,四个 Agent 通过反馈回路进行闭环进化。
图 1:SAGE 框架概览,四个 Agent 通过反馈回路进行闭环进化。
算法灵魂:Task-Relative REINFORCE++
为了让这四个角色协调训练,SAGE 采用了 Task-Relative REINFORCE++ 算法。它对不同角色的 Advantage(优势函数)进行归一化处理(Eq. 1),确保不同任务目标(如出题和解题)的梯度不会互相干扰,从而稳定了多代理的联合训练。
实验与结果:小样本驱动的大飞跃
实验选择了 Qwen-2.5 和 Qwen-3 系列作为 Backbone。
- SOTA 对比:在 Qwen-2.5-7B 上,SAGE 在 LiveCodeBench (LCB) 上的表现优于基线模型近 9%,在奥赛级别测试 OlympiadBench 上提升超过 10%。
- 泛化性突破:相比之前的 Absolute Zero (AZR) 或 MAE,SAGE 在从未见过的题目(OOD)上表现出了更强的鲁棒性。
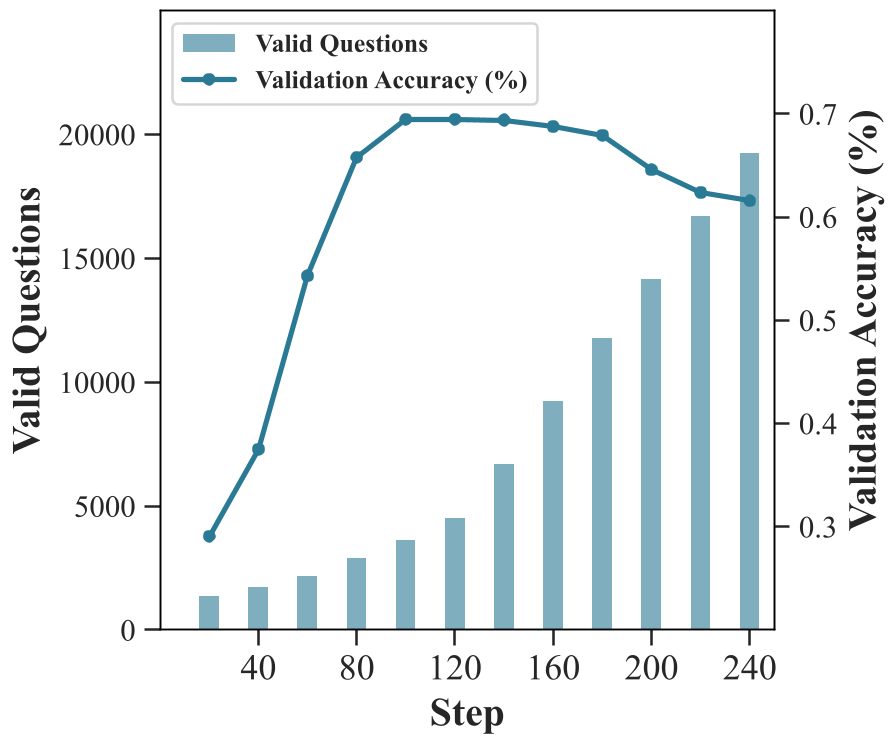 图 2:训练动态显示,Challenger 稳步扩大了有效题库(柱状图),并在 100-120 步左右达到性能峰值。
图 2:训练动态显示,Challenger 稳步扩大了有效题库(柱状图),并在 100-120 步左右达到性能峰值。
消融分析:谁是关键?
消融研究发现,禁用 Challenger 会导致代码任务性能大幅下滑,这证明了“自生成课程”对于泛化的至关重要。移除 Solver 训练则会导致整体崩盘,证实了 Solver 依然是推理能力沉淀的主体核心。
深度洞察与总结
SAGE 的成功提供了一个关键启示:大模型的推理能力提升不一定非得靠“灌入”更多知识,通过内部角色的博弈与细化的推理路径(Planning),模型可以“挖掘”出自身的潜力。
局限性 (Limitations): 目前 SAGE 仍然高度依赖“可验证环境”(即数学有标准答案,代码有 Unit Test)。对于没有客观评分标准的自然语言理解或创意任务,如何定义其 Critic 和 Verifier 仍是未来的挑战。
总结: SAGE 是一种极具采样效率的进化框架,它不仅提升了模型得分,更通过一套自动出题-自动过滤的机制,实现了数据的“自给自足”。