本文提出了 MOSAIC,一种用于端到端自动驾驶(E2E AD)系统的缩放感知数据选择框架。该方法通过将数据池聚类、在子域内拟合神经缩放定律(Scaling Laws)并迭代优化数据混合比例,在 EPDMS 驾驶规则合规性指标上显著超越了现有基准,最高可节省 80% 的训练数据。
TL;DR
在物理 AI(Physical AI)领域,尤其是端到端自动驾驶(E2E AD),我们不仅要追求模型“跑得远”,还要追求“不撞车”、“遵守交规”和“乘坐舒适”。英伟达与纽约大学的研究团队提出 MOSAIC,首次将神经缩放定律(Scaling Laws)引入数据混合优化。它不再盲目追求覆盖所有场景,而是通过计算每种数据的“投资回报率(ROI)”,实现了用不到 20% 的数据挖掘出 100% 的性能潜能。
背景定位
目前端到端自动驾驶模型(如 Hydra-MDP)通常依赖 PB 级的数据堆砌。但在实际部署中,模型面临的是由 NC(无碰撞)、DAC(驾驶区合规)等 9 项指标组成的复杂评价体系。MOSAIC 处于数据效率(Data Efficiency)与多目标优化(Multi-metric Optimization)的交汇点,是一个通用的、感知缩放规律的数据混合框架。
痛点深挖:数据不是越多越好,而是“边际效益”在作怪
传统方法如 Active Learning 偏向挖掘不确定性高的样本,Coreset 偏向挖掘多样性。但它们都忽略了两个核心物理事实:
- 指标竞争:在弯道数据上练多了,Lane Keeping(车道保持)上去了,但 Comfort(舒适度)可能会下降。
- 异构缩放:拉斯维加斯的繁忙交通数据对提升避障效果显著,但对提升郊区的车道线识别可能很快就进入“报酬递减”阶段。
核心算法解析:MOSAIC 的三部曲
MOSAIC 的核心直觉是:把数据选择问题转化为一个凸优化问题。
1. 聚类与排序 (Clustering & Ranking)
首先根据地理位置(如波士顿、匹兹堡)或语义标签(使用 Qwen-2.5-VL 生成描述)将数据池划分为 个域。并在每个域内按 EPDMS 指标对样本进行初步排序,确保“好的数据先上场”。
2. 拟合缩放定律 (Fitting Scaling Laws)
这是 MOSAIC 的灵魂。作者使用饱和指数函数来建模性能增益 : 其中 是该域能提供的最大潜在提升, 决定了饱和速度。通过少量的初始实验(Pilot-runs),模型就能提前预知:在波士顿多采 100 组数据能涨多少分。
3. 迭代挖掘 (Iterative Mining)
基于拟合出的曲线,MOSAIC 采用贪心策略:每一轮迭代都计算每个域的“一阶差分”(即下一个样本的边际贡献),只从未采样的域中挑选当前贡献最大的那个。
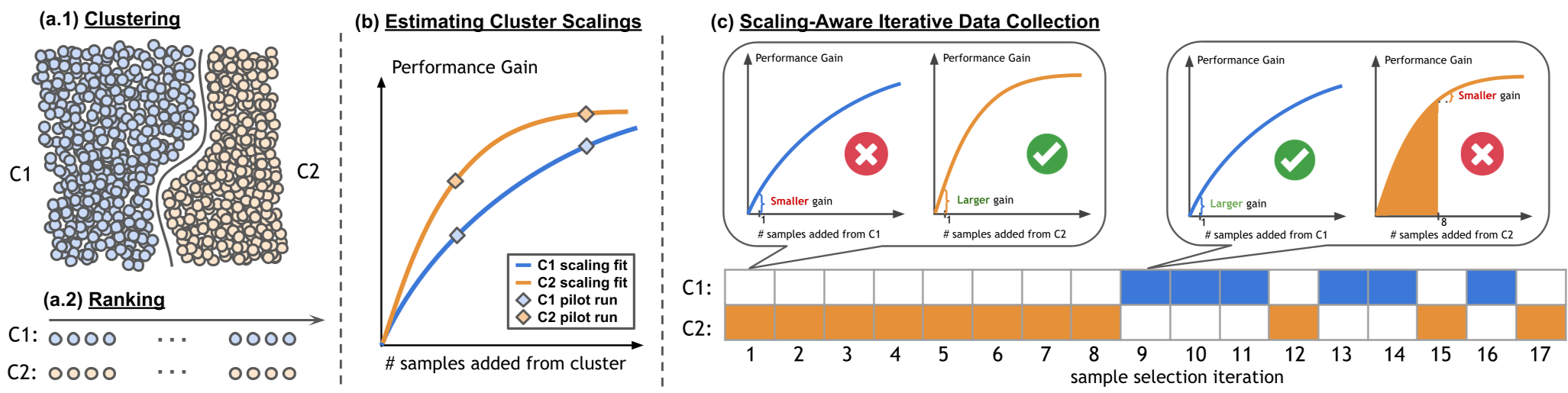 图 1:MOSAIC 流程:(a) 聚类排序 -> (b) 拟合缩放规律 -> (c) 迭代挖掘
图 1:MOSAIC 流程:(a) 聚类排序 -> (b) 拟合缩放规律 -> (c) 迭代挖掘
实验战绩
在 OpenScene 数据集上,MOSAIC 的表现极其强悍:
- 极高效率:在仅有 4000 个 clips 的预算下,MOSAIC 的 EPDMS 分数达到了 84.25,而随机采样仅为 80.38。
- 资源节省:为了达到相同的性能,MOSAIC 需要的 Budget Ratio (BRMR) 仅为 0.15-0.18。这意味着,别人训练 100 小时,你只需要 18 小时。
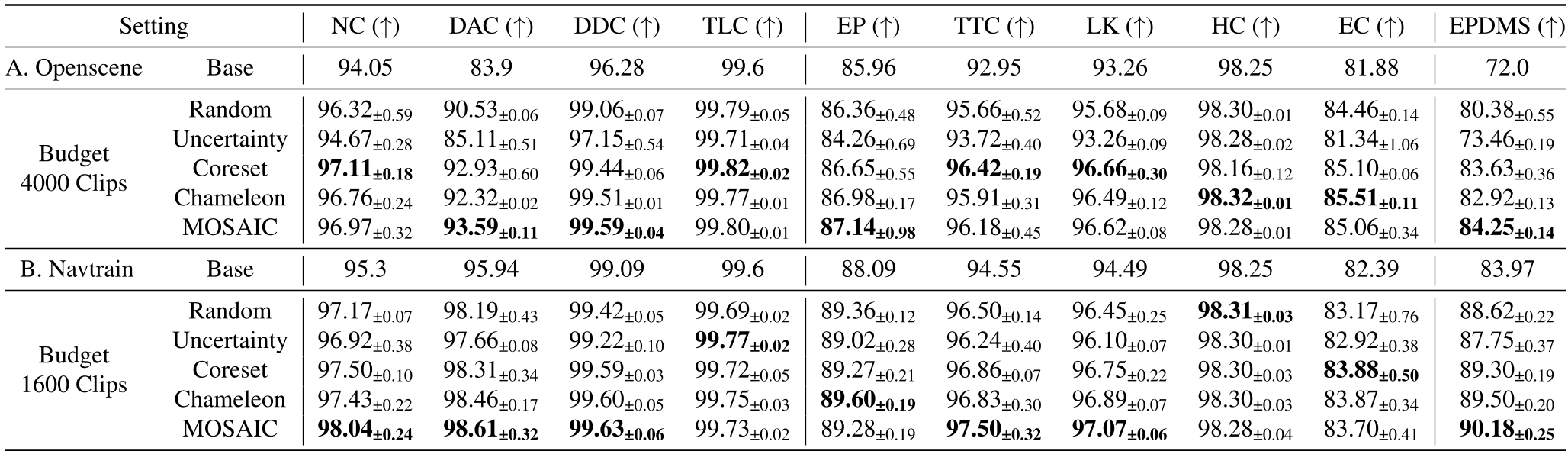 表 1:不同预算下各方法的指标分解。可以看到 MOSAIC 在 DAC(驾驶区合规)这一痛点指标上提升最明显。
表 1:不同预算下各方法的指标分解。可以看到 MOSAIC 在 DAC(驾驶区合规)这一痛点指标上提升最明显。
深度洞察:为什么它有效?
图 4 揭示了一个有趣的现象:在早期(低预算阶段),MOSAIC 疯狂挖掘波士顿和新加坡的数据,因为这两个城市的缩放曲线最陡峭(见图 3);而当这两处数据进入饱和期后,它才会转向增长更稳健的匹兹堡。这种“动态调配”能力是传统方法完全不具备的。
 图 2:随迭代次数增加,MOSAIC 在不同城市间的数据挖掘重心转移轨迹。
图 2:随迭代次数增加,MOSAIC 在不同城市间的数据挖掘重心转移轨迹。
总结与局限
Takeaway: 数据选择不需要“平均主义”。MOSAIC 通过建模“努力与回报的关系”,为物理 AI 系统的训练提供了一份精准的“投资指南”。
局限性:
- 前期投入:拟合 Scaling Laws 需要先跑一些 Pilot-runs。虽然文章证明这可以通过微调(Fine-tuning)快速实现,但仍有一定开销。
- 独立性假设:目前假设各域之间对性能的提升是线性可加的,忽略了复杂的跨域交互(如雨天的波士顿数据对阴天的伦敦是否有帮助)。
对于自动驾驶从业者而言,MOSAIC 的核心价值在于:它将昂贵的数据采集与评估过程,从“艺术”变成了“数学”。